数据集
数据集是机器学习和数据分析的基础,在问学中数据集是您训练自己专有大模型的基础。
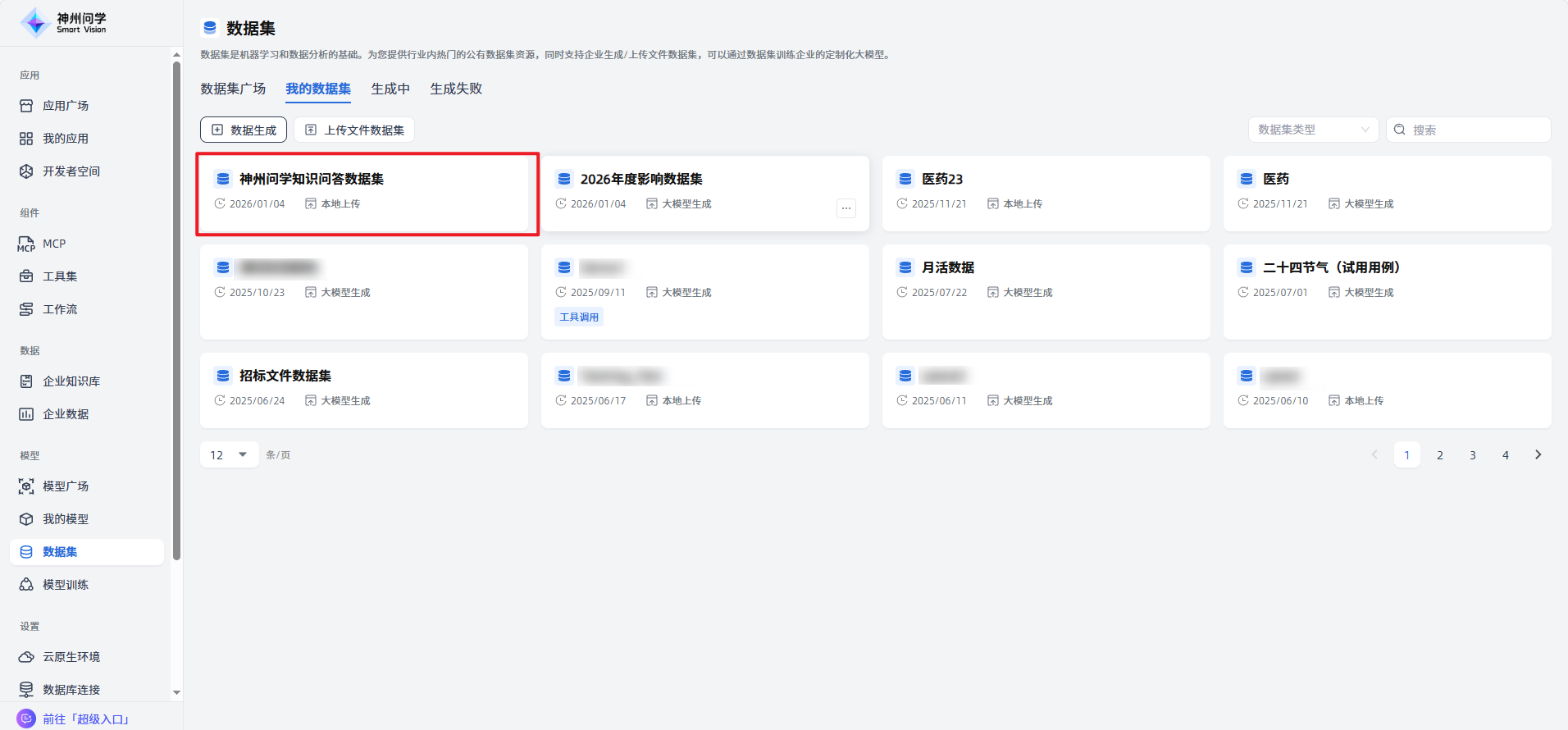
您可以使用数据集广场中的公有数据集,也可以在“我的数据集”中构建私有数据集(您可以通过两种方式创建私有数据集:①数据生成;②上传文件数据集),便于您通过数据集训练企业的定制化大模型。
数据集广场
数据集广场提供行业内热门的公有数据集资源,供您按需使用、训练您的私有模型。
数据生成
在“我的数据集”中,点击左上角“数据生成”按钮,您可以发起数据生成任务,用以生成您的大模型数据集,生成的大模型数据集可以用来训练或测评,让您的大模型快速掌握特定的知识和能力。
原理简介
数据生成,是通过大模型来生成样例数据。选择大模型后,大模型经过大量的训练数据学习,可以捕捉到数据集中的复杂模式和关系,从而生成更真实、准确的样例数据。
注意:大模型通常需要大量的训练数据来学习复杂的模式和知识,所以大模型的训练数据的数量和质量对生成的数据集有很大影响。此外,为了保证生成数据集的质量,还需要对生成的数据进行适当的评估和验证,以确保它们符合预期的标准和要求。
适用场景
- 标记数据不足: 当在某个特定领域或任务上缺乏足够的标记数据时,通过数据生成可以弥补数据不足的问题。
- 预训练模型可用: 如果有一个在大规模文本数据上进行了预训练的强大语言模型,可以利用其语言理解和生成能力,通过数据生成为特定任务生成合成数据。
- 样本多样性要求不高: 在一些任务中,样本的多样性要求相对较低,而模型的预训练能够提供足够的语言知识,这时使用数据生成的方法可能是有效的。
- 探索性研究或原型开发: 在进行探索性研究或原型开发阶段,通过数据生成可以帮助快速测试和验证模型的基本性能,而不需要花费大量时间和资源收集真实标记数据。
- 特定场景的数据需求: 对于一些特定场景,例如安全性测试、对抗性攻击、或者模型在边缘情况下的行为,通过数据生成可以有针对性地探测模型的鲁棒性。
操作指南

开始:进入“我的数据集”,点击左上角的“数据生成"按钮,进入”大模型数据集生成“页面。
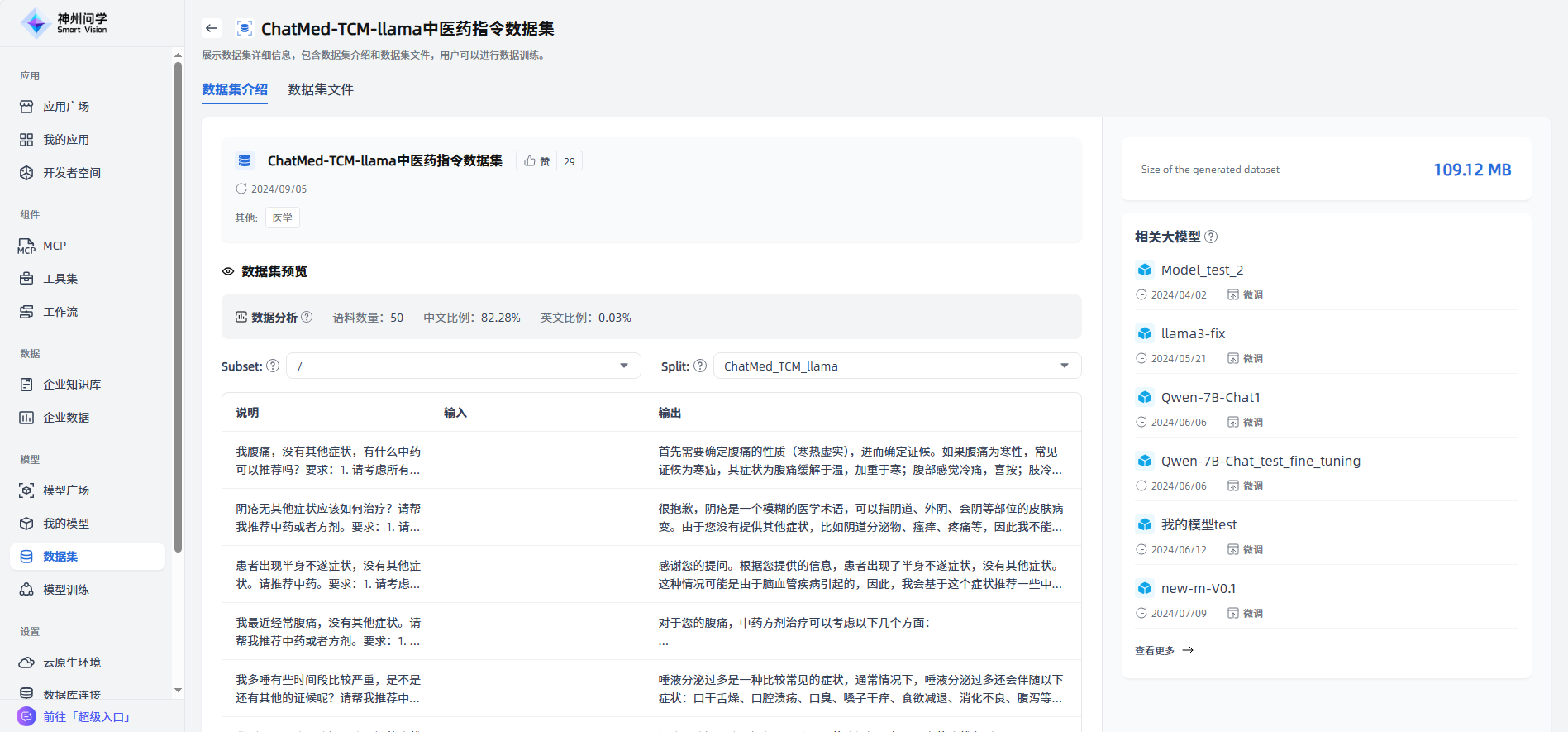
生成数据集样例:选择大模型,并配置要生成数据集的参数,点击”生成样例数据“按钮,生成数据集样例。
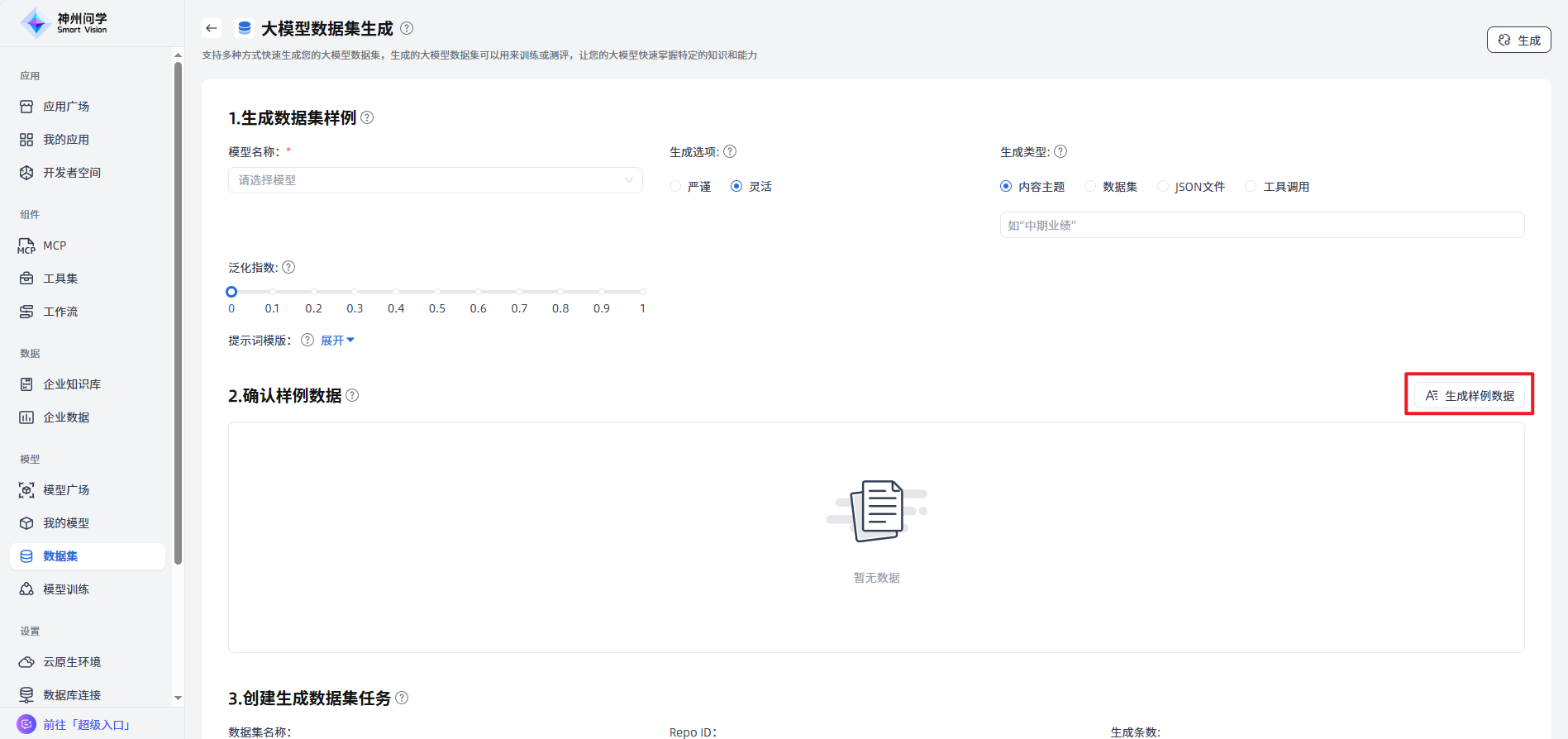
模型名称:不同的模型具有不同的架构、参数和训练方式,这决定了模型能够处理的数据类型和生成的数据集的特性。例如,有些模型可能更适合生成文本数据,而另一些模型可能更适合处理图像或音频数据。
生成选项:数据集可以是严谨,也可以是灵活的,这取决于所需的应用场景和目标受众。生成选项的选择将影响数据集的风格、格式和约束条件等,以及模型的生成能力和灵活性。
生成类型:目前支持四种方式,内容主题、数据集、JSON文件、工具调用。
- 内容主题:数据集样例应围绕一个明确的主题或领域生成,这有助于确保生成的数据集具有一致性和相关性。内容主题的选择将直接影响数据集的内容和用途,例如,如果主题是劳动法,则数据集将包含与法律相关的文本和数据。
数据集:生成的数据集样例基于上传数据集进行展开,生成的样例会更加精准。模型会对上传的数据集进行分析,了解数据集的结构、特征和数据类型等。详细的格式和内容会使生成的数据集贴近上传的数据集。
- JSON文件:生成的数据集样例基于您上传的JSON文件(JSON文件内容格式创建要求:以键值对的方式创建内容,默认有三个元素instruction、input、output)进行复制、修改和合成。
- 工具调用:数据集样例基于您选择的内部工具或工作流、及目标数据集类型而生成。支持三种目标数据集类型:simple(工具列表中仅包含单个内部工具/工作流,针对用户提问模型会调用一次工具/)、multiple(工具列表中包含多个内部工具/工作流,针对用户提问模型会调用多次工具)、irrelevance(用户的提问与工具列表中所有工具无关,模型不会调用任何工具),通常建议您同时选择三种类型(即平台默认选项),以保障数据集的多样性。
泛化指数:泛化能力是指模型在未见过的数据上表现的能力。泛化指数可以衡量数据集的质量和多样性,以及模型对新数据的适应能力。高泛化指数通常意味着数据集具有更好的通用性和可扩展性,能够支持更广泛的应用场景。
确认样例数据:确认生成的样例数据是否符合需求,如不符合,可调整生成数据集样例中的模型或参数。
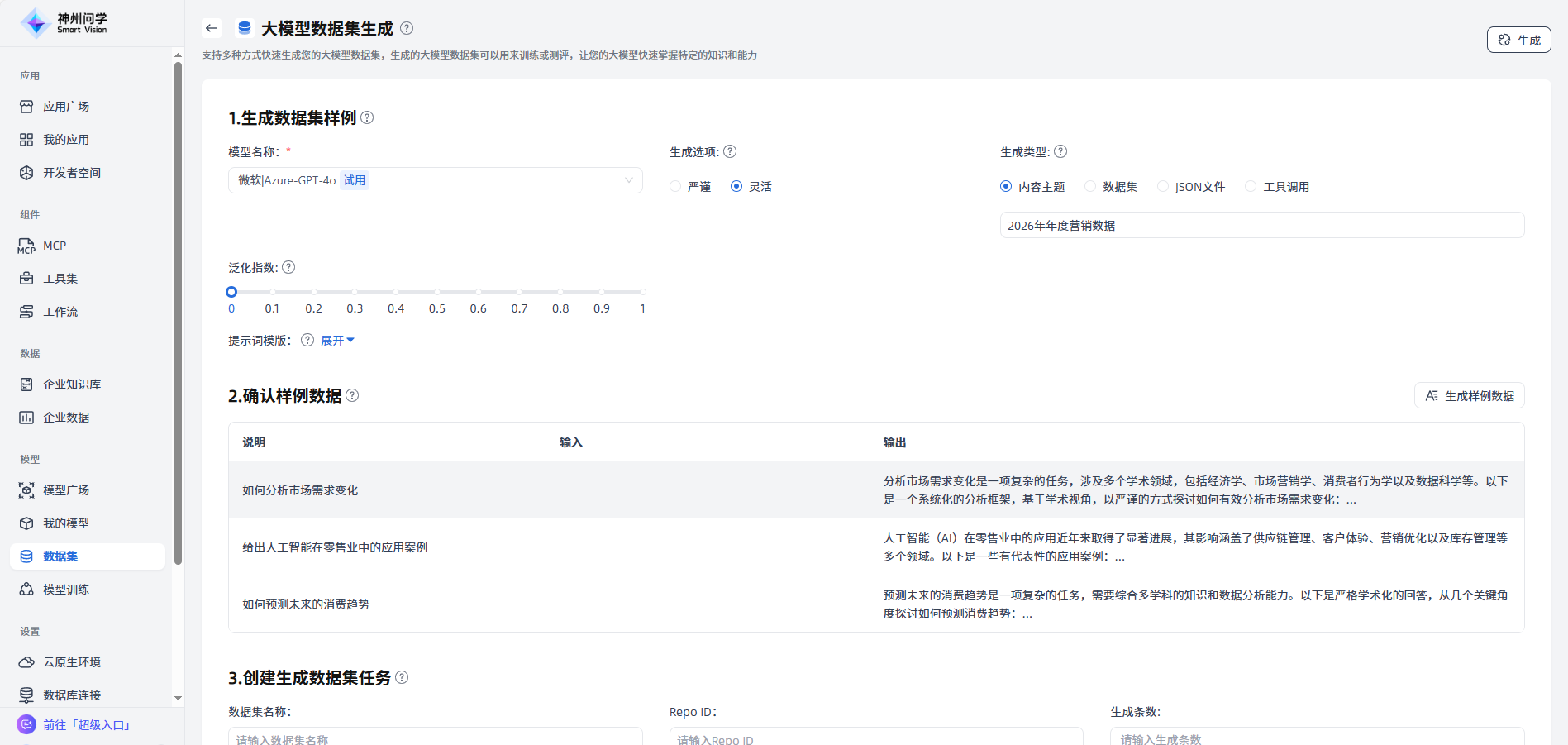
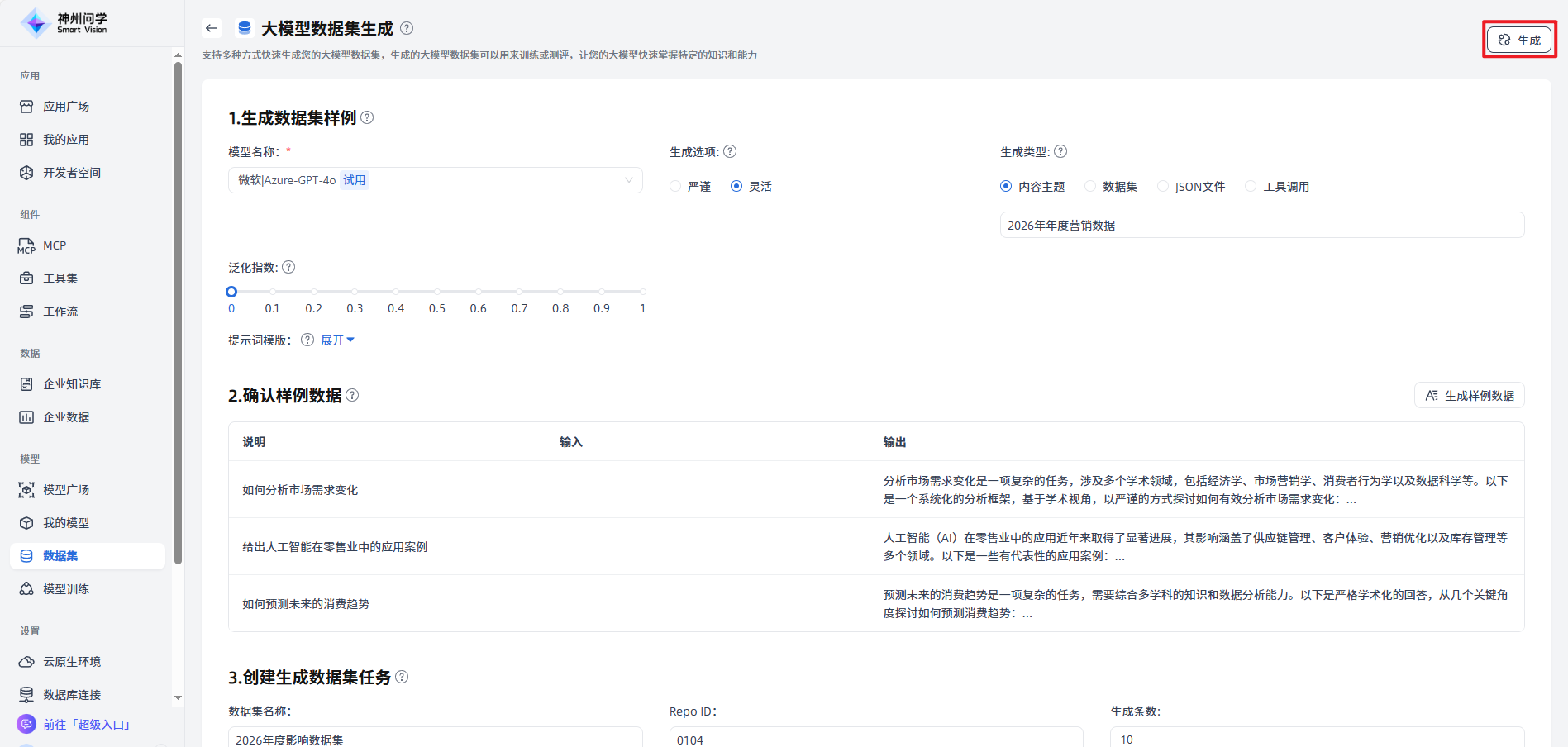
创建生成数据集任务:确认数据集样例符合您的需求后,填写数据集名称、生成条数等,点击右上角”生成“按钮,创建生成数据集任务。
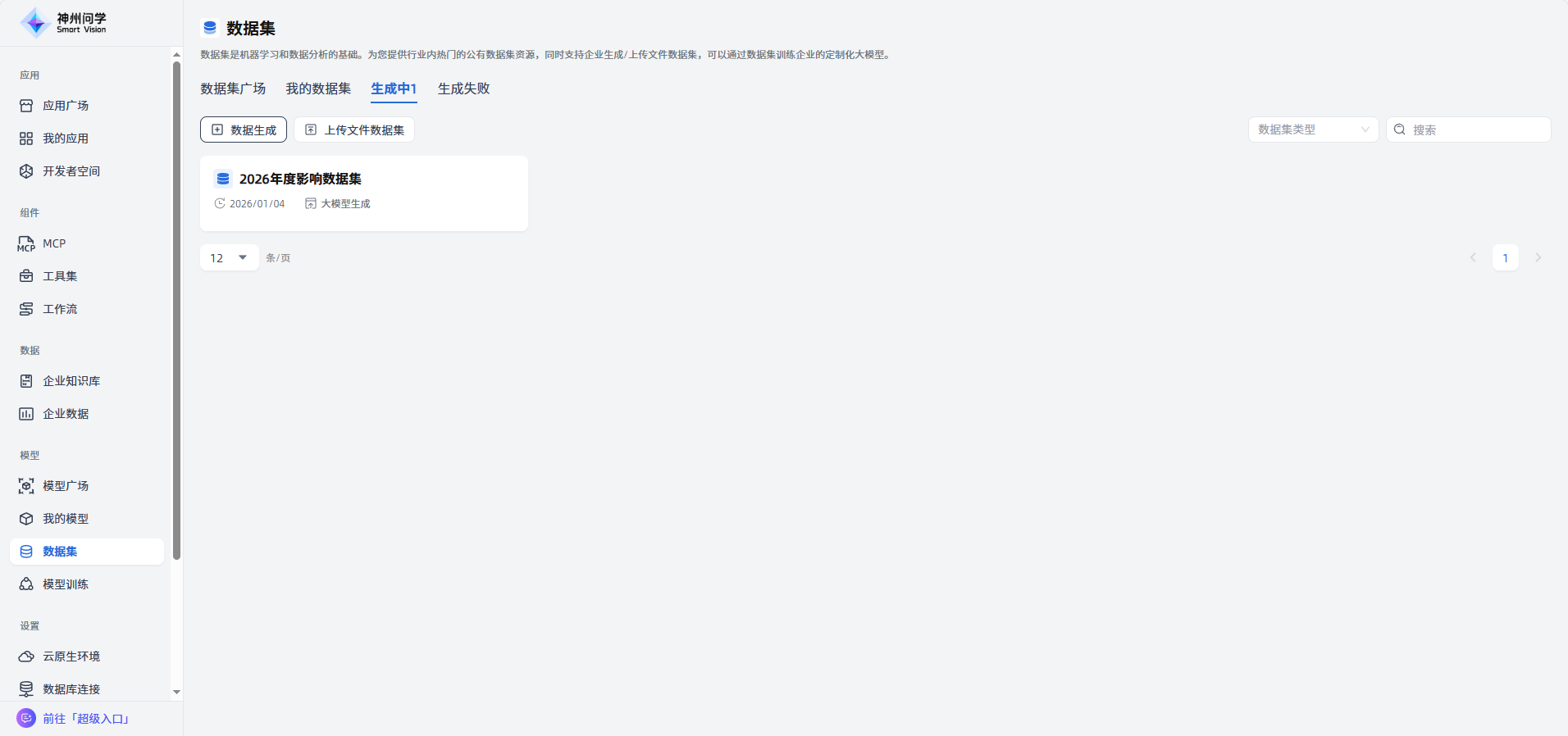
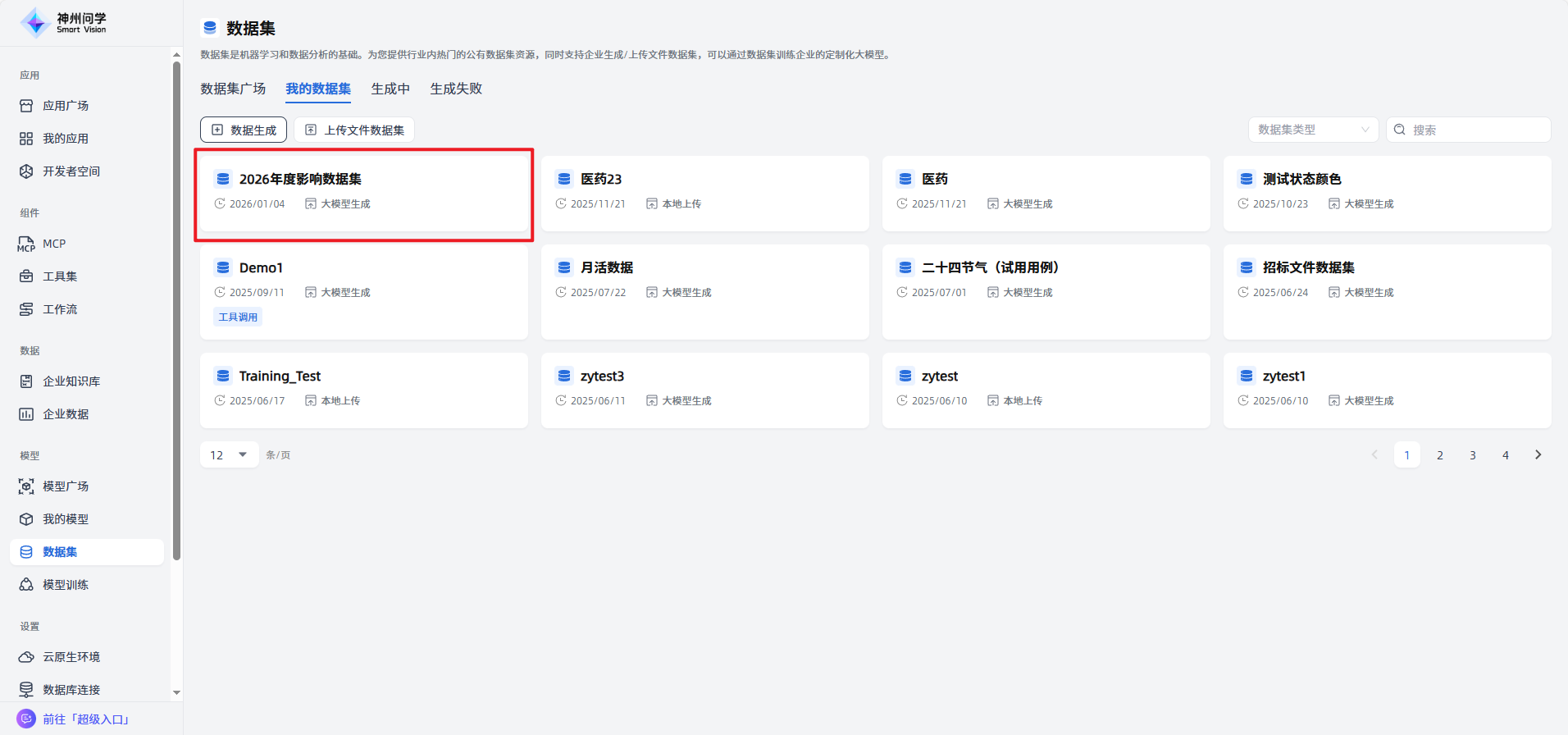
完成:不同状态的数据集在相应Tab展示。
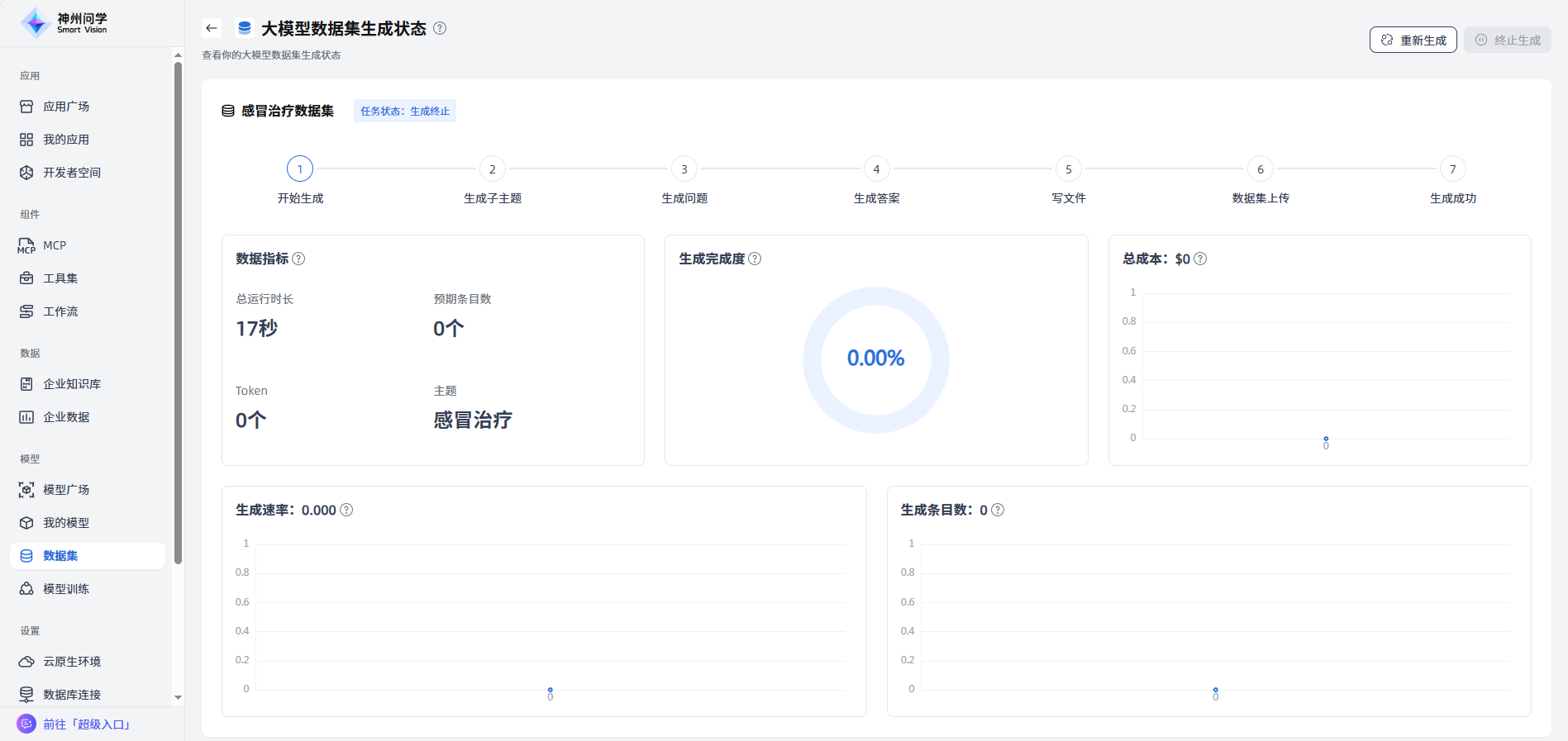
生成中:生成过程中的数据集将在”生成中“展示,点击可以查看该任务的进度详情,也可以点击“终止生成”一键终止任务。
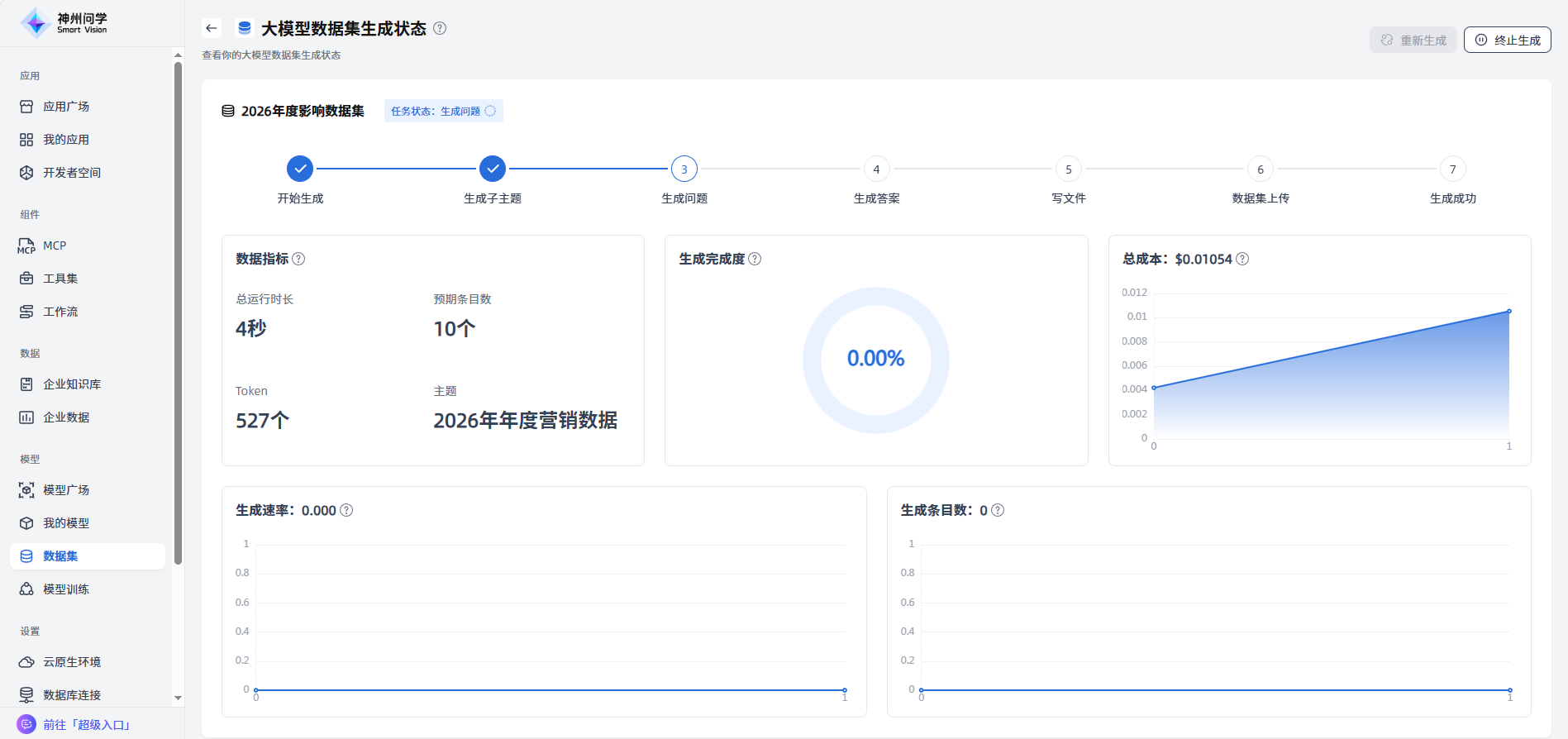
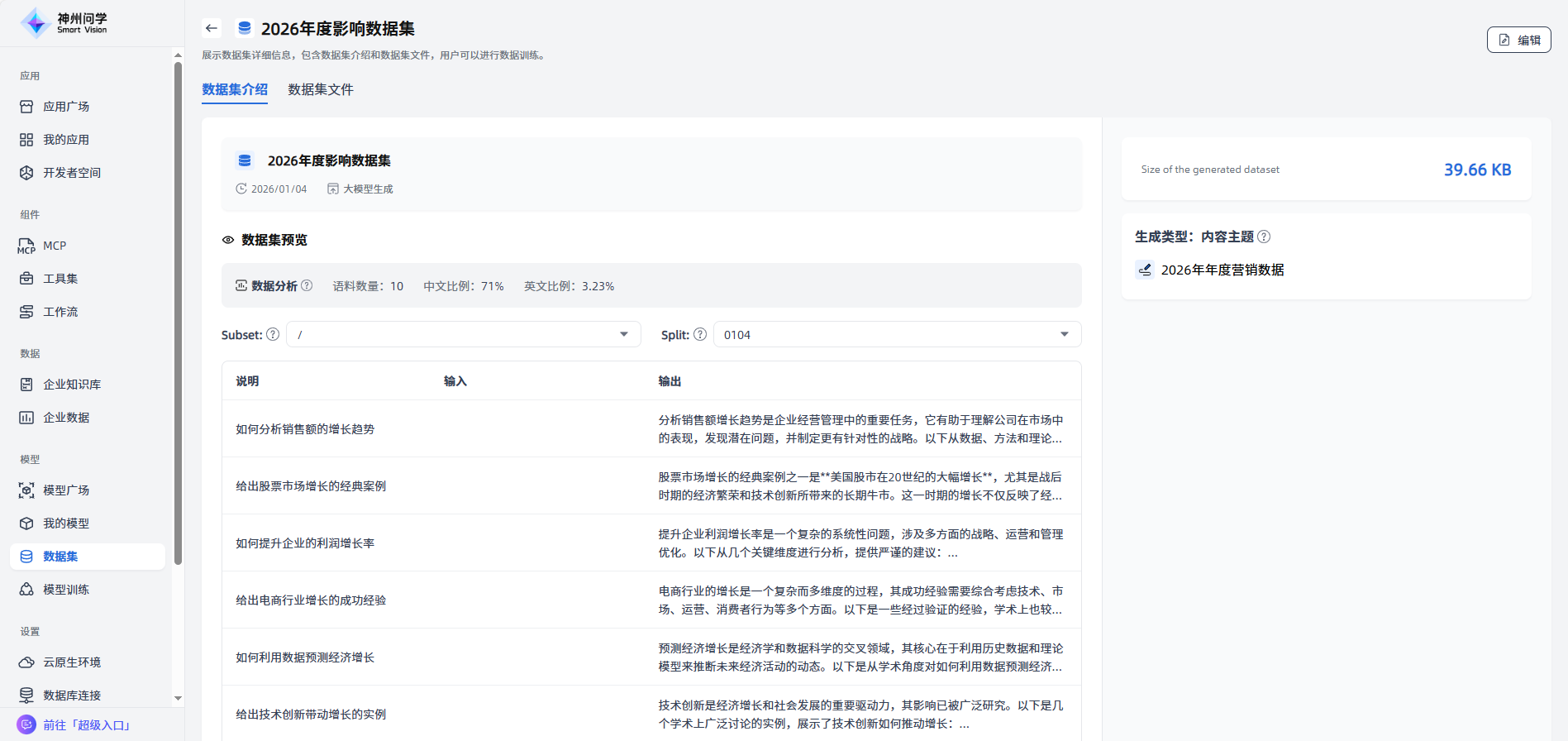
生成成功:生成完成的数据集会在”我的数据集“展示,点击可以查看该数据集的详情。
生成失败:生成失败的数据集在“生成失败”中展示,点击可以查看详情,并可以点击“重新生成”一键重启生成任务。
在“我的数据集”中,点击左上角“上传文件数据集”按钮,您可以导入数据集,可以用来训练或测评,让您的大模型快速掌握特定的知识和能力。
原理简介
上传文件数据集的原理,涉及数据传输、接收、解析、存储和提供访问接口:
数据准备: 您需要有一个数据集,并检查数据集的大小和格式是否符合平台的要求(目前问学支持上传txt、JSON格式的文件,文件大小不能超过100M),确保您的数据集已经按照所需的格式进行了适当的组织和预处理;确保您有权上传和使用该数据集,如果您使用的是他人的数据集,请确保您已经获得了适当的许可或授权;确保网络连接稳定,以避免在上传过程中出现中断或错误;在上传之前,最好备份原始数据集,以防上传过程中出现问题。
数据传输-接收-解析-存储: 通过上传功能将数据集上传到问学平台-我的数据集后,问学平台会接收到上传的文件,并对不同类型的文件进行相应的解析处理后,将数据集文件存储至问学平台,以供模型训练时使用。
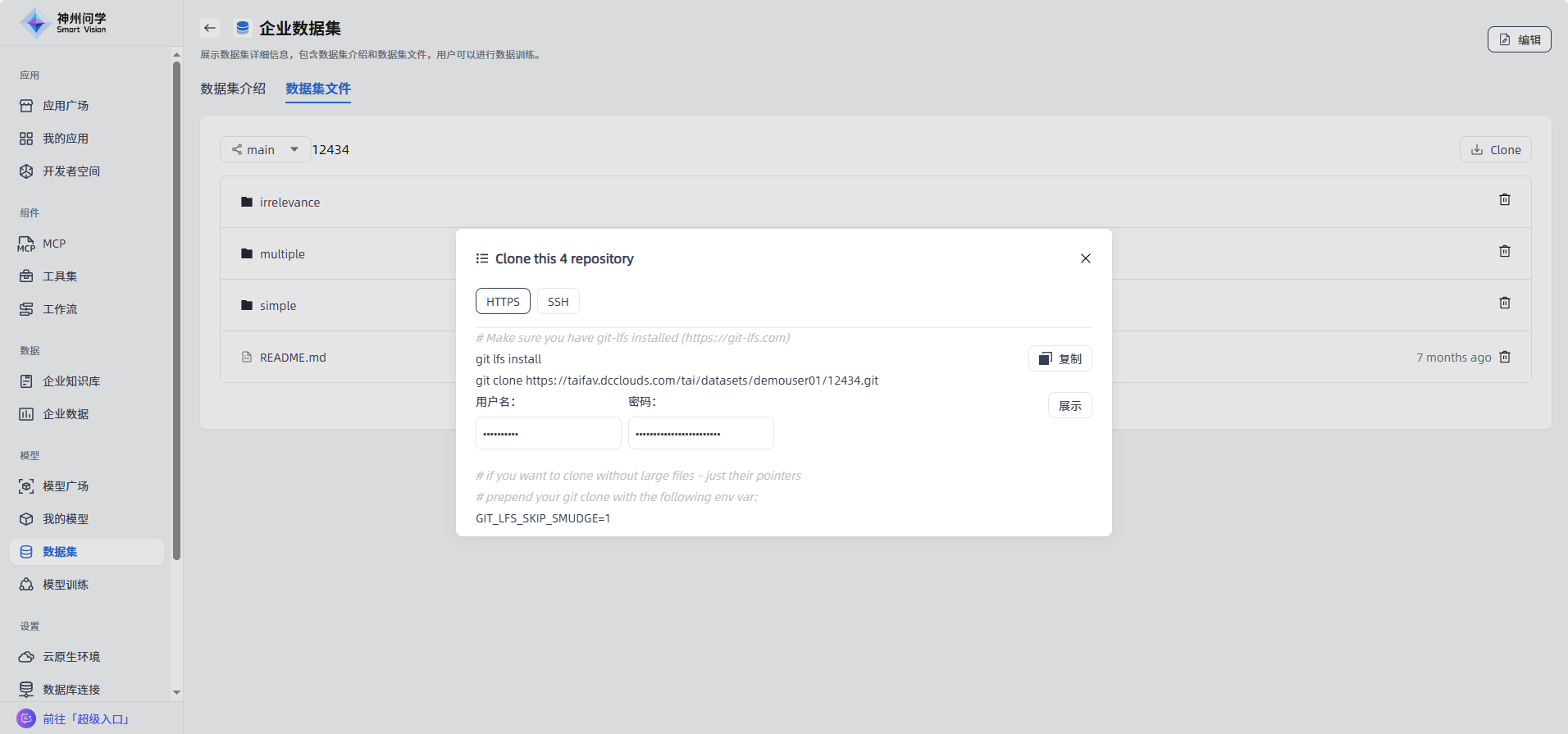
提供访问接口: 对于上传成功的数据集,问学提供访问接口,便于用户通过应用程序或网络访问上传的数据集(点击上传成功的数据集,进入数据集详情-数据集文件,点击右边的”Clone“按钮,查看HTTPS或SSH方式的访问路径)。
适用场景
- 合作研究:在合作研究中,多个研究团队或机构可能需要共享和使用相同的数据集。通过上传文件数据集,不同团队或机构之间可以方便地共享和使用相同的数据集,提升合作研究和数据分析的效率。
- 数据隐私保护:在某些情况下,由于数据隐私或敏感信息的限制,不便将数据集直接分享给其他人。通过上传文件数据集,用户可以将数据集上传到问学平台上,将访问方式只分享给需要使用的人,从而保障数据安全。
操作指南

开始:进入“模型-数据集-我的数据集”,点击左上角的“上传文件数据集"按钮,进入”上传“弹窗页面。
填写数据集信息:填写数据集标题、描述等信息。
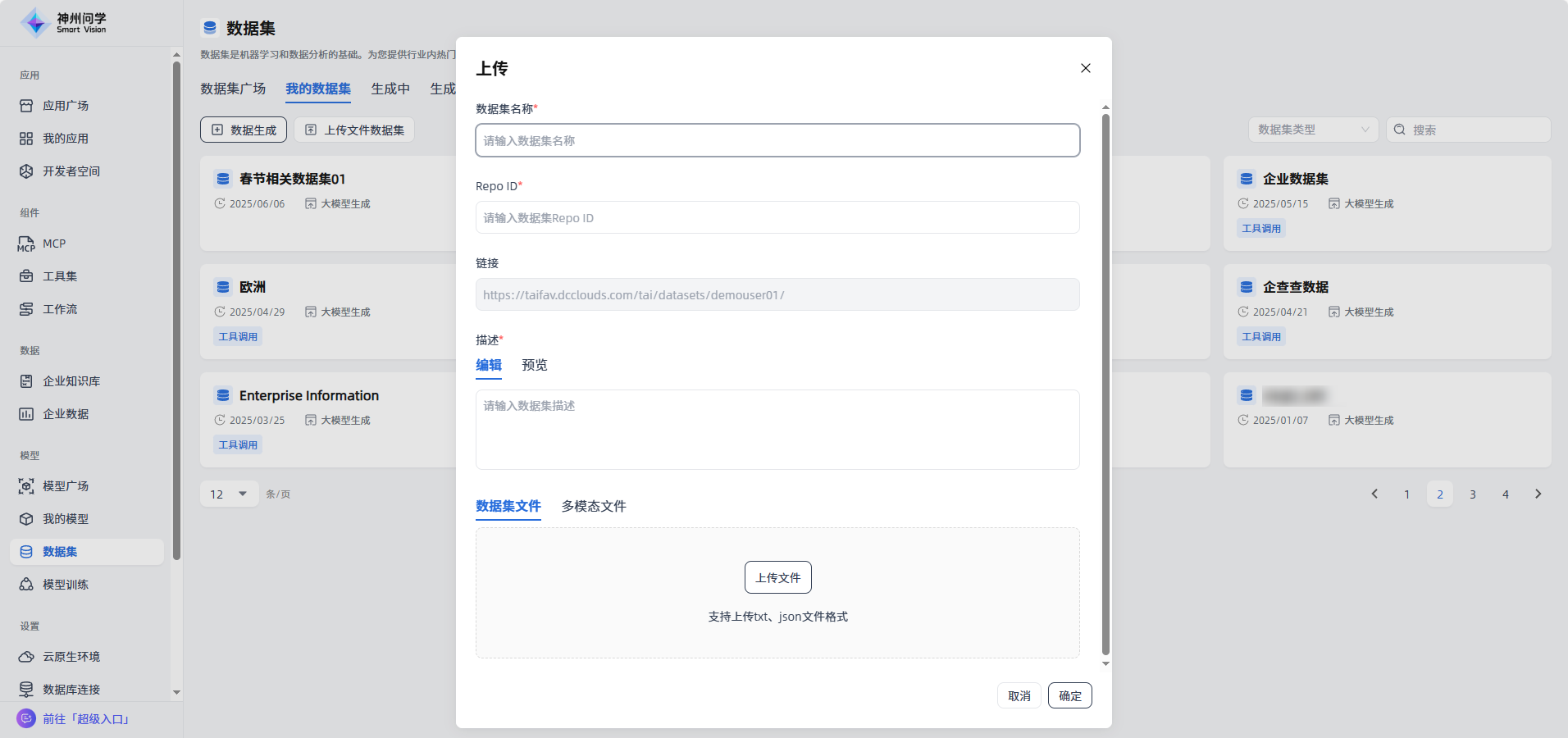
上传数据集文件:上传事先准备好的数据集文件,上传成功后点击右下角”确定“按钮。
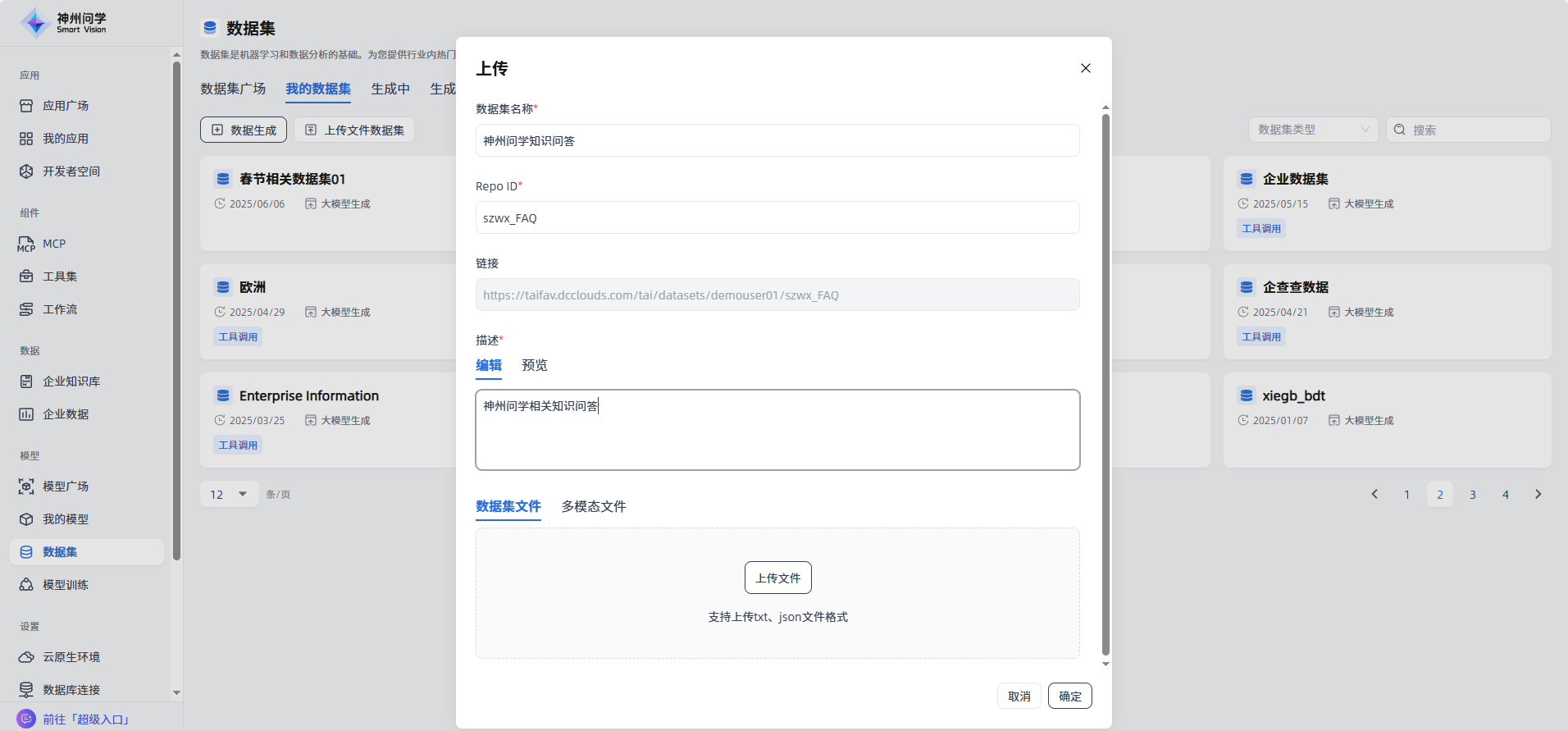
完成:点击”确定“按钮后,上传的数据集将在”我的数据集“展示。