工作流管理
简介
工作流通过将复杂任务分解为更小的步骤(节点)来降低系统复杂性,减少对提示工程和模型推理功能的依赖,提高 LLM 应用程序在执行复杂任务时的性能。不仅实现了自动化和批处理场景中的复杂业务逻辑的流程化,也提高了系统的可解释性、稳定性和容错能力。
节点是工作流的关键组件,通过连接具有不同功能的节点,可以执行工作流的一系列操作。
变量用于连接工作流中前后节点的输入与输出,从而实现整个过程中的复杂处理逻辑。为避免变量名称冲突,节点命名必须是唯一的、不能重复。
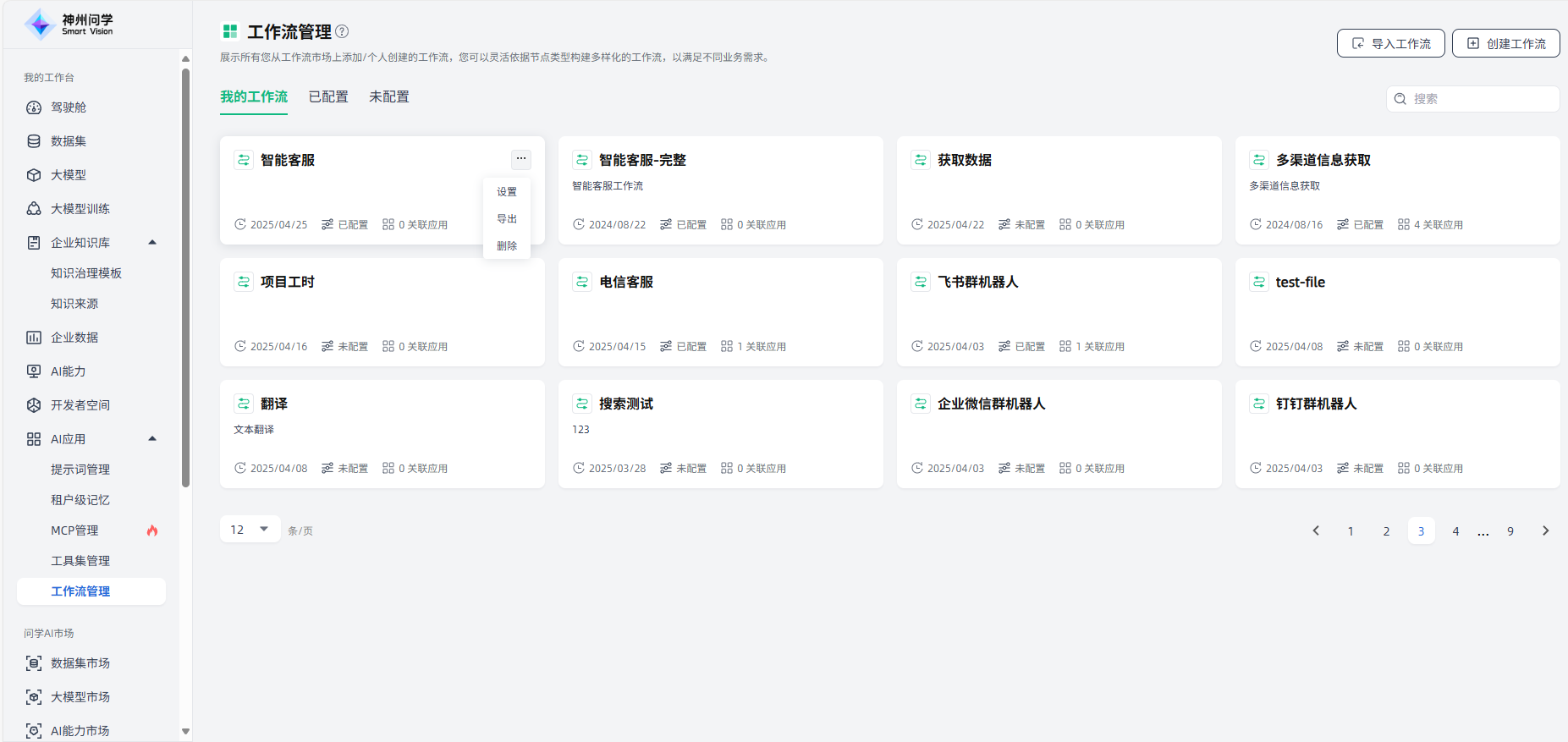
我的工作台-AI应用-工作流管理,展示所有您从工作流市场上添加的(工作流市场即将上线)、以及个人创建的工作流,及其配置状态、关联应用数量。点击某个工作流右上角的“···”,可以对该工作流进行设置、删除等操作。点击右上角的“创建工作流”或“导入工作流”按钮,可以创建您的私有工作流。
节点
开始
开始节点是工作流的启动节点,每个工作流都需要一个开始节点。创建工作流后,会自动出现开始节点。
在开始节点,您需要定义用于启动工作流的输入变量,点击“+”选择合适的变量类型、进行变量添加。
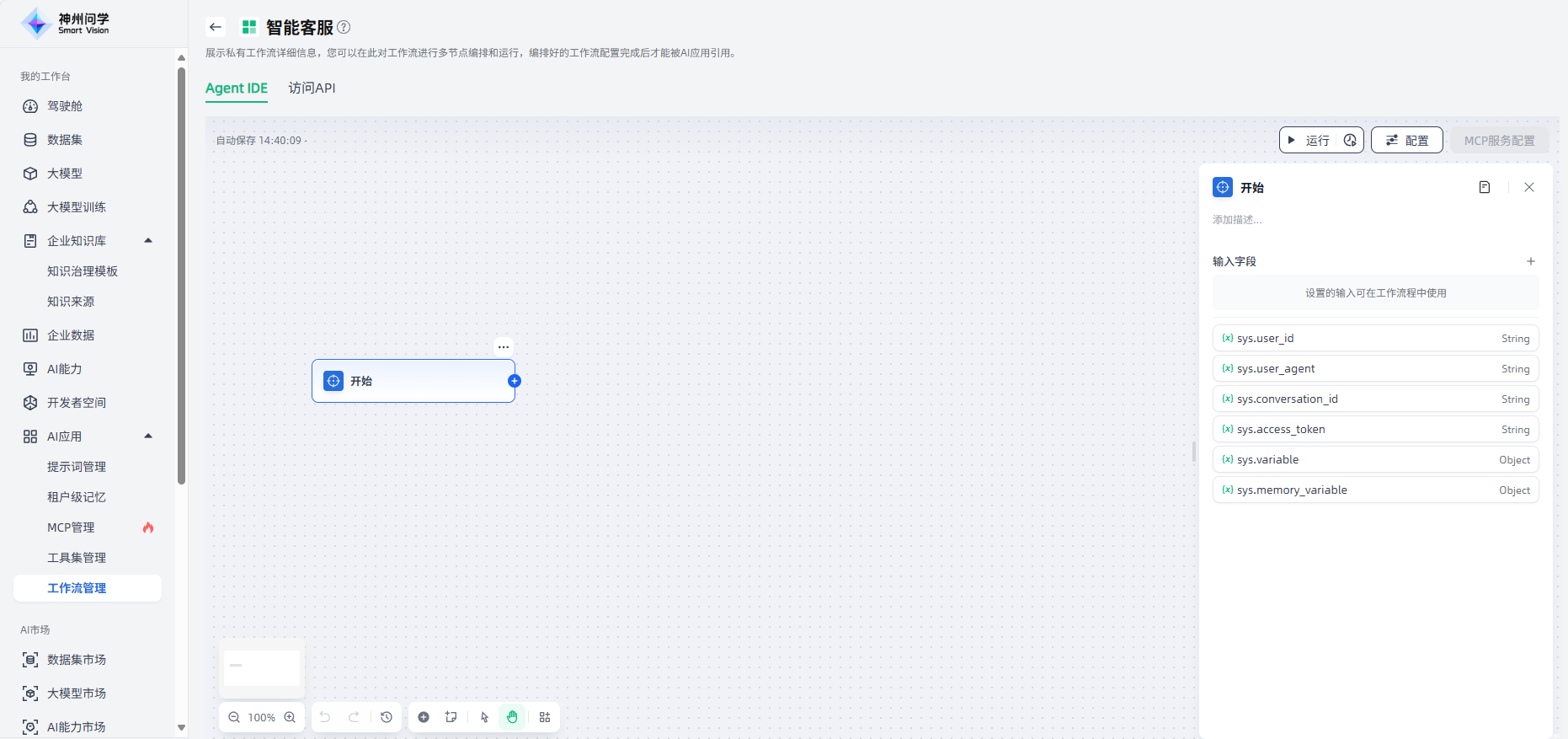
开始节点支持定义六种类型的输入变量:文本、段落、下拉选项、数字、单文件、文件列表。
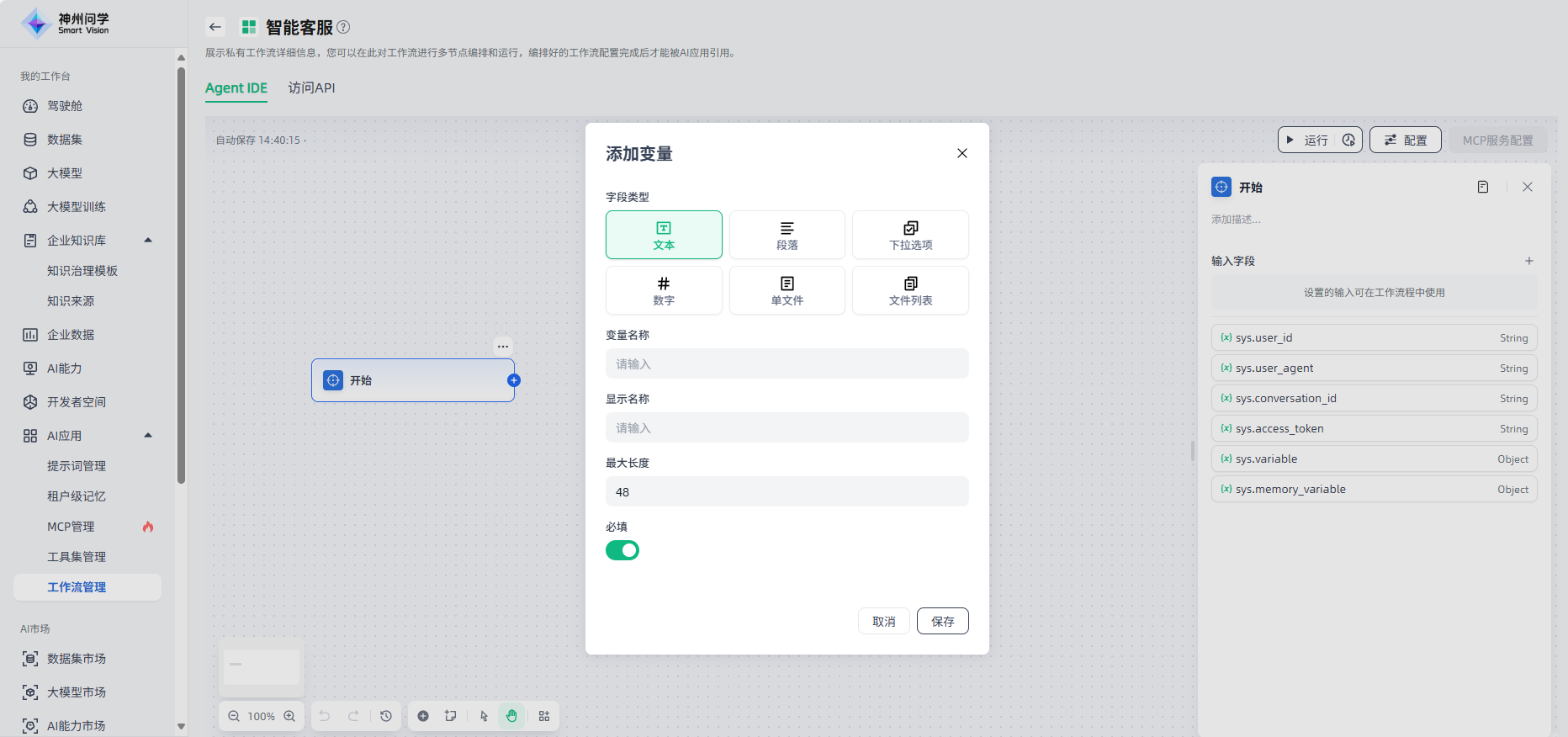
文本:可以按需设置变量名称、显示名称、最大长度、是否非必填。
段落:可以按需设置变量名称、显示名称、最大长度、是否非必填。
下拉选项:可以按需设置变量名称、显示名称、可选项、是否非必填。
数字:可以按需设置变量名称、显示名称、是否非必填。
单文件:支持上传本地文件(文档、图片、音频、视频)或URL,并按需设置变量名称、显示名称、是否非必填。
文件列表:支持上传文件列表,并按需设置变量名称、显示名称、最大上传文件数、是否非必填。
输入变量配置完成后,工作流在执行时将提示您输入开始节点中定义的变量值。
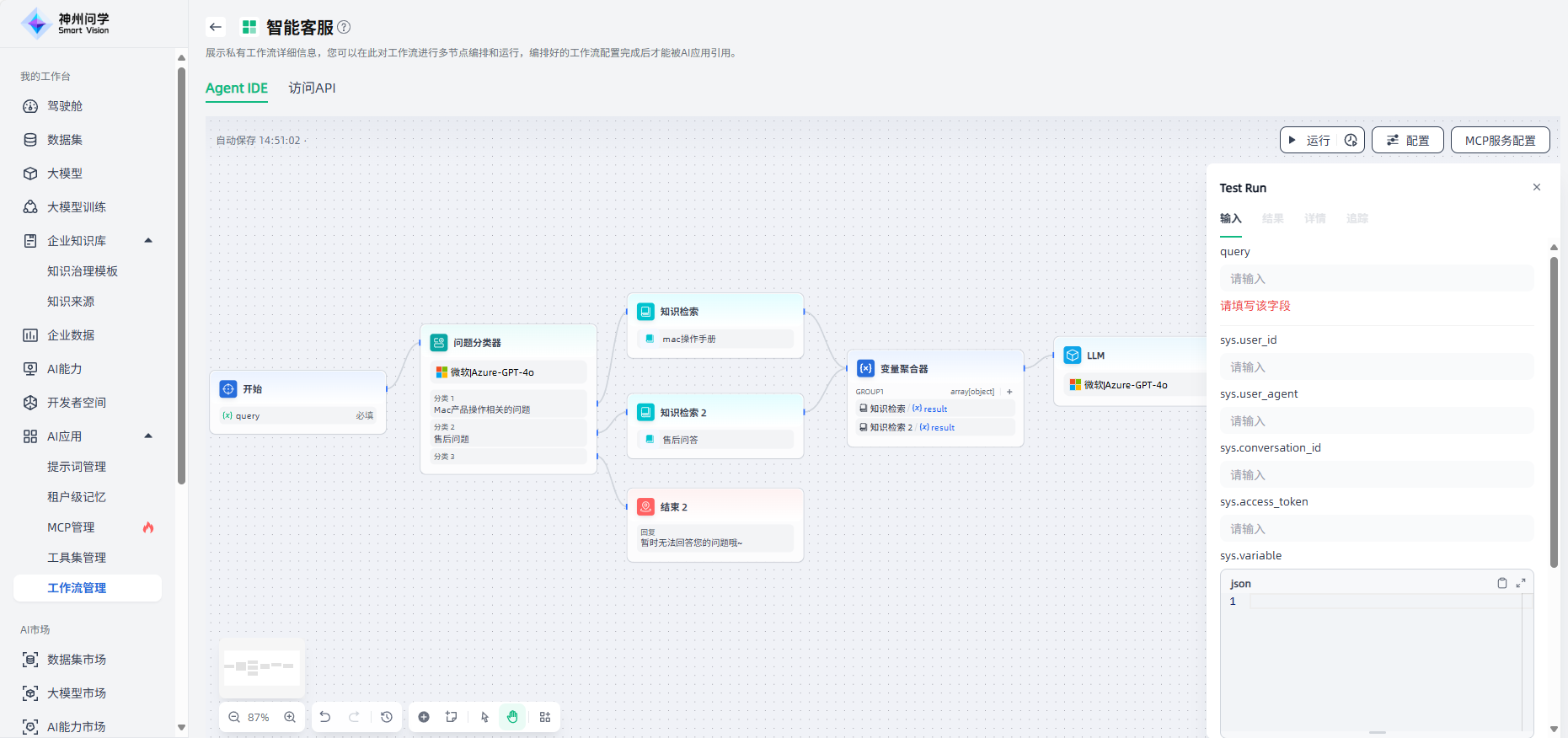
结束
在工作流中,只有运行到结束节点时才会输出执行结果。结束节点是工作流程的终止节点,结束节点后面无法再添加其他节点。
结束节点用于定义工作流的最终输出内容,每个工作流在完成执行后都需要至少一个结束节点,用于输出最终结果。如果流程中存在多个分支,则需要定义多个结束节点。
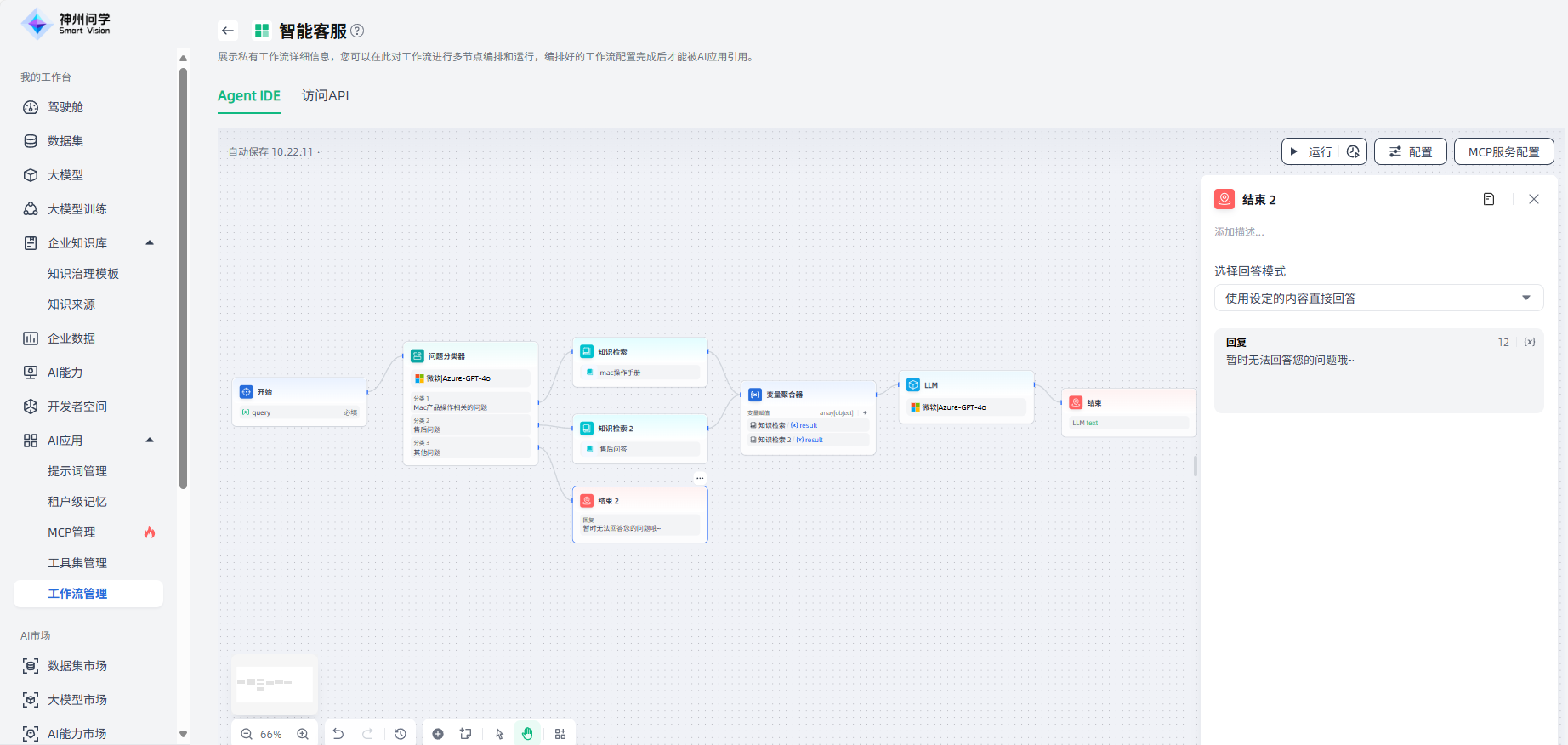
结束节点提供了2种回答模式:①返回变量,由大模型生成回答;②使用设定的内容直接回答。
返回变量,由大模型生成回答:需要声明一个或多个输出变量(点击“+”),这些变量可以引用任何上游节点的输出变量。
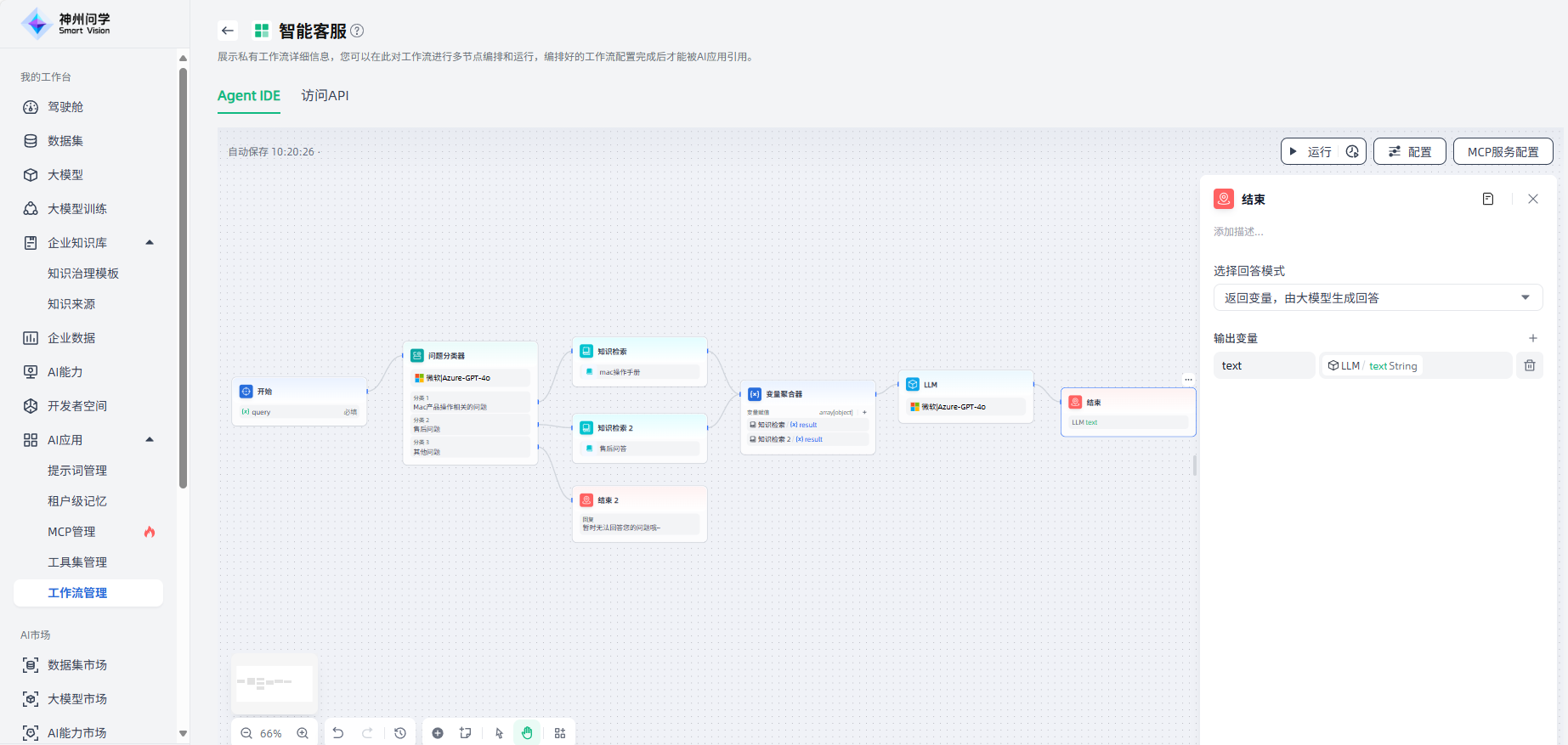
使用设定的内容直接回答:自定义设置输出内容,内容中支持插入变量、内容块。
LLM
LLM节点是工作流的核心节点,用于调用大型语言模型来回答问题或者处理自然语言。
利用大型语言模型的对话/生成/分类/处理等能力,根据给定的提示处理广泛的任务,可用于工作流的不同阶段,如:
- 文本生成:在内容创建场景中,根据主题和关键词生成相关文本。
- 内容分类:在邮件批量处理场景中,自动对邮件进行分类,如查询/投诉/垃圾邮件等。
- 代码生成:在编程辅助场景中,根据用户需求生成特定的业务代码或编写测试用例。
- RAG:在知识库问答场景中,重新组织检索到的相关知识以响应用户问题。
- 图像理解:使用具有视觉功能的多模态模型来理解和回答有关图像中信息的问题。
LLM节点的配置步骤如下:
1.选择模型:使用LLM节点,需要根据场景需求和任务类型选择合适的模型(可选择的模型对应工作台-大模型-已部署中的模型),并进行参数设置。
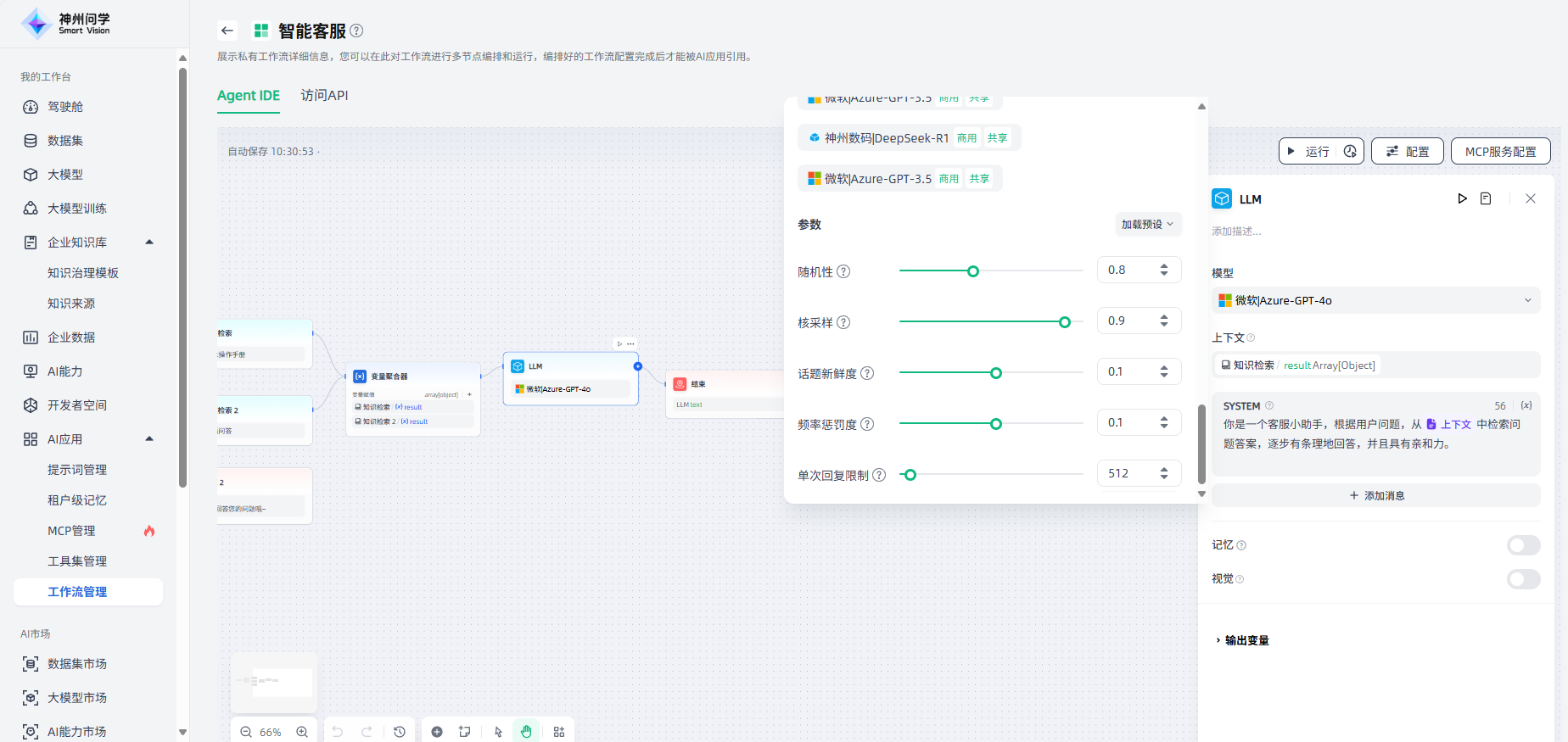
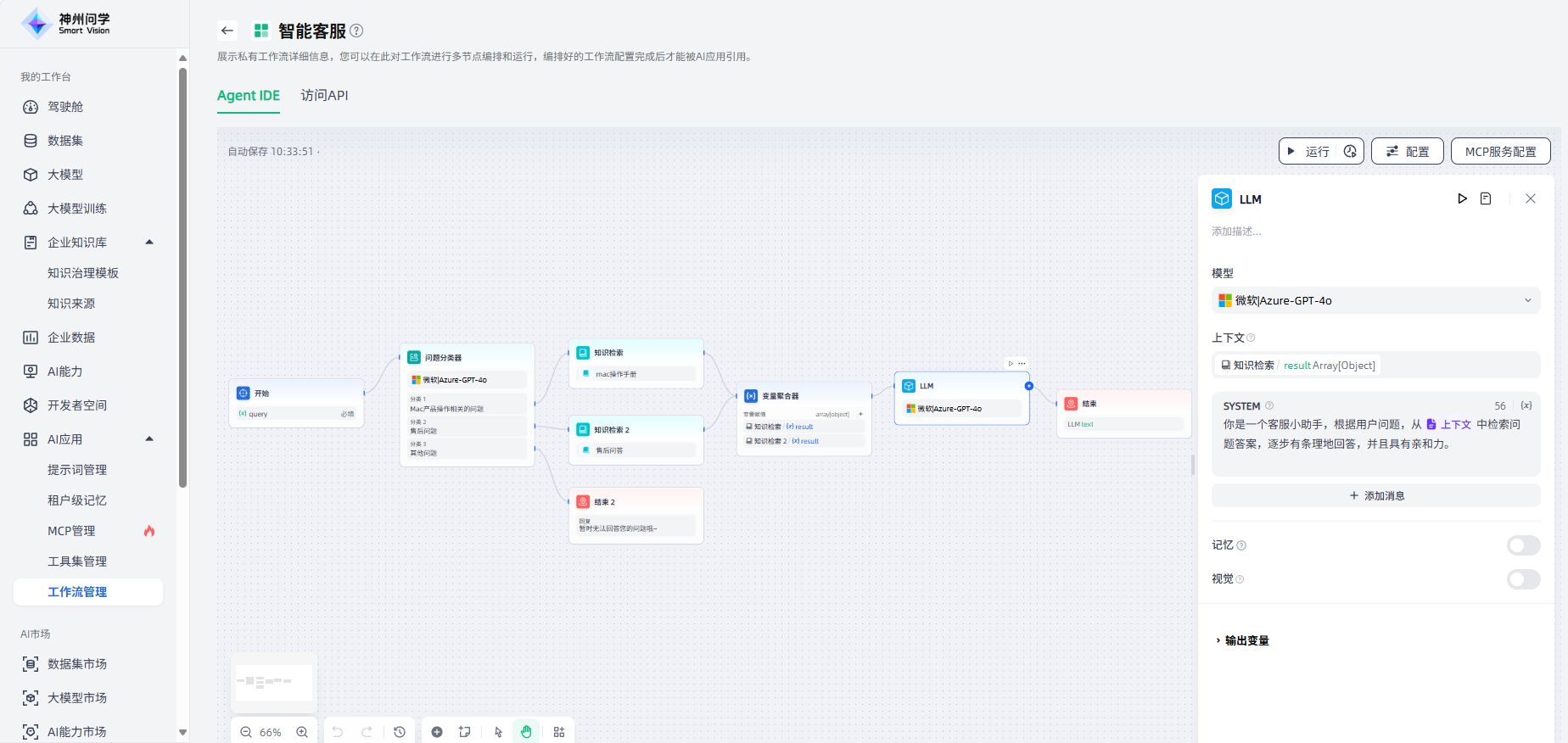
2.上下文变量:上下文变量是LLM节点中定义的一种特殊类型的变量,您可以根据场景需求选择合适的变量作为上下文,便于将外部检索的文本内容插入到提示词中。以知识库问答场景为例,知识检索的下游节点通常是LLM节点,知识检索的输出变量需要在LLM节点内的上下文变量中进行配置,以便进行关联和赋值;关联后,在提示词的适当位置插入上下文变量,可以将检索到的知识合并到提示词中。
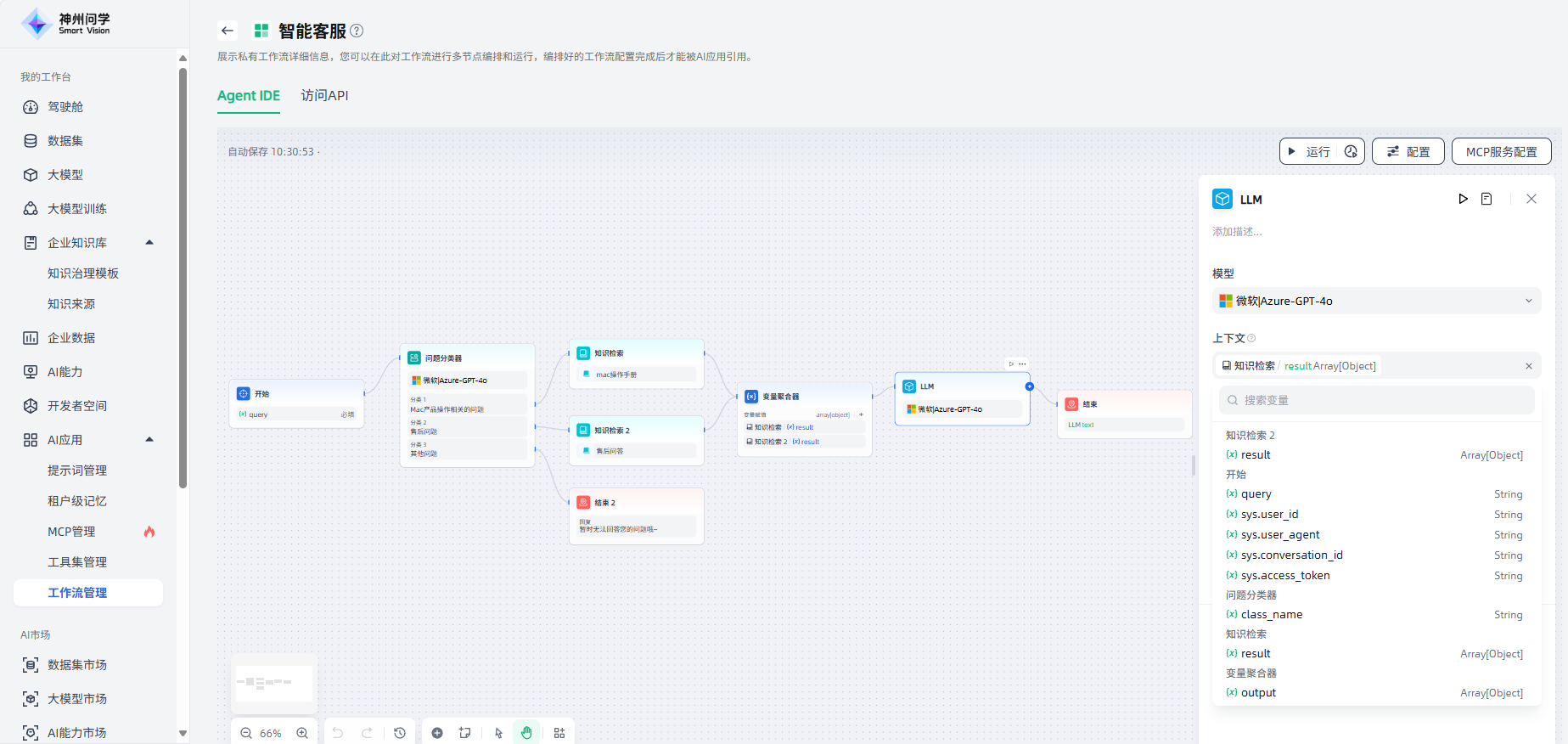
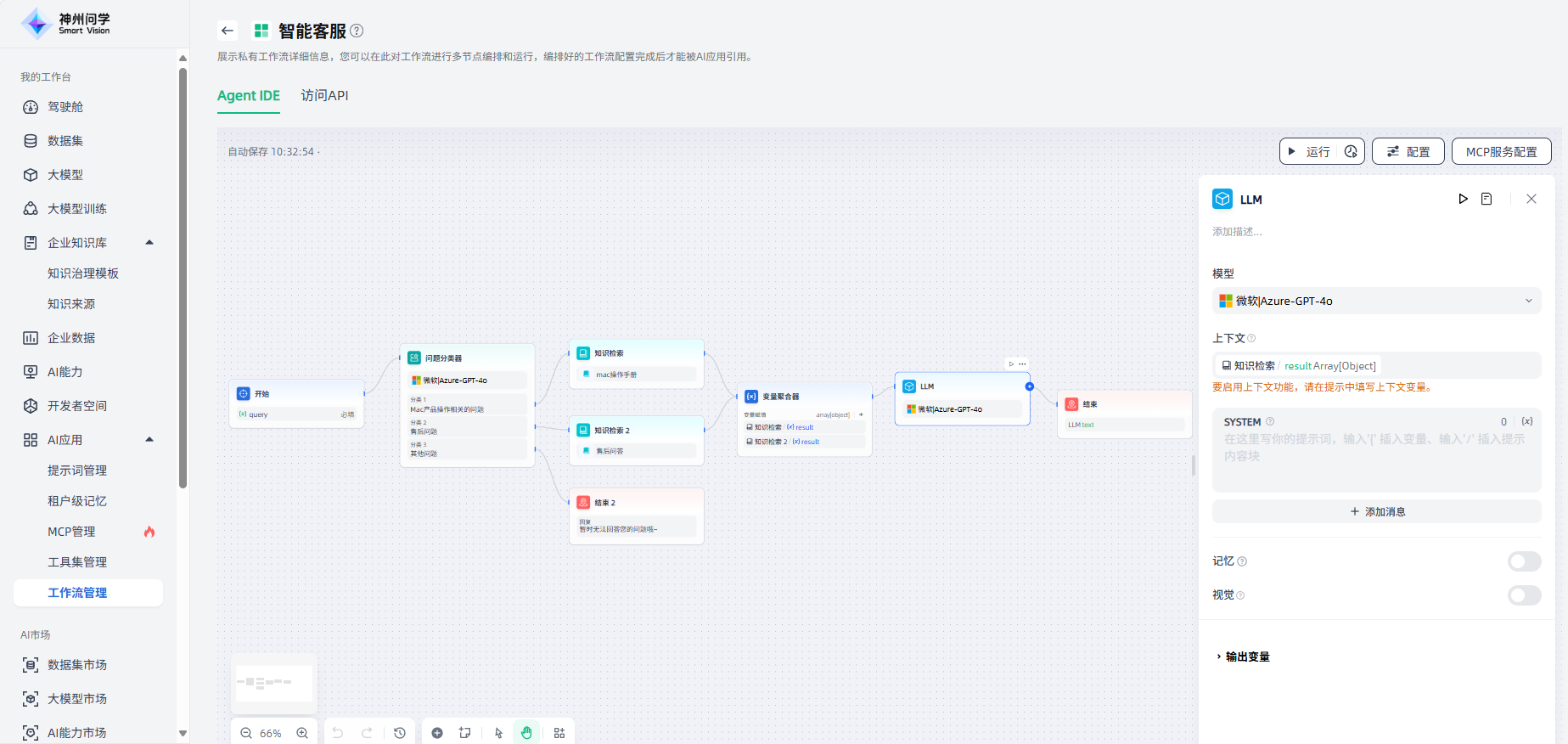
3.提示词编辑:在 LLM 节点中,您可以自定义模型输入提示。在提示词编辑器中,您可以通过输入“/”或“{”来调出变量插入菜单,将特殊变量块或上游节点变量作为上下文内容插入到提示中。
知识检索
知识检索节点用于从企业知识库中查询与问题相关的文本内容,可以将其用作大型语言模型后续答案的上下文。
知识检索节点的配置步骤如下:
1.查询变量:在知识库检索场景中,查询变量通常表示用户的输入问题。
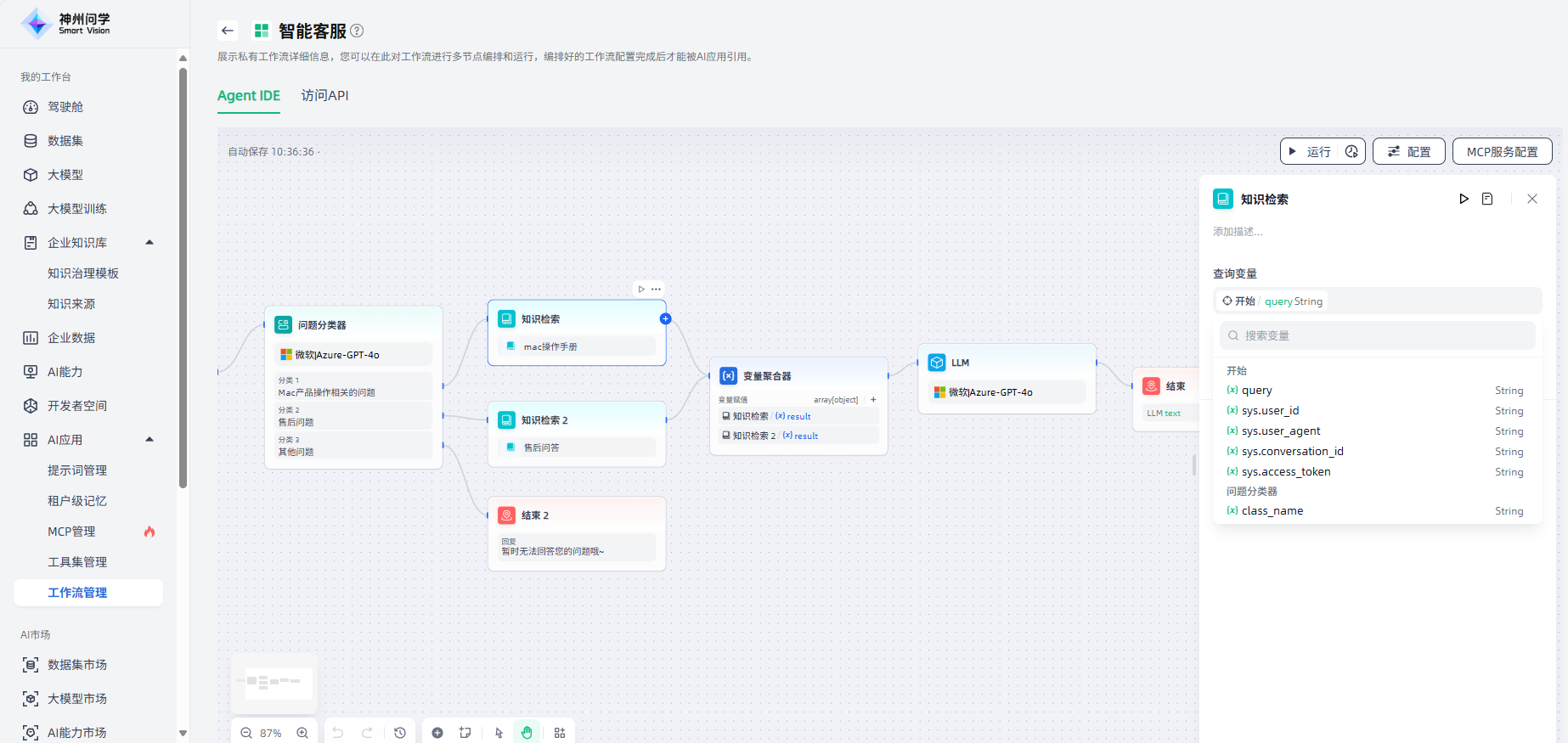
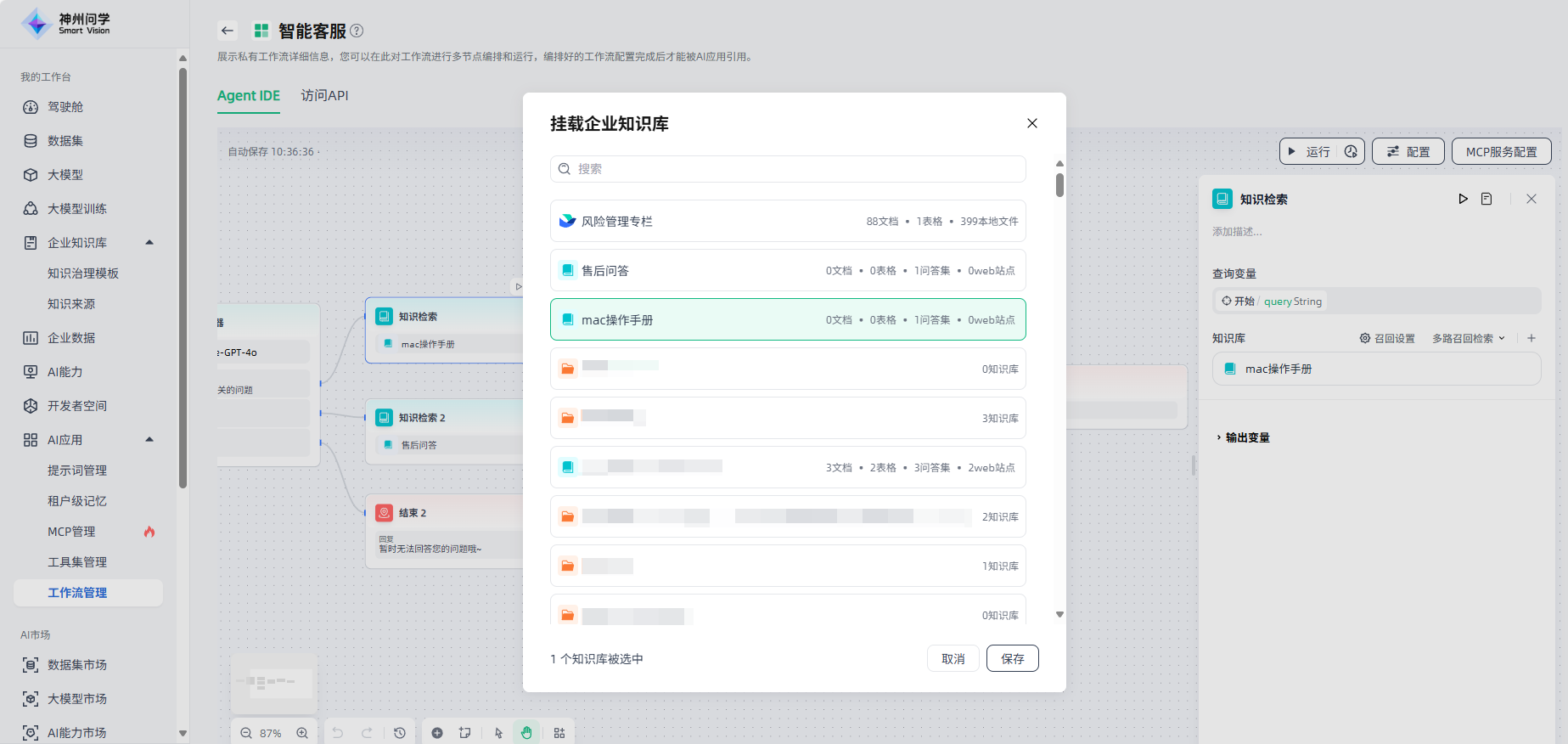
2.添加知识库:在知识检索节点中,您可以点击“+”添加知识库(对应工作台-企业知识库中的知识库)。
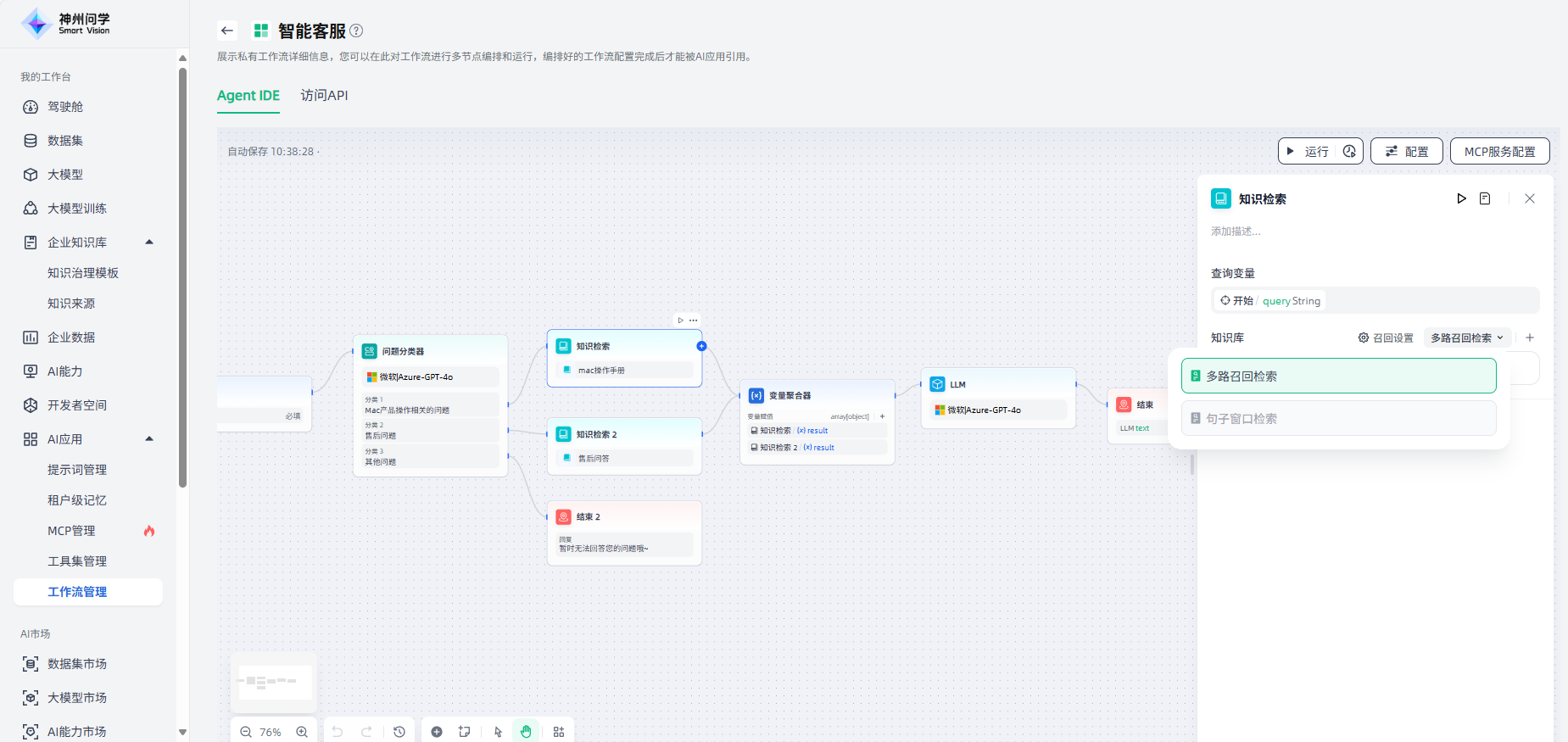
3.检索模式:添加知识库后,需要选择检索模式(可选的检索模式与所挂载的企业知识库的分段清洗规则有关),并支持切换。
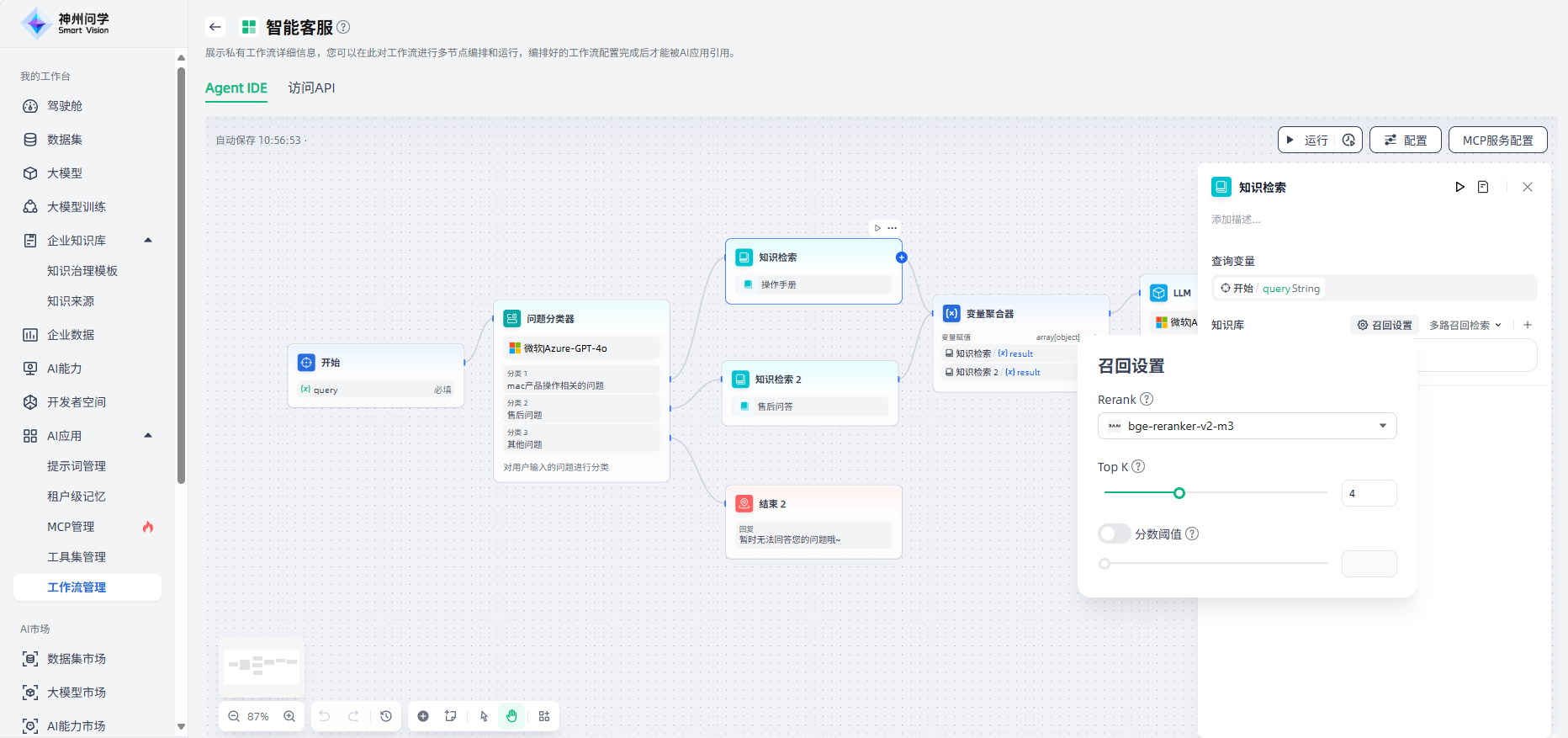
4.召回设置:添加知识库后,可以按需调整Top K、文本片段筛选的相似度值。
数据查询
数据查询节点是工作流中用于连接数据源并执行查询任务的节点,用于从企业的结构化数据源中获取特定信息,为后续节点或流程提供数据支持。通过它可以从数据库等中获取所需的数据结果,作为流程判断、计算、展示或决策的依据。
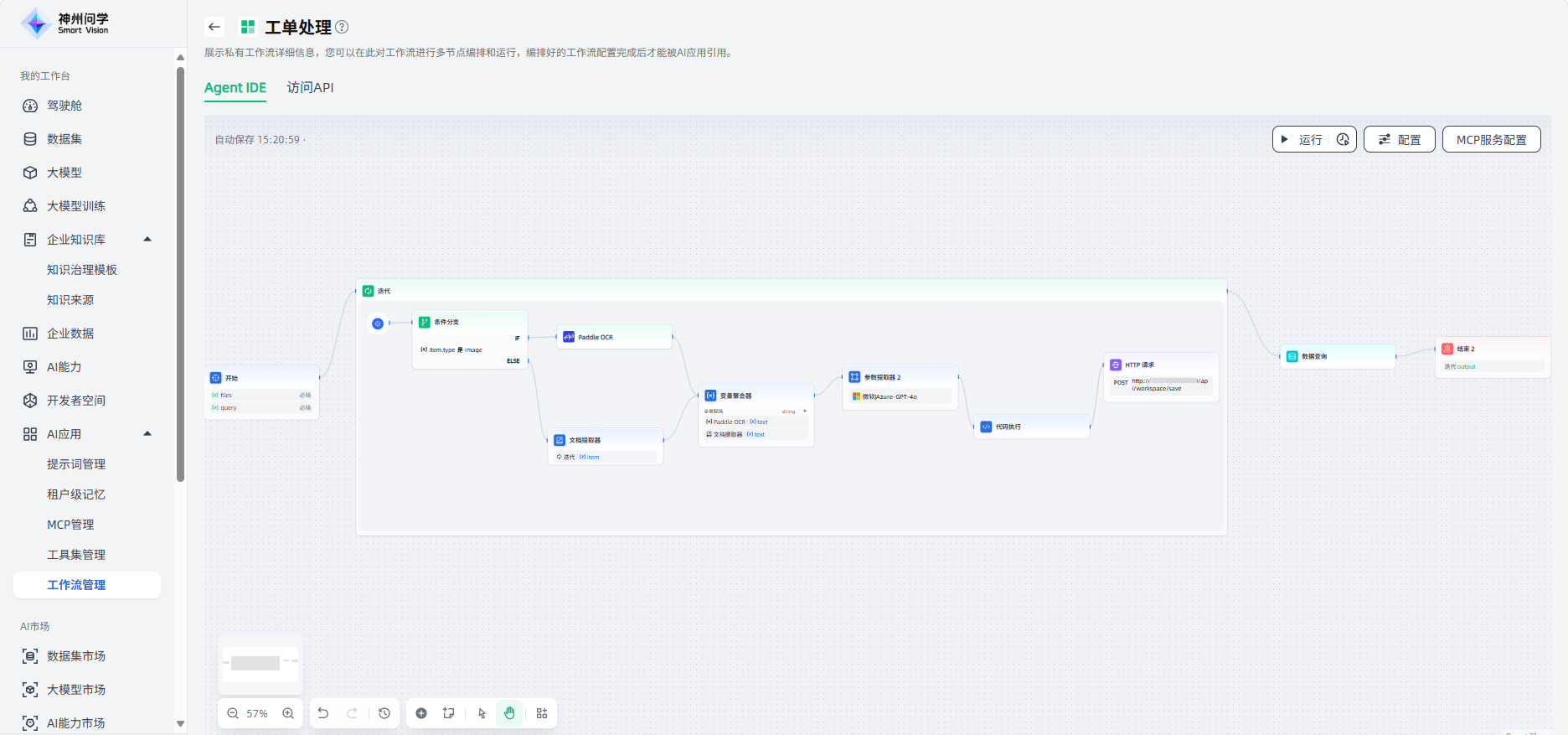
数据查询节点的配置步骤如下:
1.设置查询变量:在数据查询场景中,查询变量通常表示用户输入的问题。
2.挂载企业数据舱:点击“+”选择数据舱,作为数据查询的数据源。
3.选择模型:数据查询依赖于 LLM 的能力,根据您的场景需求选择一个合适的模型。
4.下游节点配置:数据查询节点的下游节点需要配置为结束节点,方可在AI应用中调用。
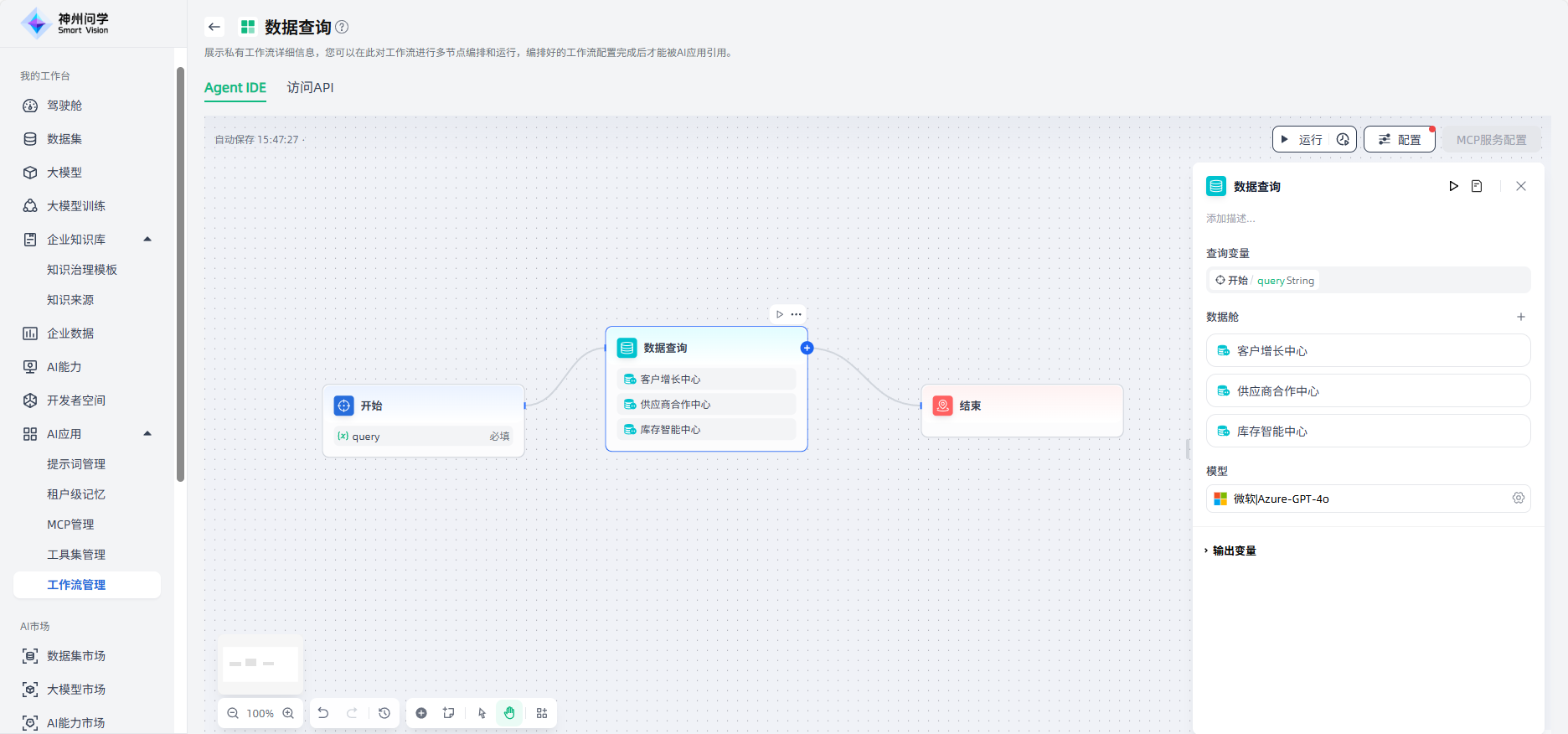
问题分类器
通过定义分类描述,问题分类器可以根据用户输入,推断并输出与其相匹配的分类结果。
问题分类器节点常用在客服对话意图分类、电子邮件分类、用户评论分类等场景。如在产品客服问答场景中,问题分类器可以作为知识检索前的步骤,对用户的输入问题进行分类,将其分流至不同的下游知识库进行查询,以便准确响应用户的问题。
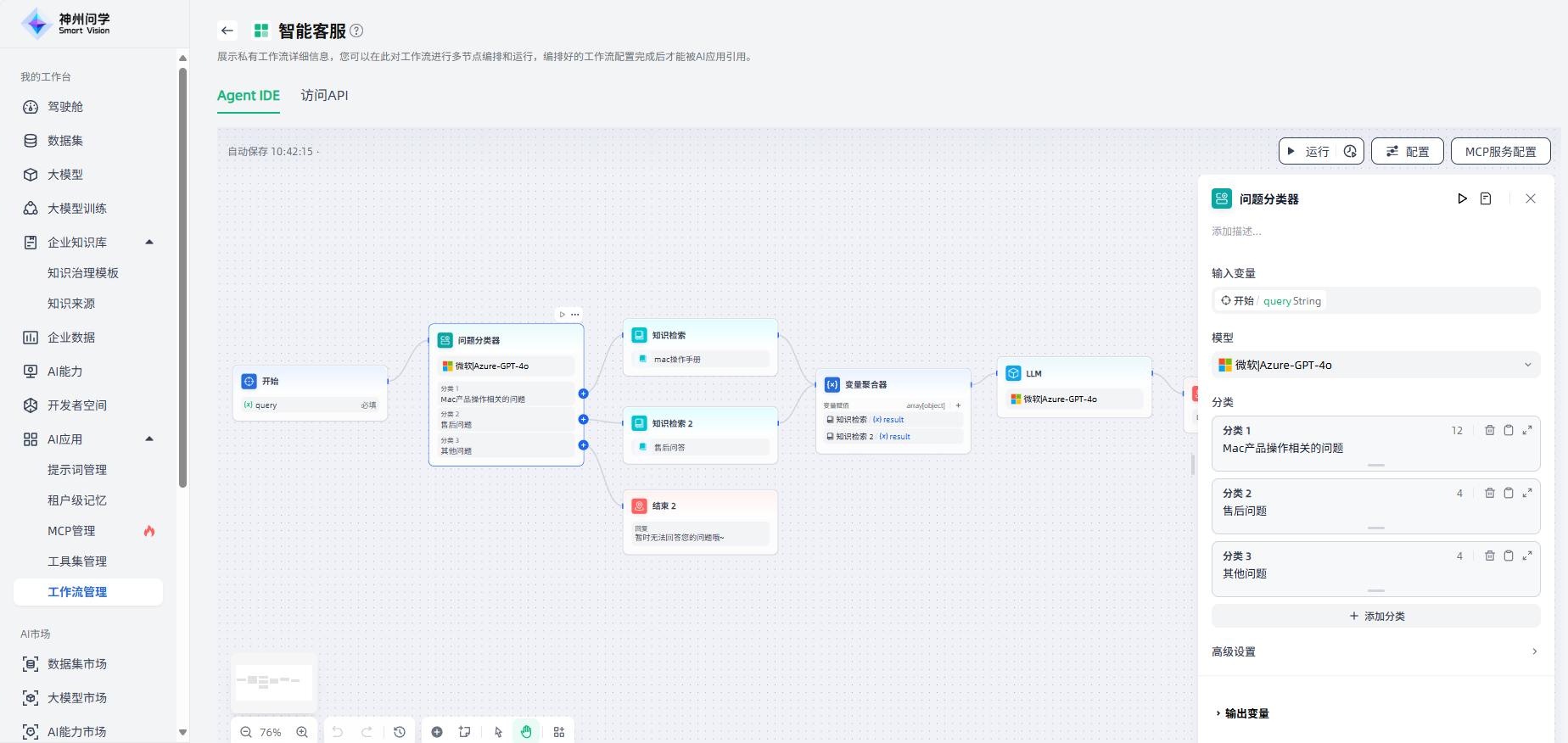
问题分类器节点的配置步骤如下:
1.设置输入变量:即设置需要分类的内容,比如客服问答场景中用户输入的问题。
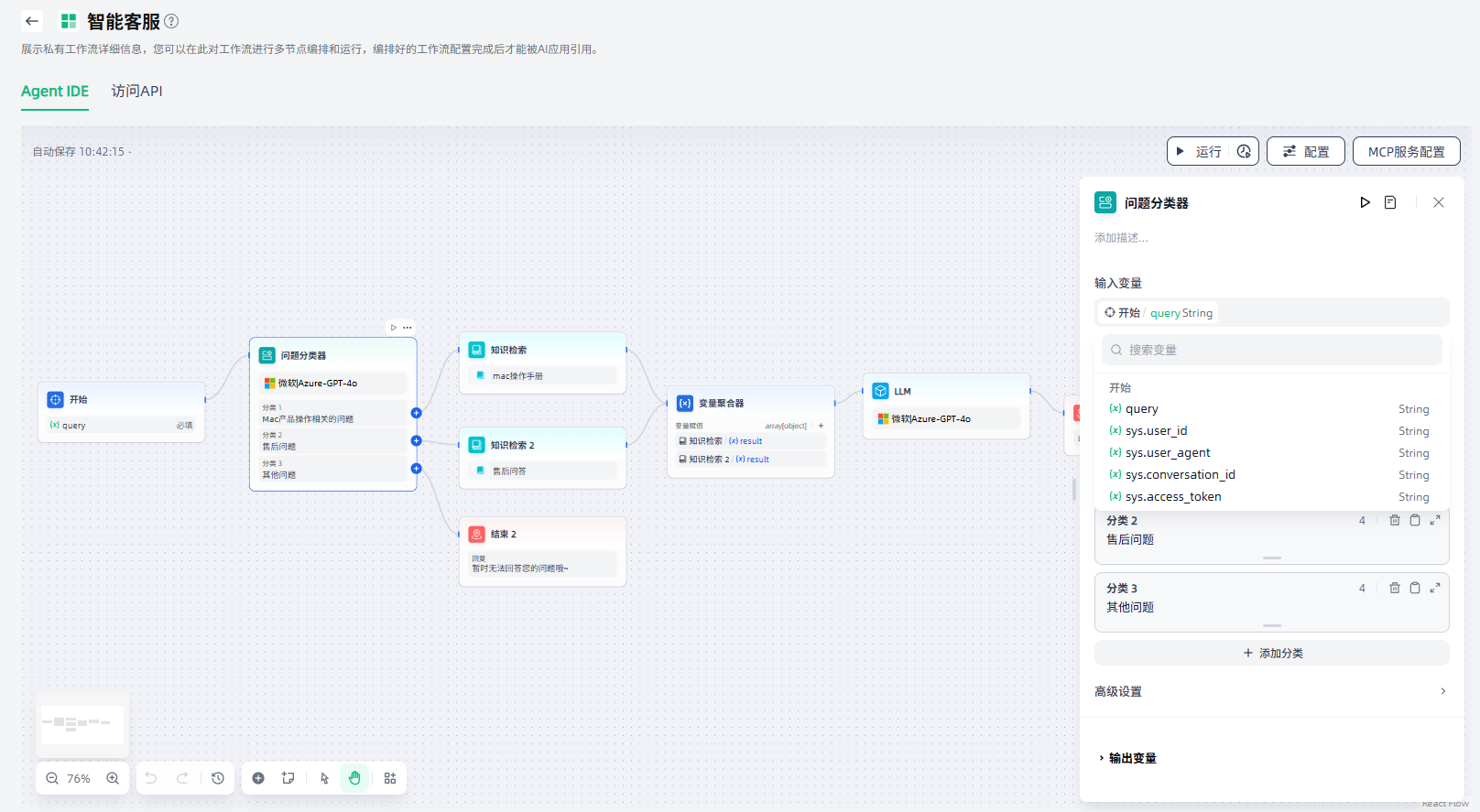
2.选择模型:使用问题分类器节点时,需要选择合适的模型,使用其自然语言分类和推理功能,保障分类效果。
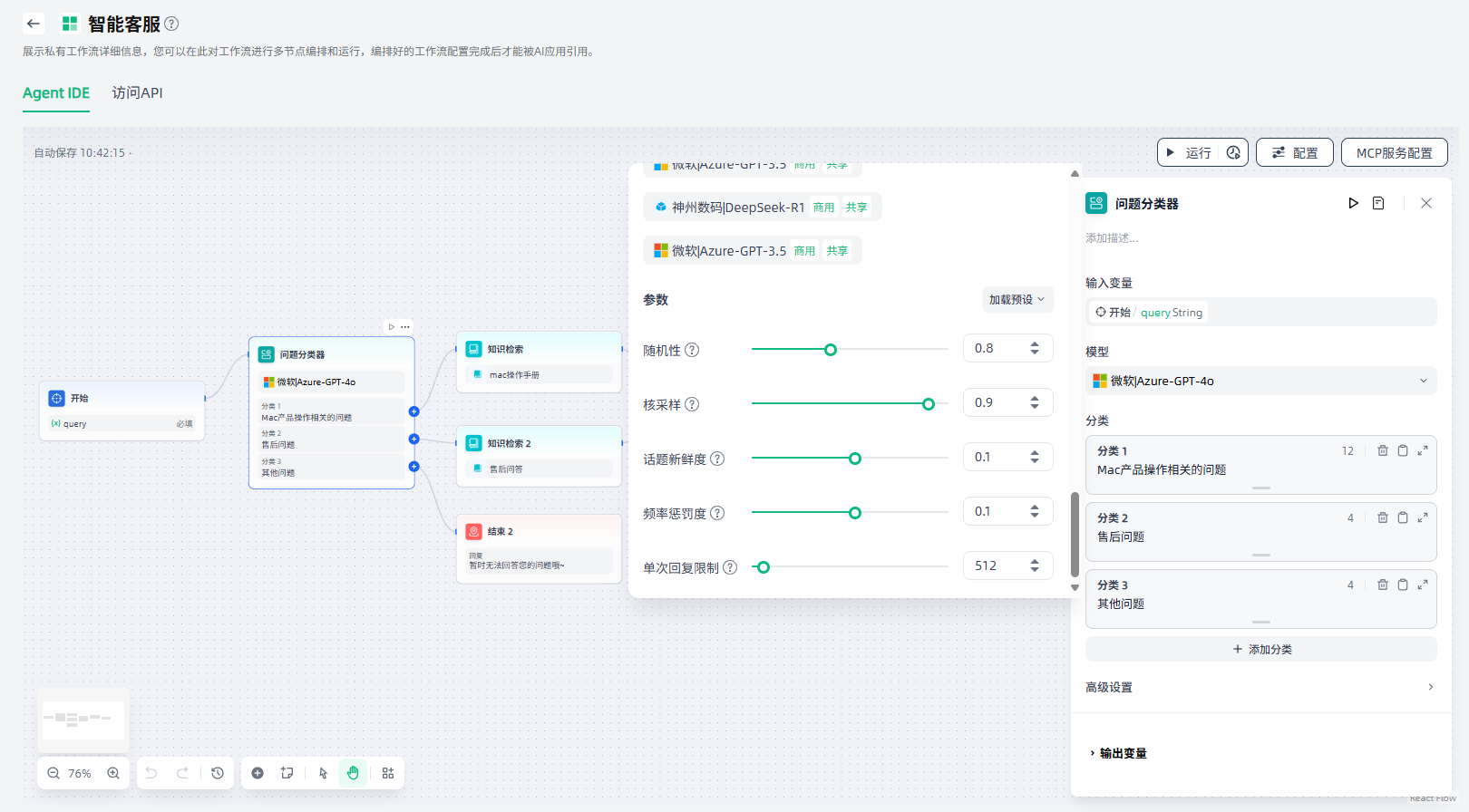
3.设置分类:需要根据您的场景需求,为每个分类设置关键字或描述性语句,帮助模型更好地理解分类标准。
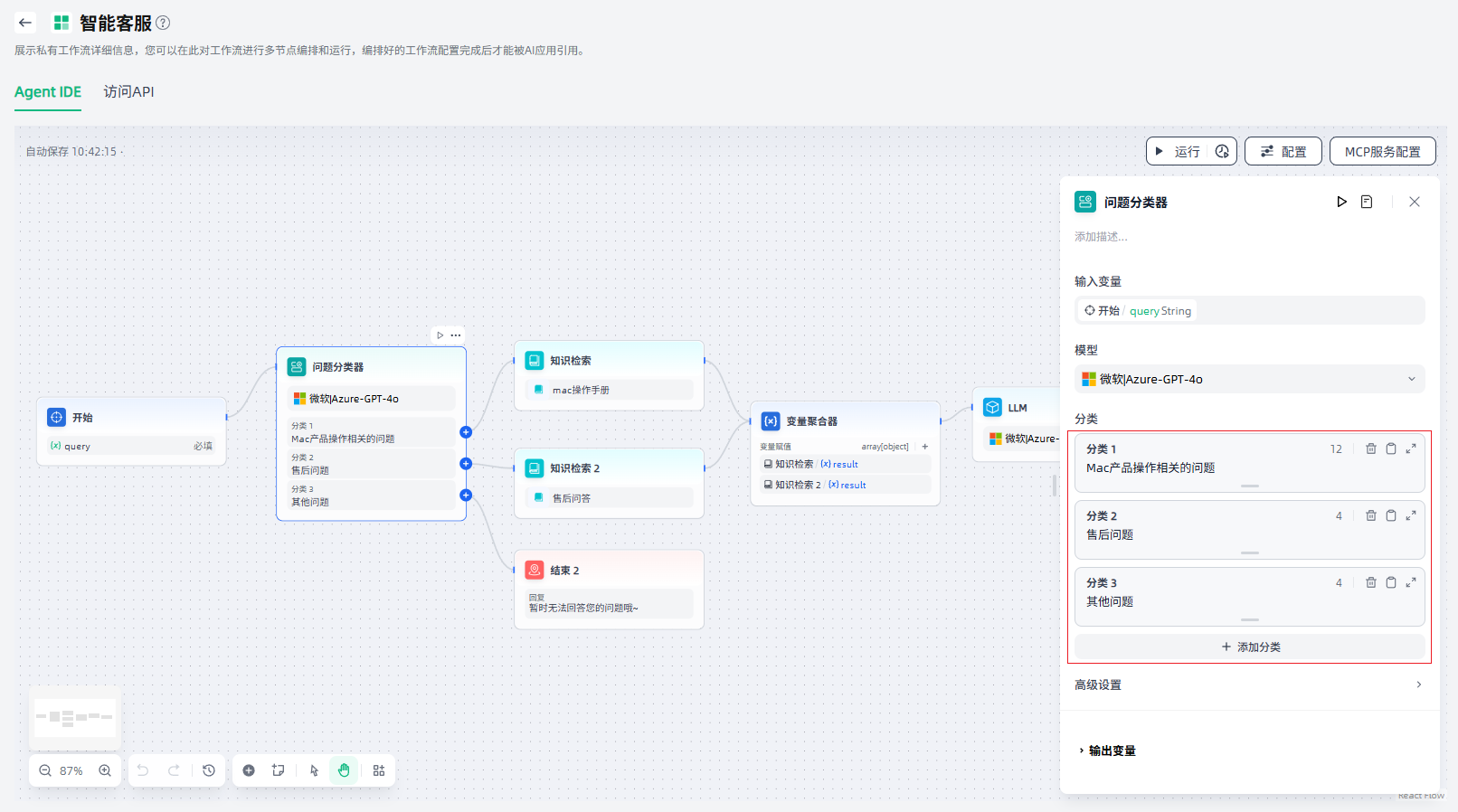
4.设置对应的下游节点:每个分类需要连接对应的下游节点,便于将用户问题分流至不同的路径。
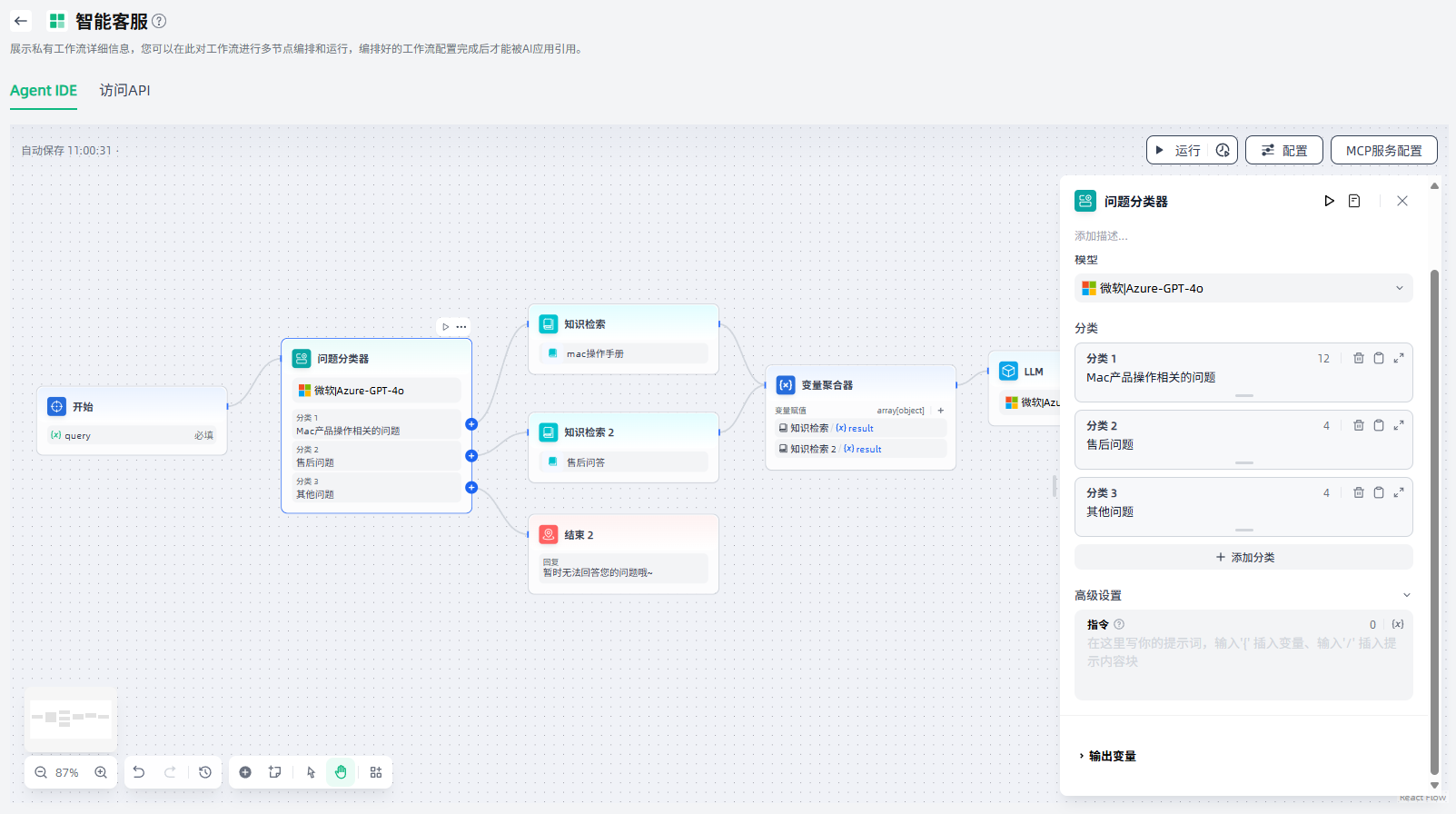
5.高级设置:可以按需编写补充的指令说明,帮助问题分类器更好地理解如何分类。
条件分支
使用条件分支节点,通过If/Else条件,可以将工作流拆分为多个分支:如果IF条件的计算结果为True,则执行IF路径;如果IF条件的计算结果为False,则执行ELSE路径;还可以点击“+ELIF”添加ELIF条件,如果ELIF条件的计算结果为True,则执行ELIF路径;如果ELIF条件的计算结果为False,则继续计算下一个ELIF路径或执行最终的ELSE路径。
条件分支节点支持包含、不包含、开始是、结束是、是、不是、为空、不为空8种条件类型,如以下工作流使用了条件分支节点,使用了“包含”这个条件类型。
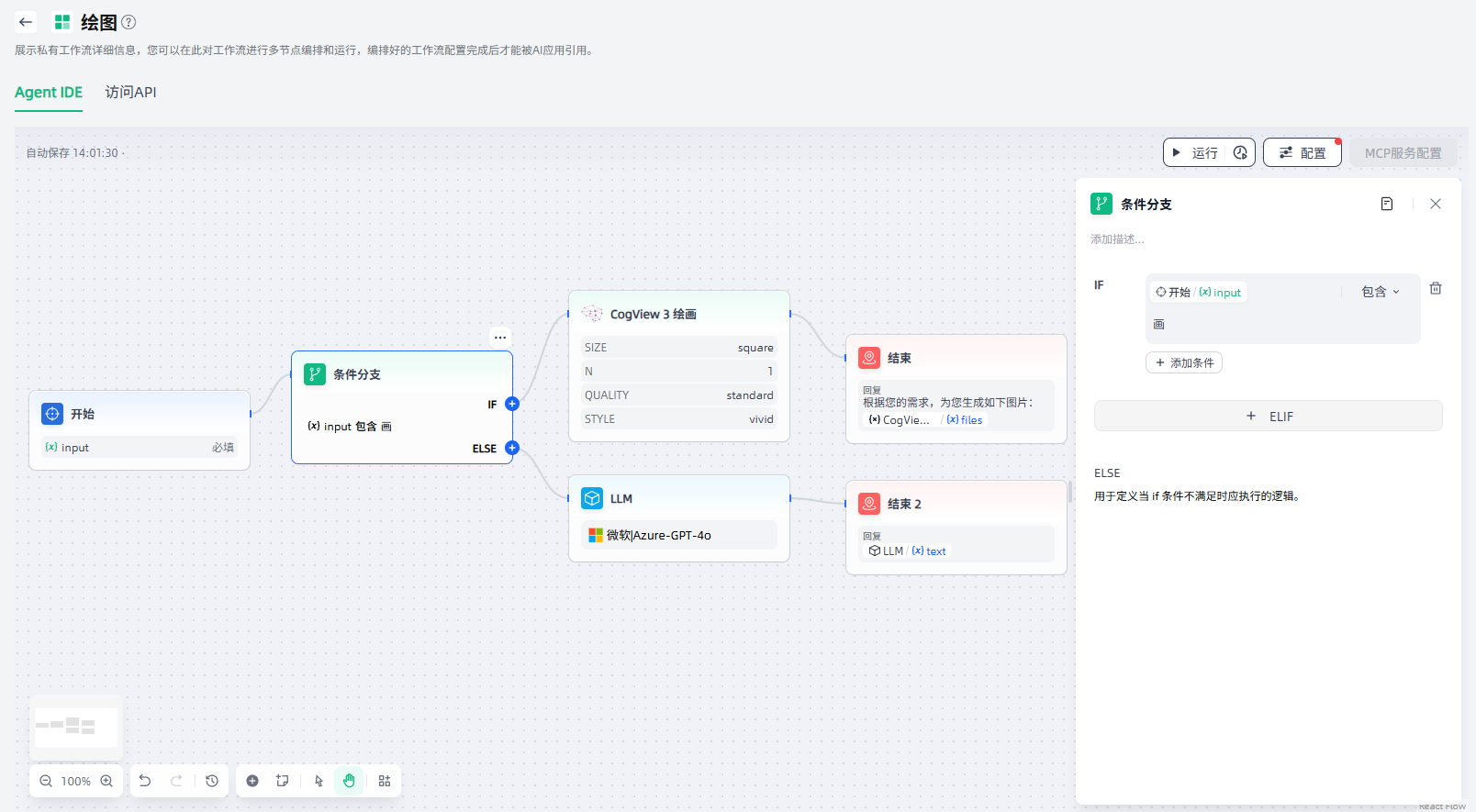
对于复杂的条件判断场景,还可以设置多重条件判断,在条件之间设置AND或者OR,便于在条件之间取交集或者并集。
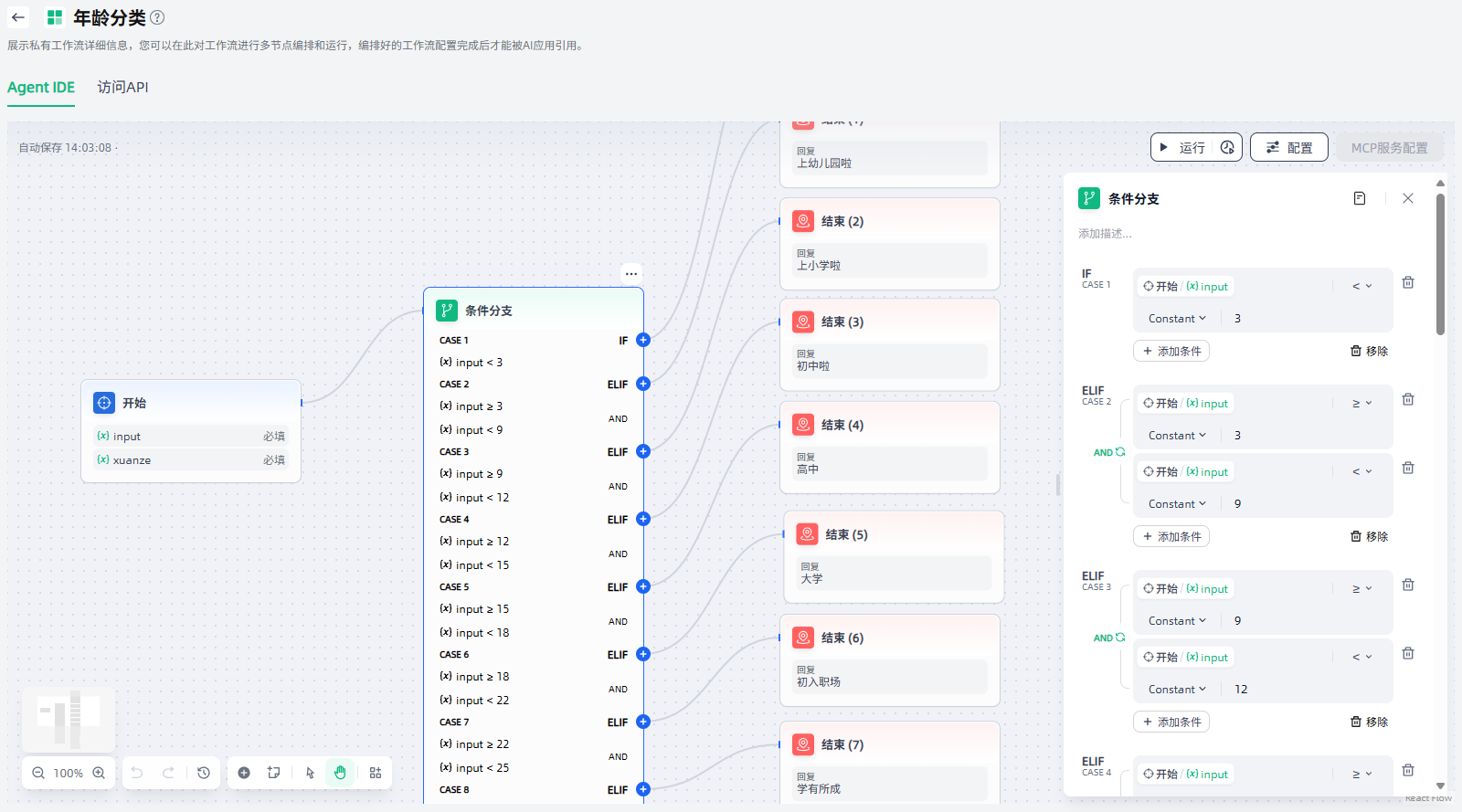
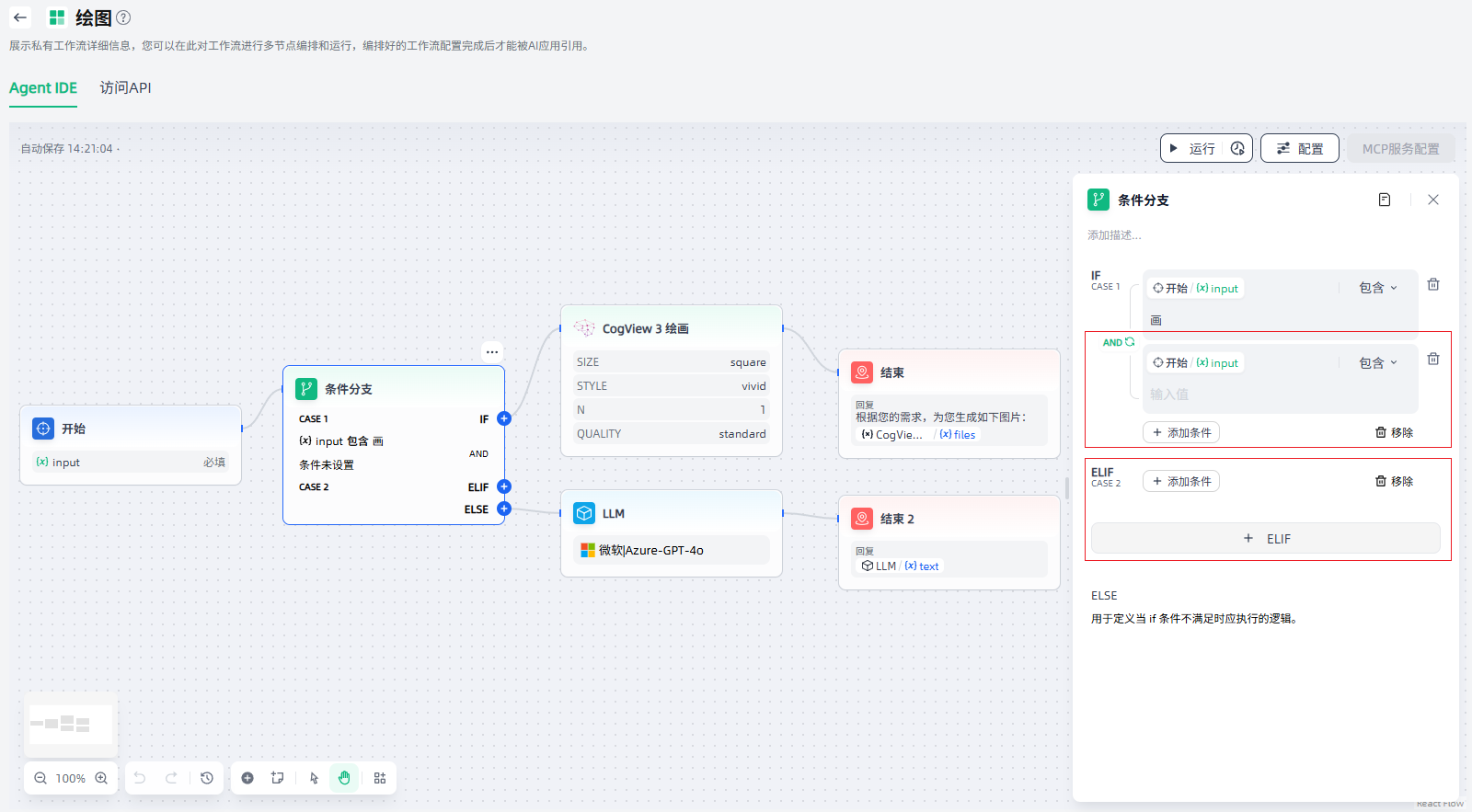
条件分支节点的核心,在于设置判断条件:点击“添加条件”,选择变量、选择条件类型、并指定满足条件的值,即可完成条件设置;继续“添加条件”,即可设置多重条件;如需更多分支,点击“+ELIF”设置ELIF条件即可。
迭代
使用迭代节点,可以对数组中的内容进行循环处理,即对数组每个项目执行相同的步骤,直至输出所有结果,便于AI工作流处理更复杂的场景逻辑,常用于对长文本进行特定处理的场景。
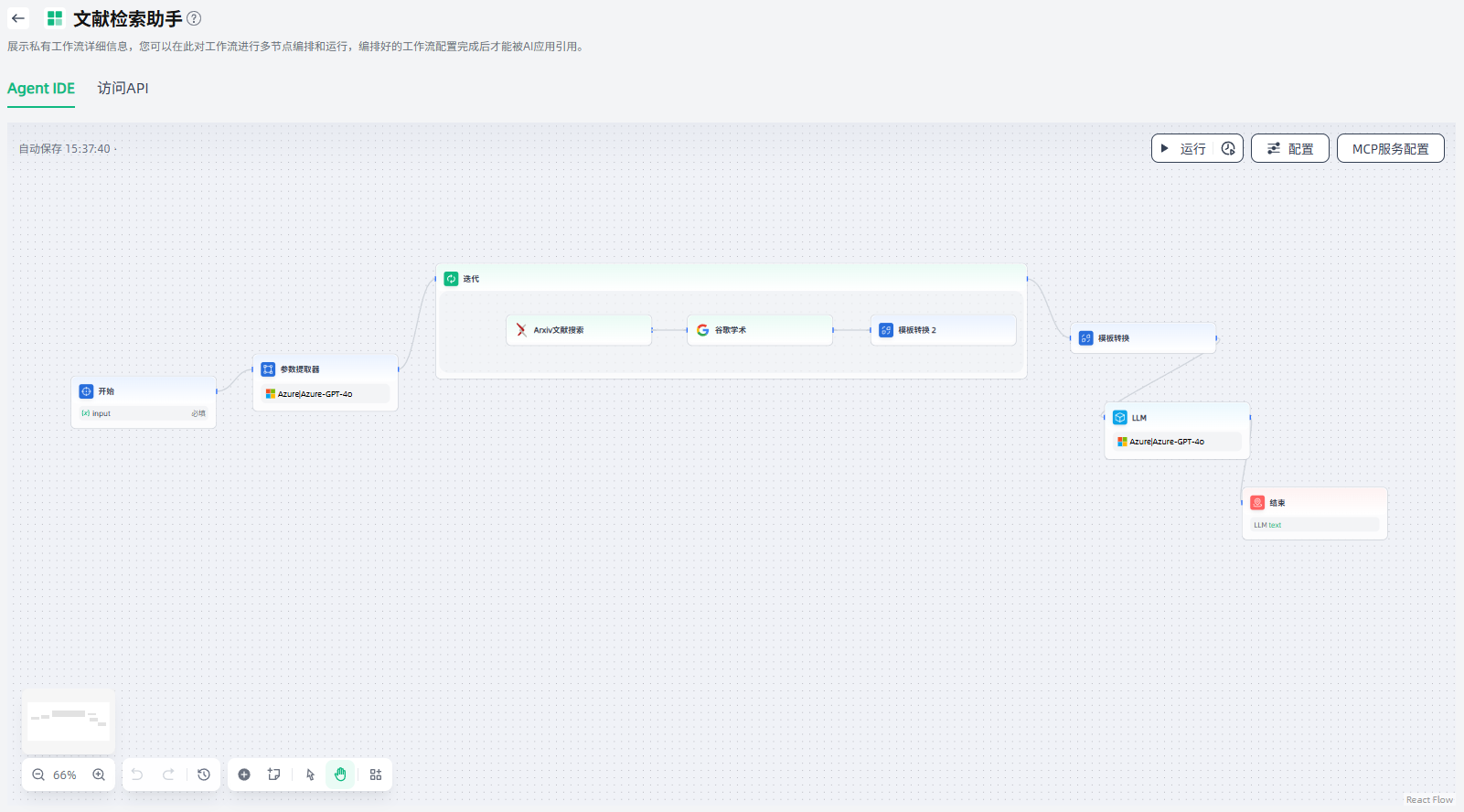
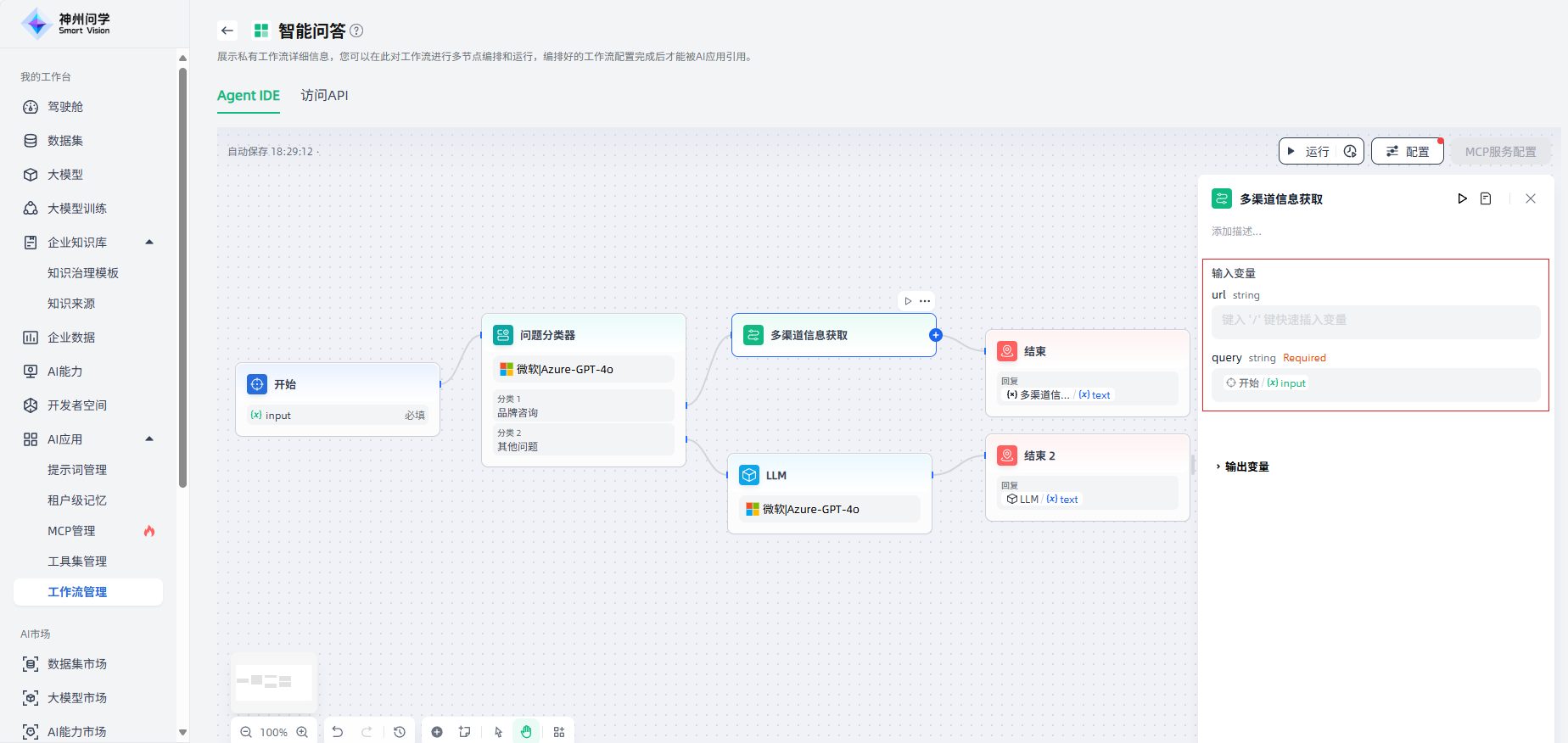
迭代节点的输入变量和输出变量都是数组格式(Array),使用迭代节点需要上游节点支持返回数组(支持数组返回的节点为:代码执行、参数提取器、知识检索、迭代、HTTP请求)。
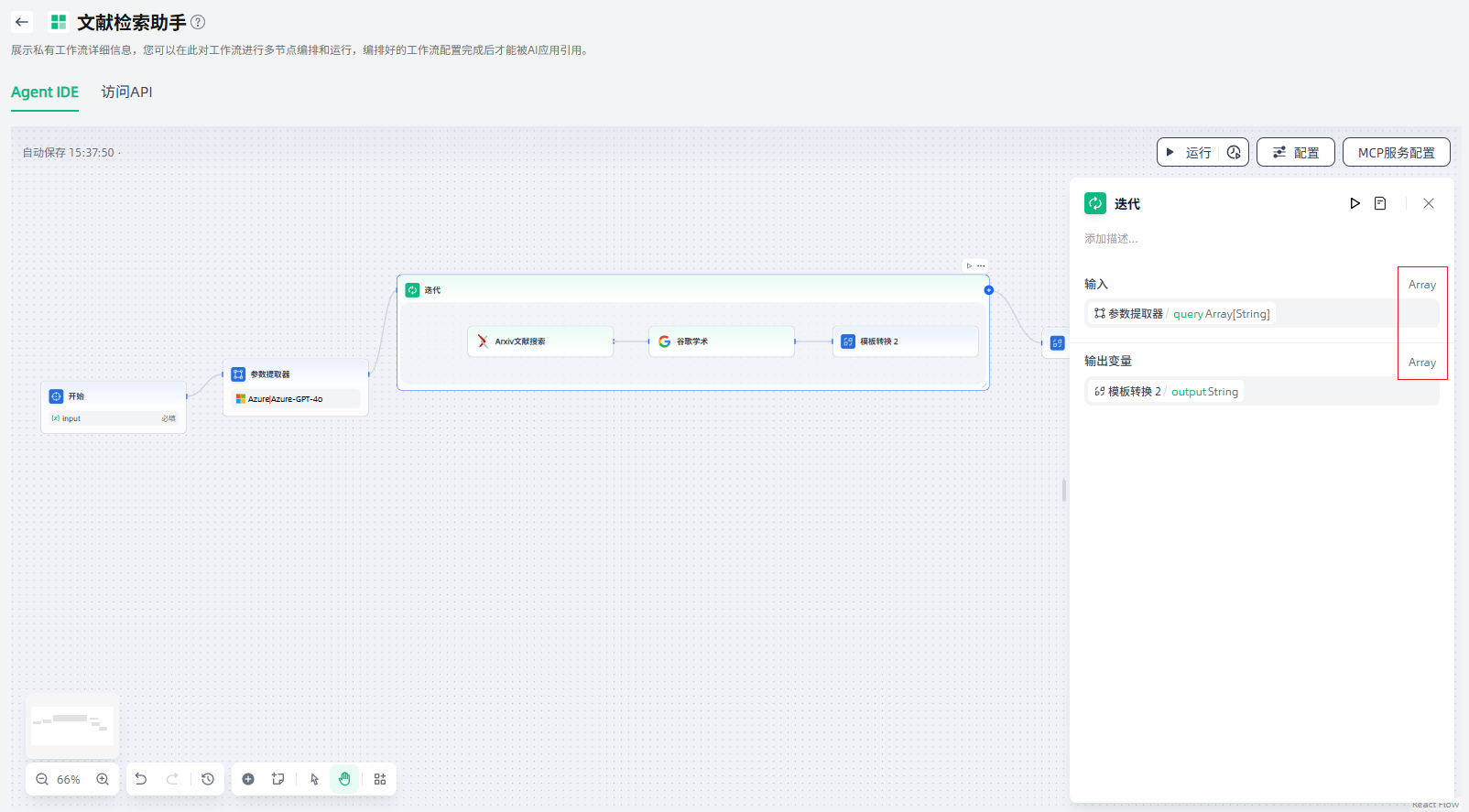
迭代节点的配置步骤如下:
1.设置输入变量:设置用于执行循环处理的变量输入(Array)。
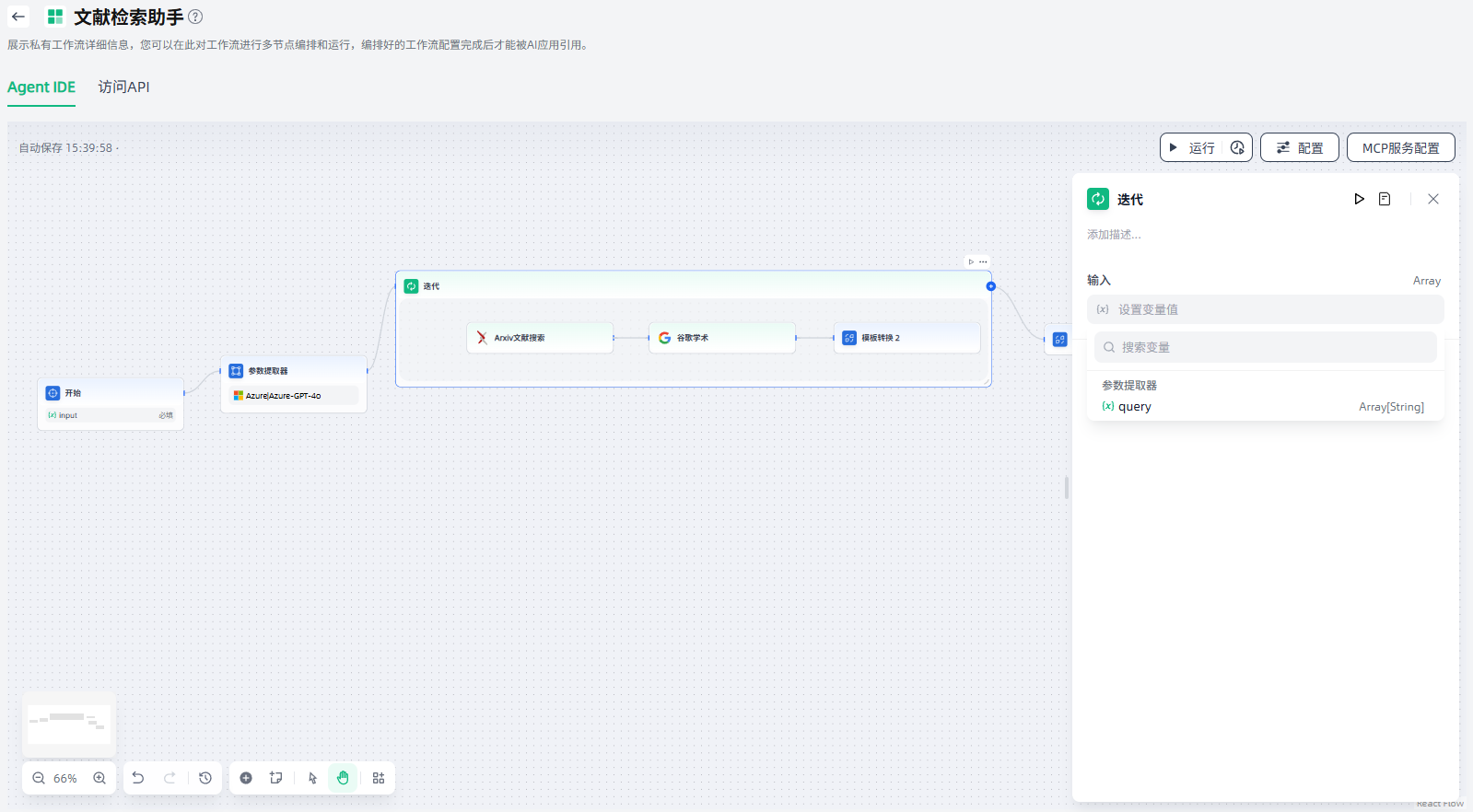
2.添加迭代内的节点:在迭代节点内添加子节点,并对每个子节点进行输入变量等配置。
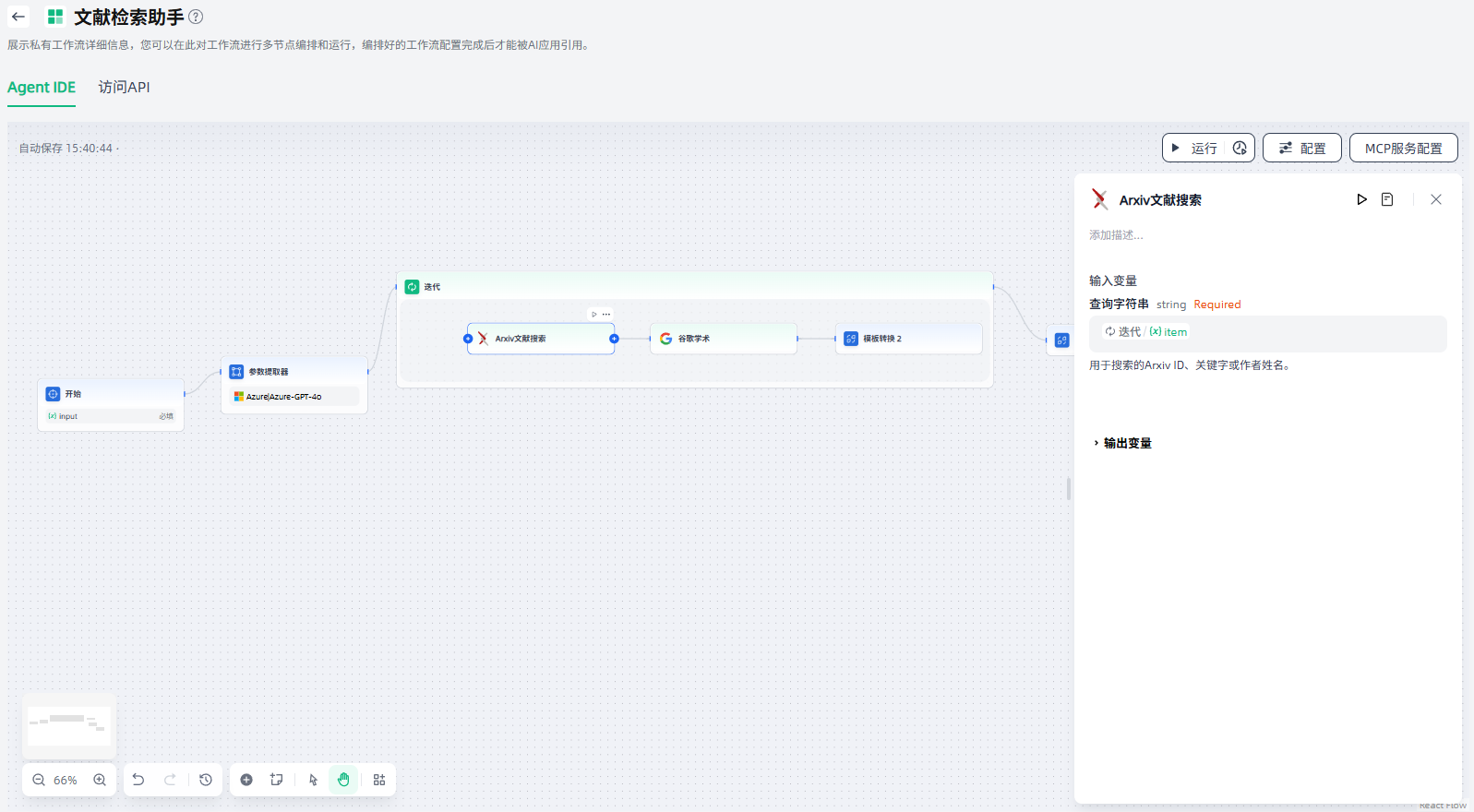
3.设置输出变量:设置迭代节点的输出变量。
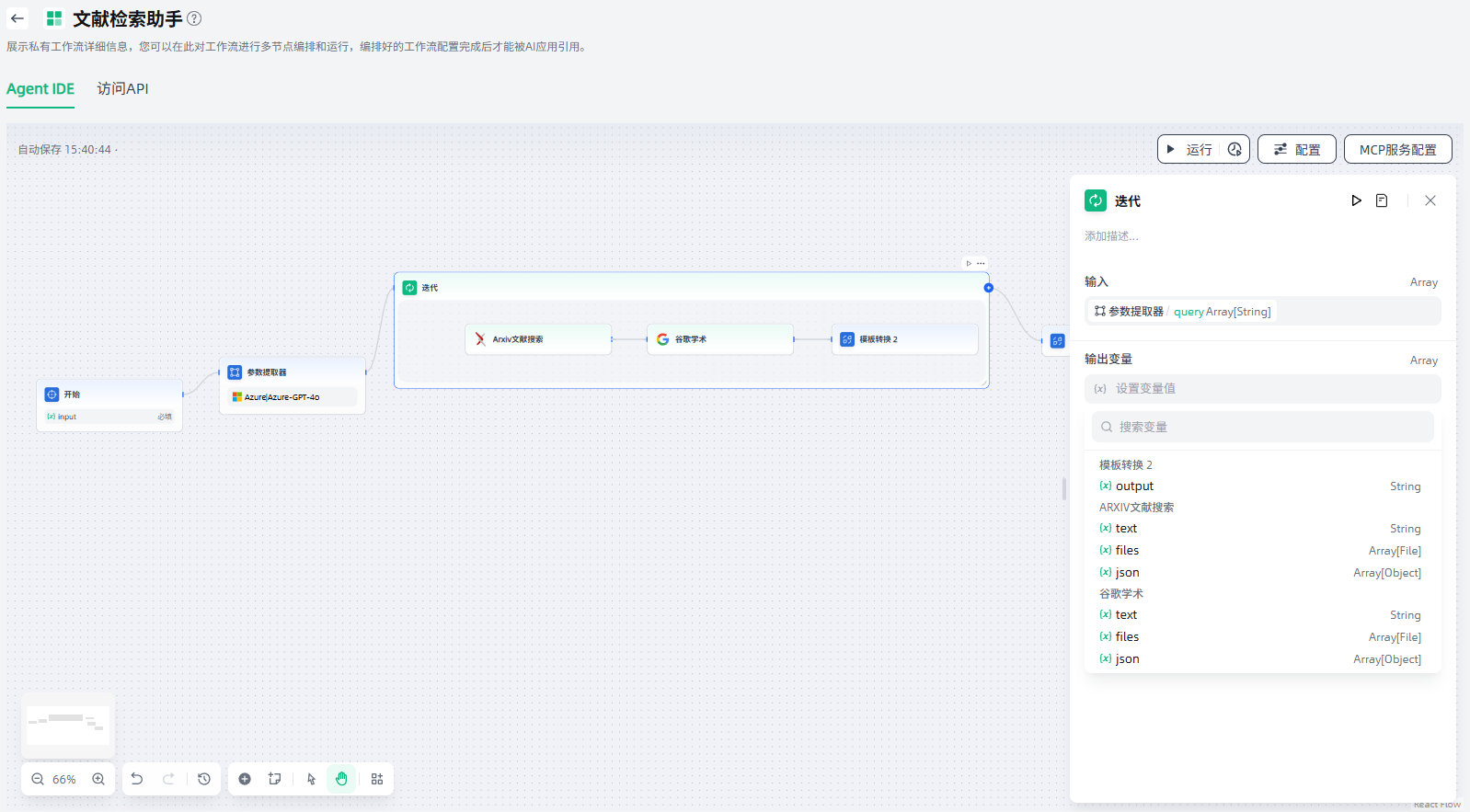
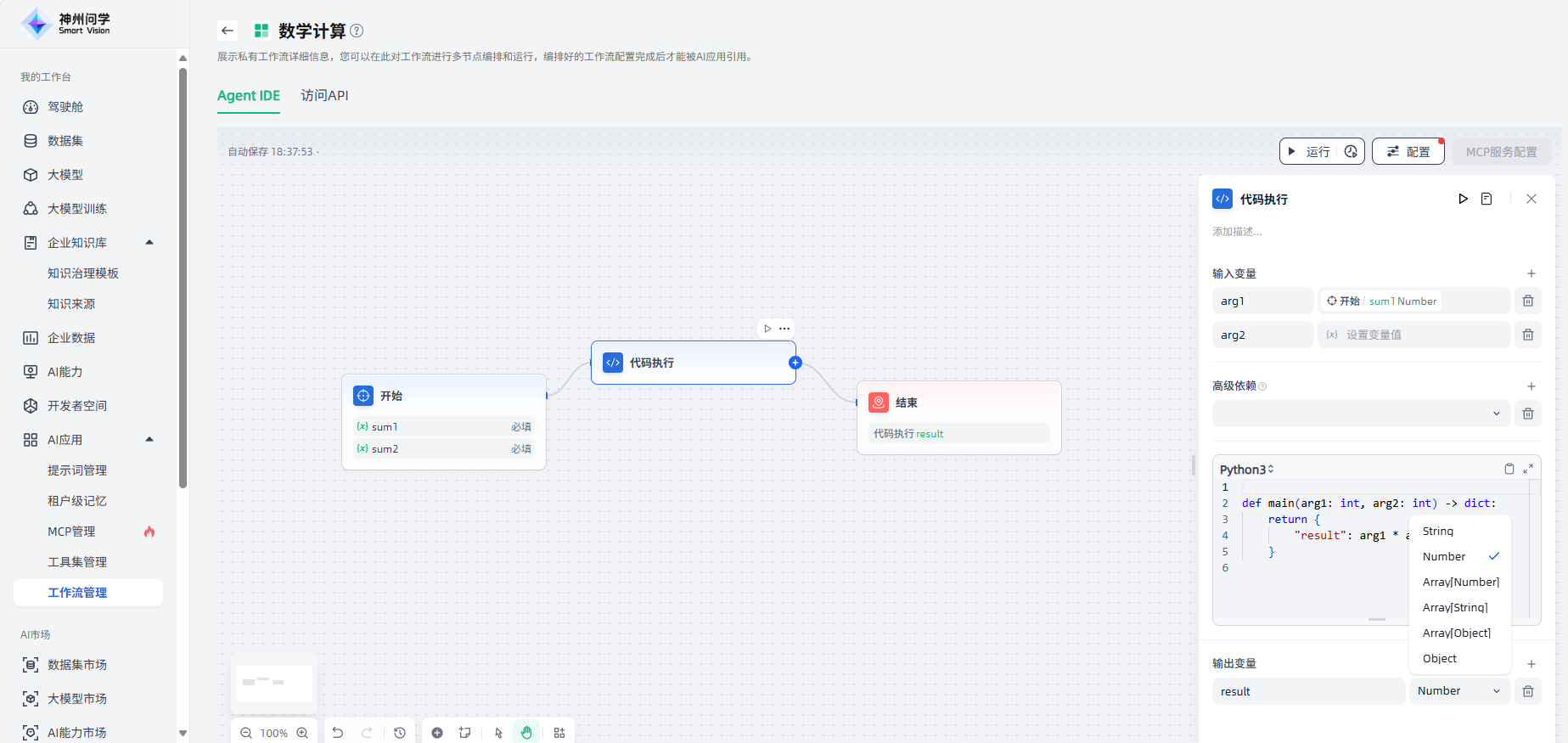
代码执行
代码执行节点支持运行Python/NodeJS代码,以在工作流中执行数据转换。通过代码执行节点,嵌入自定义 Python 或 JavaScript 脚本,便于以预设节点无法实现的方式操作变量、简化您的工作流程。
代码执行节点适用于数学计算、JSON 转换、文本处理等场景,如以下数学计算场景工作流使用了代码执行节点。
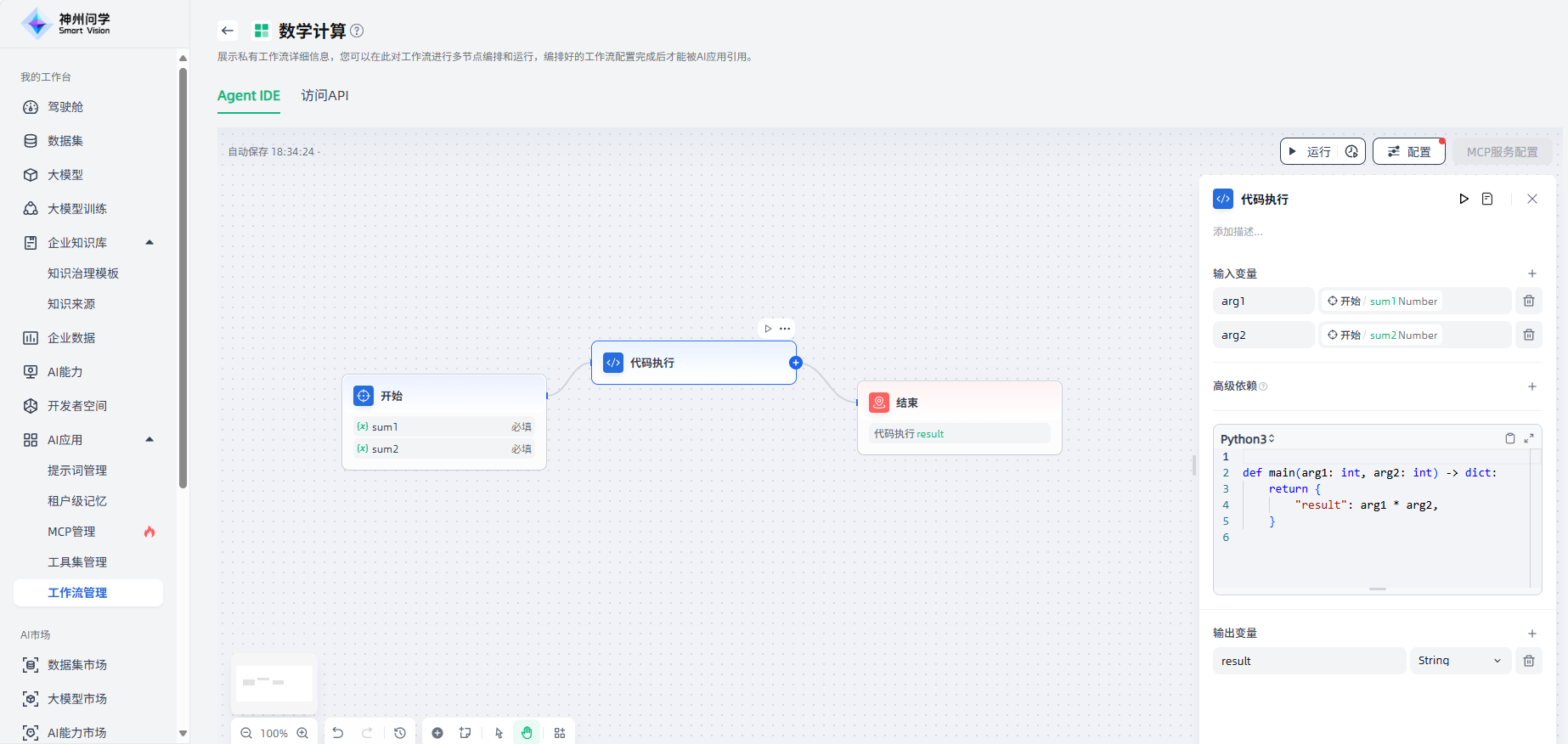
代码执行节点的配置步骤如下:
1.设置输入变量:通常设置为用于代码执行的变量输入。
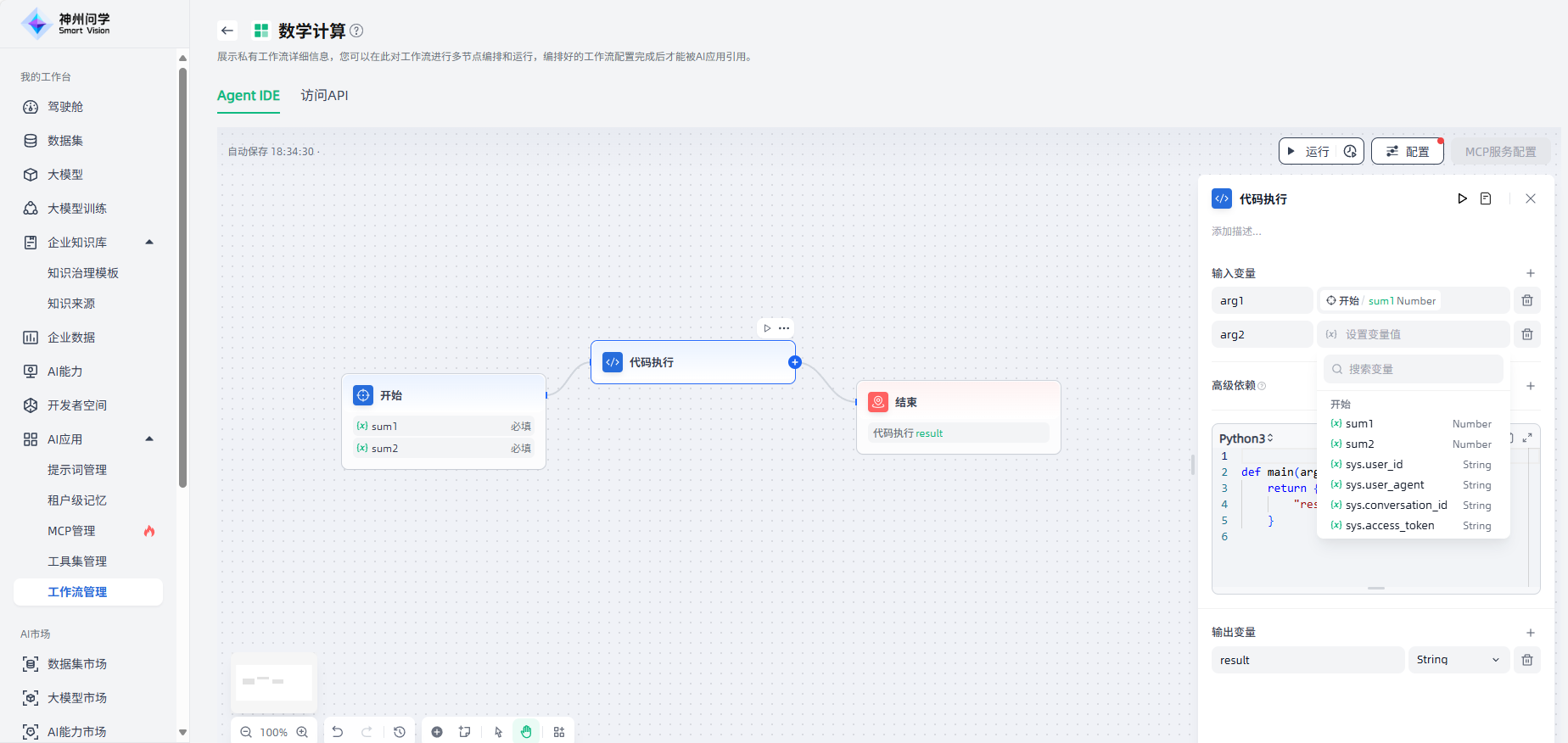
2.高级依赖:按需添加预加载需要消耗较多时间或非默认内置的依赖包,点击“+”即可添加。
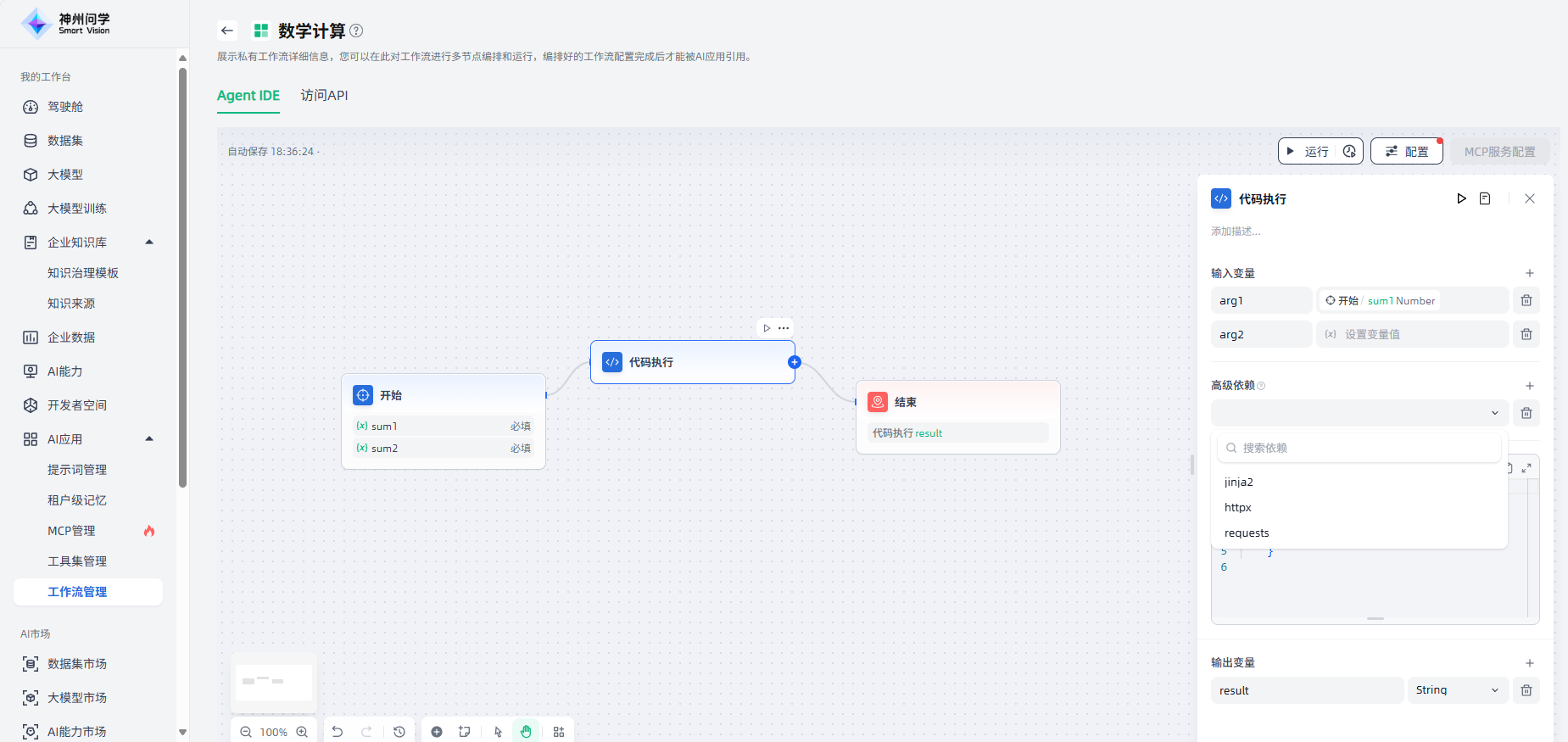
3.编写执行代码:选择需要的语言,并进行代码编写。
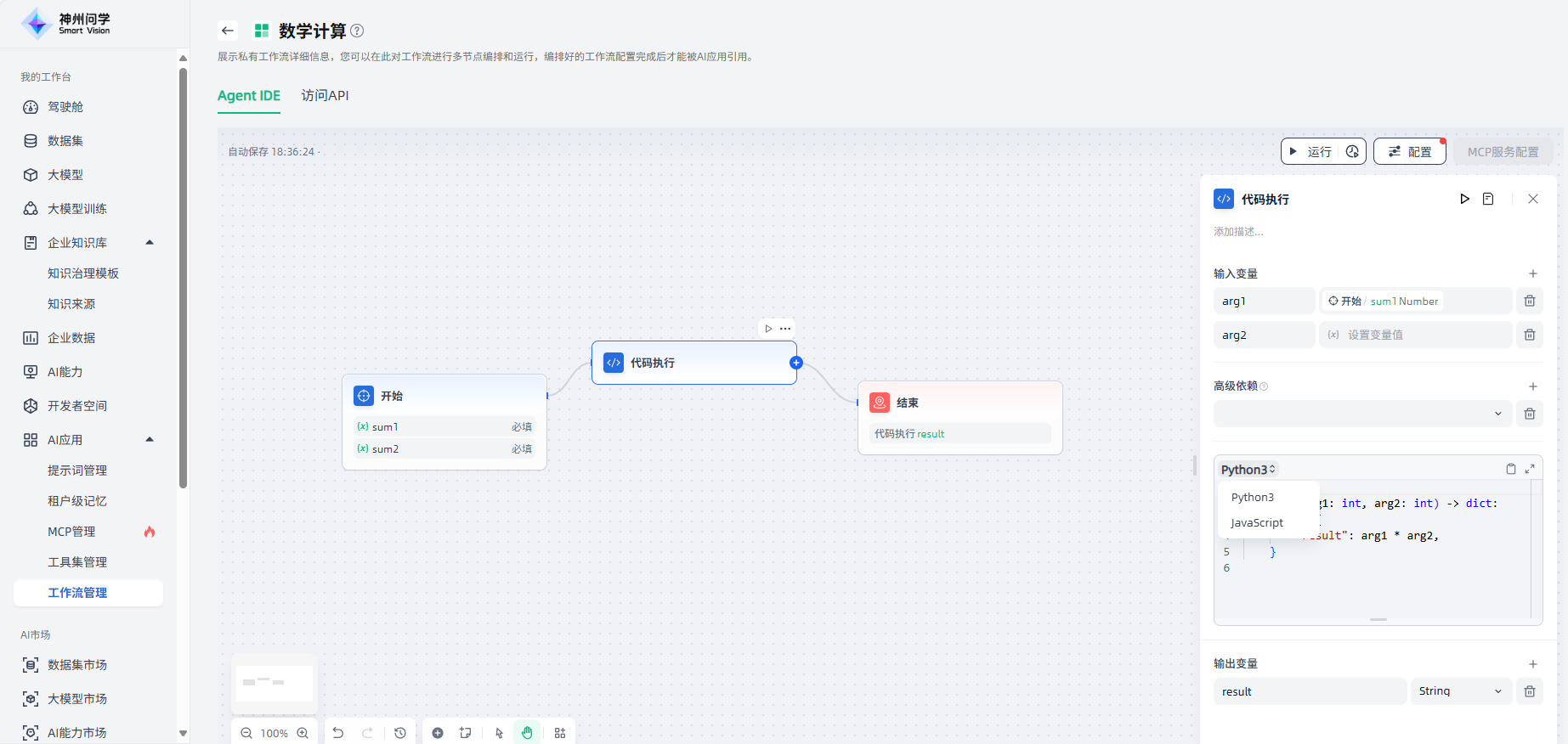
4.设置输出变量:设置该节点的输出变量、及其类型,支持添加多个输出变量。
模板转换
模板转换节点支持您使用 Jinja2动态格式化和组合来自上游节点的变量、并合并为单个基于文本的输出,可用于将来自多个源的数据合并到后续节点所需的特定结构中,帮助您在工作流内实现轻量、灵活的数据转换。
例如,以下工作流中,使用模板转换节点,将知识检索节点获取的信息及其相关的元数据,结构化为格式化的 Markdown,满足后续步骤的需求。
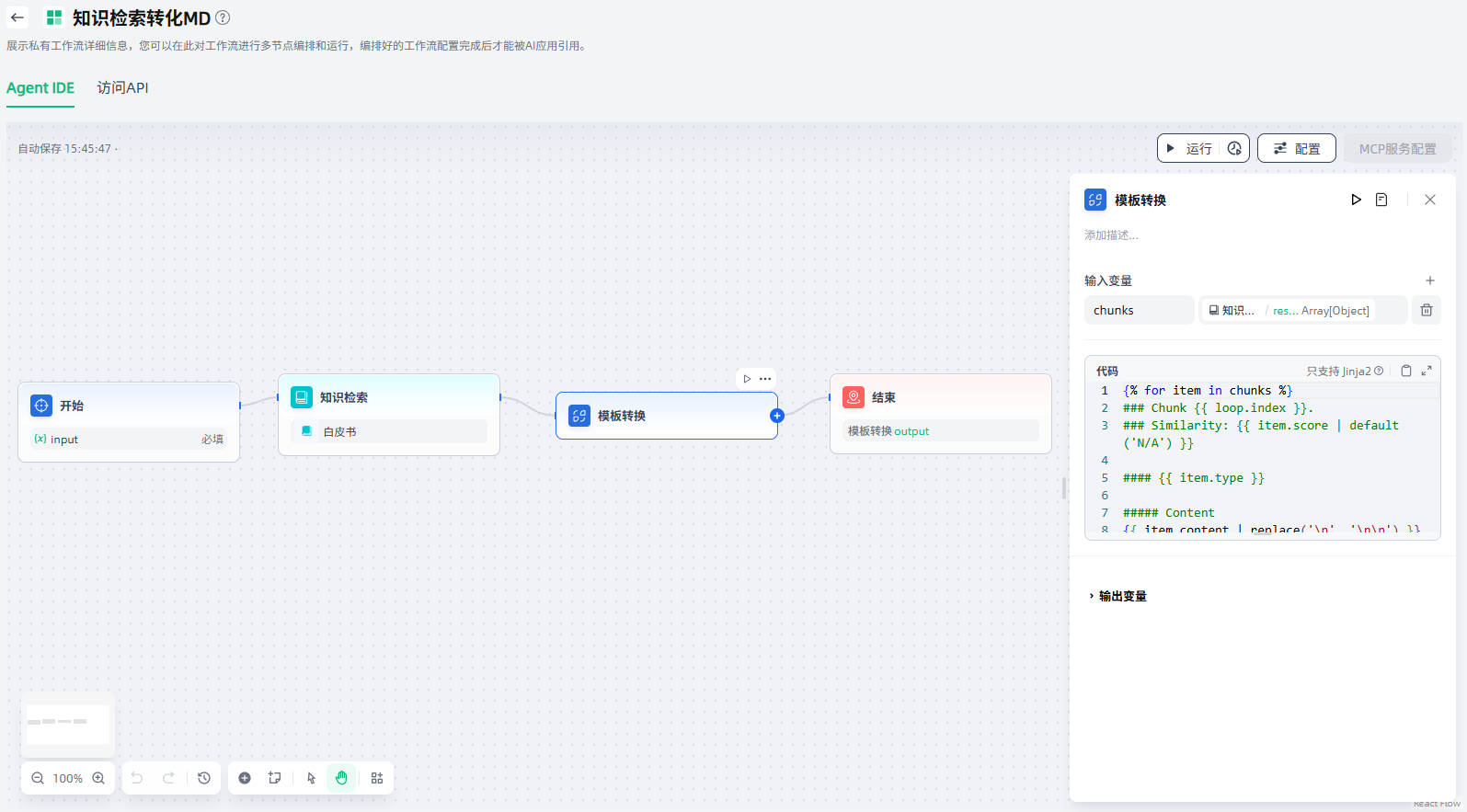
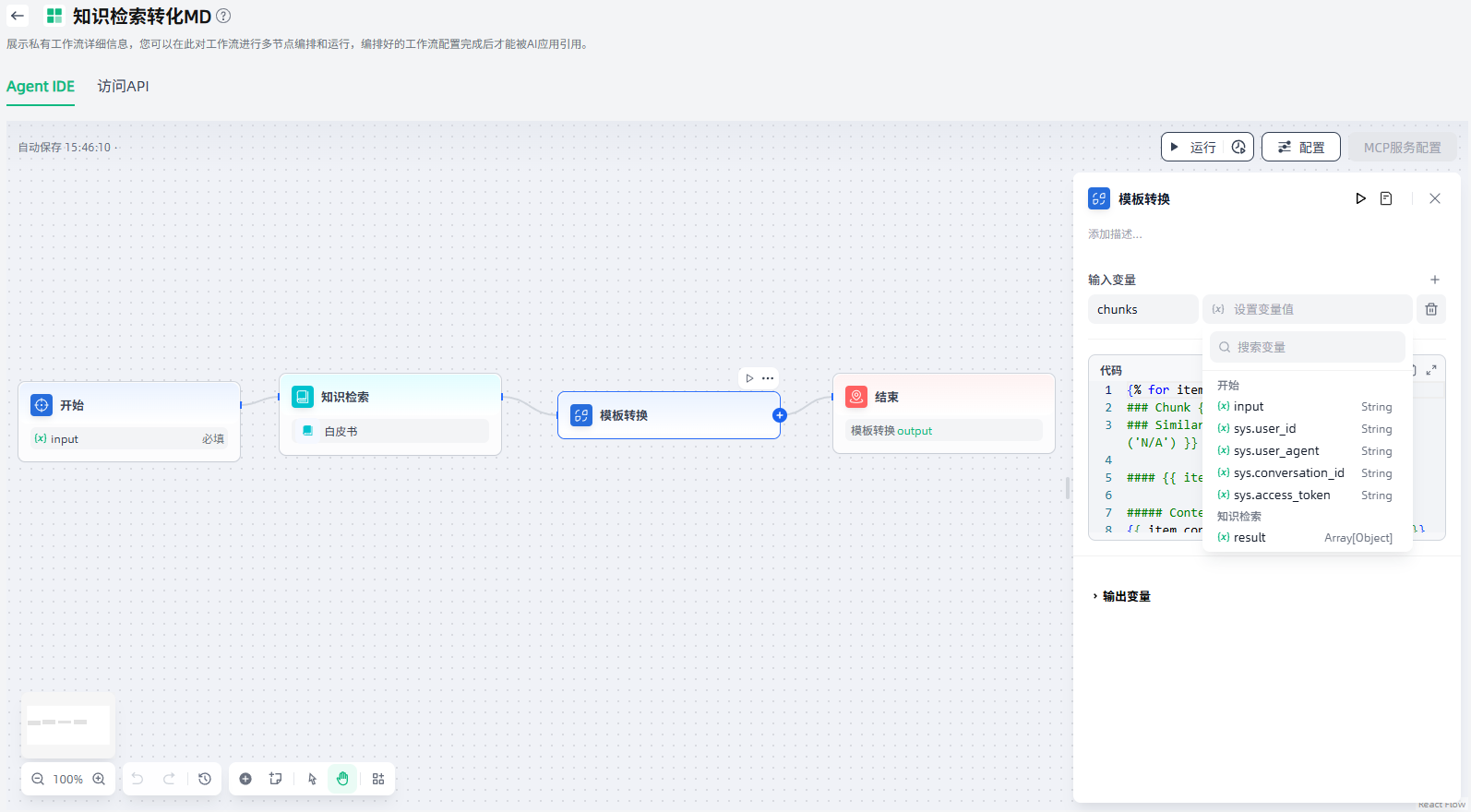
模板转换节点的配置步骤如下:
1.设置输入变量:设置需要进行转换的输入变量,支持设置多个输入变量(点击“+”添加)。
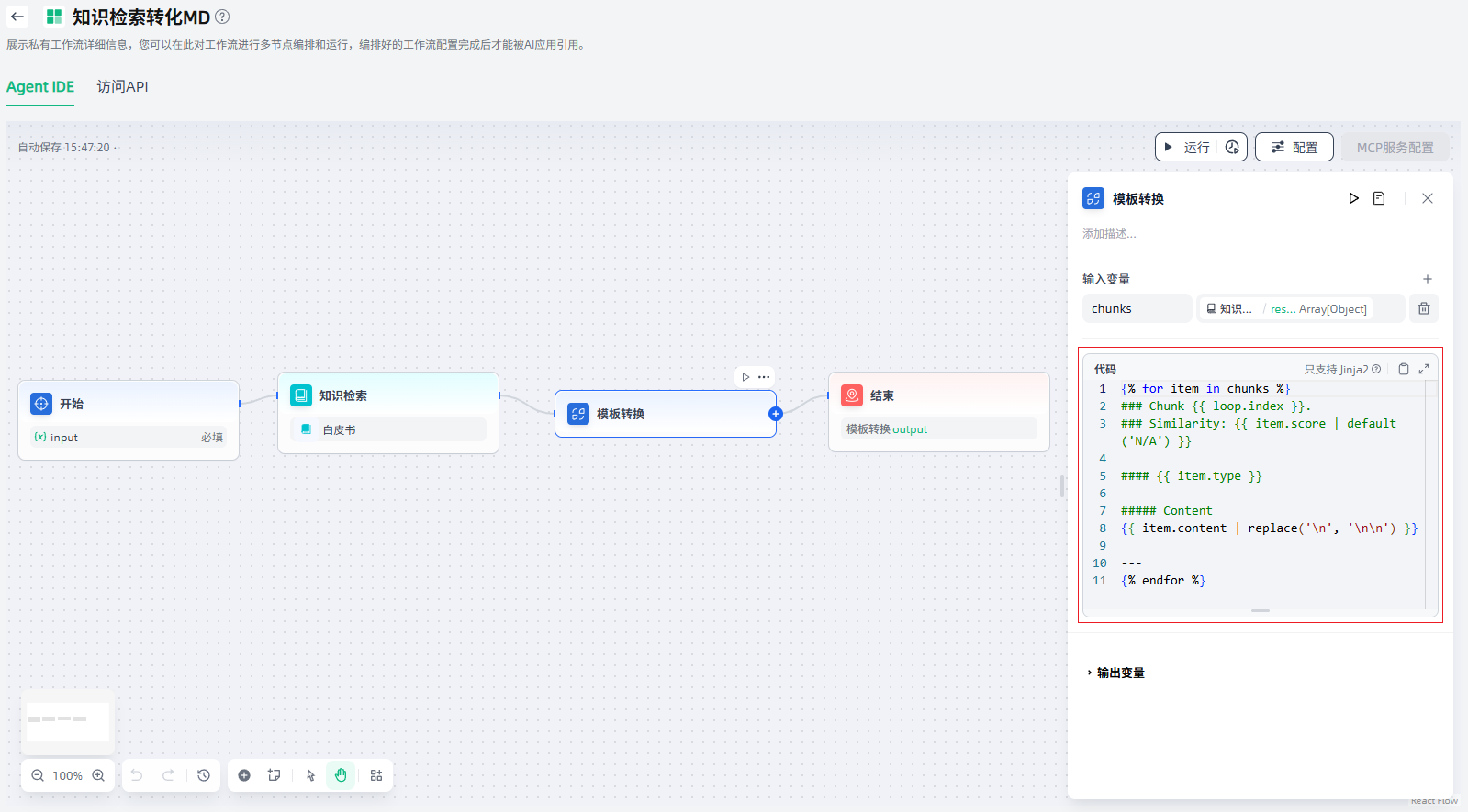
2.编写代码:使用Jinja2模板编写代码。
变量聚合器
变量聚合器节点是工作流中的关键节点,用于将多个分支的变量聚合为一个变量,实现下游节点的统一配置。变量聚合器节点负责整合不同分支的输出结果,确保无论执行哪个分支,其结果都可以通过一个统一的变量进行引用和访问。
变量聚合器节点能有效简化多分支场景的数据流管理,通过变量聚合,可以将多个输出聚合为单个输出,供下游节点使用和操作。如在客服问答场景中,如果没有使用变量聚合器节点,分类一问题和分类二问题的分支在进行不同的知识库检索后,需要分别定义下游节点。
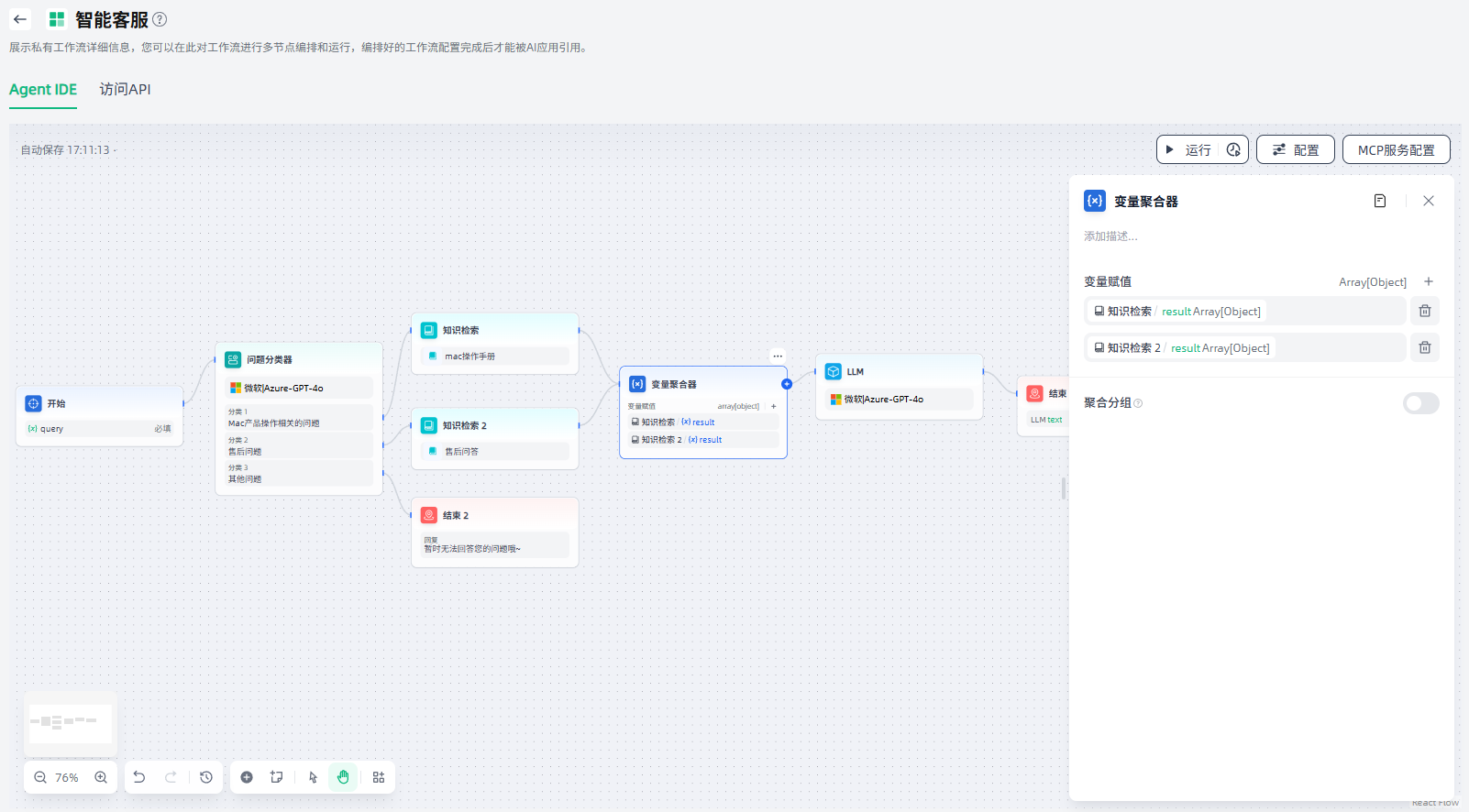
变量聚合器节点的配置步骤如下:
1.变量赋值:设置需要聚合的分支的变量。
注:变量聚合器只能聚合相同数据类型的变量,如果添加到变量聚合节点的第一个变量是数组类型,则后续变量将自动筛选并仅允许添加相同类型的变量。
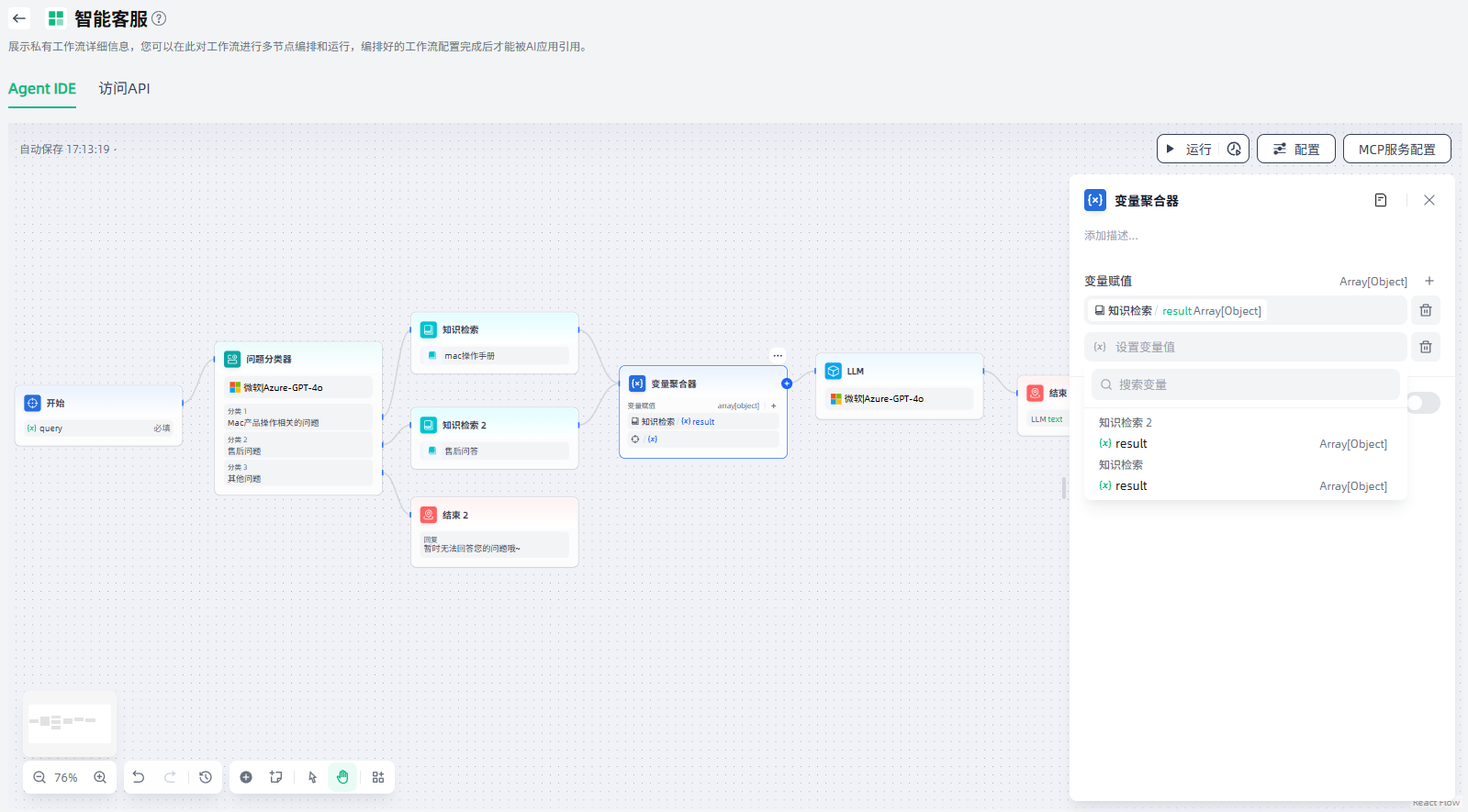
2.聚合分组:如果您的场景涉及聚合多组变量,打开此开关即可启用该功能。
注:使用变量聚合器聚合多组变量时,每组都只能聚合相同数据类型的变量。
文档提取器
由于LLM 自身无法直接读取或解释文档内容,因此需要通过文档提取器节点,解析并读取用户所上传文档中的信息,并将其转换为文本,然后将内容传递 LLM , 以实现对于文件内容的处理。
文档提取器节点可以理解为信息处理中心,它识别并读取输入变量中的文件,提取信息,并将其转换为字符串类型的输出变量,供下游节点调用。使用文档提取器节点,可以处理构建能够与文件进行互动的应用、分析并检查用户上传的文件内容等场景,仅能够提取文档类型文件中的信息,例如 TXT、Markdown、PDF、HTML、DOCX 格式文件的内容,无法处理图片、音频、视频等格式文件。
例如,在一个文件交互问答场景中,文档提取器节点可以作为 LLM 节点的前置步骤,提取文件信息并传递至下游的 LLM 节点,回答用户关于文件的问题。
使用文档提取器节点,需要设置输入变量,即用于文档提取的变量输入,输入变量支持两种数据结构的变量(File单个文件,Array[File]多个文件)。
参数提取器
工作流的某些节点需要特定的数据格式作为输入,而参数提取器节点可以从自然语言中推断和提取结构化参数,将用户的自然语言转换为可识别的参数,用于后续工具调用或HTTP请求等。
例如,在对话式Arxiv论文检索应用构建时,Arxiv论文检索工具需要论文作者或论文ID作为输入参数,通过使用参数提取器,从用户输入的自然语言中提取论文ID/作者,即可将论文ID/作者作为输入参数进行精确查询。
参数提取器节点的配置步骤如下:
1.设置输入变量:通常设置为用于参数提取的变量输入。
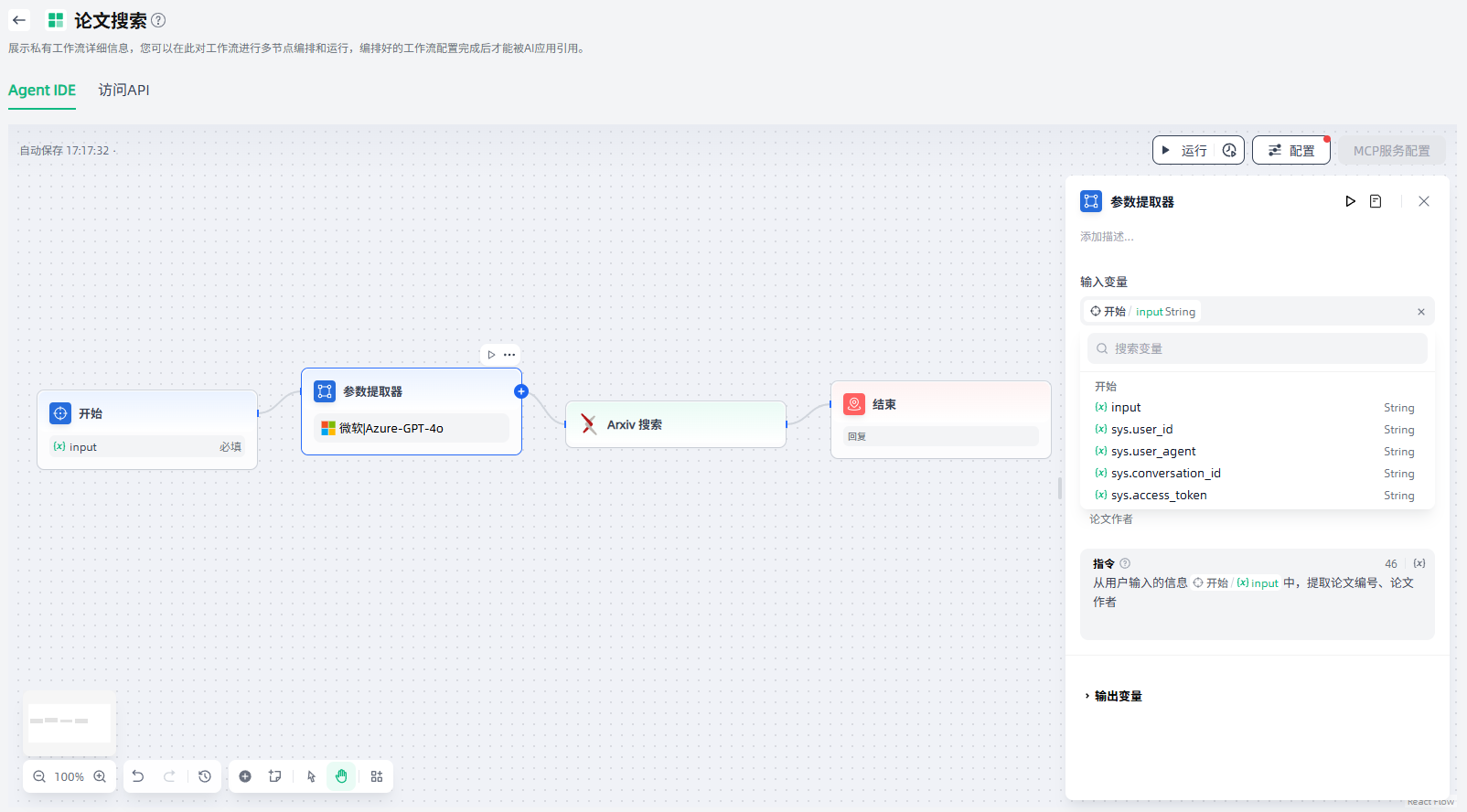
2.选择模型:参数提取器依赖于 LLM 的推理和结构化生成功能,根据您的场景需求选择一个合适的模型。
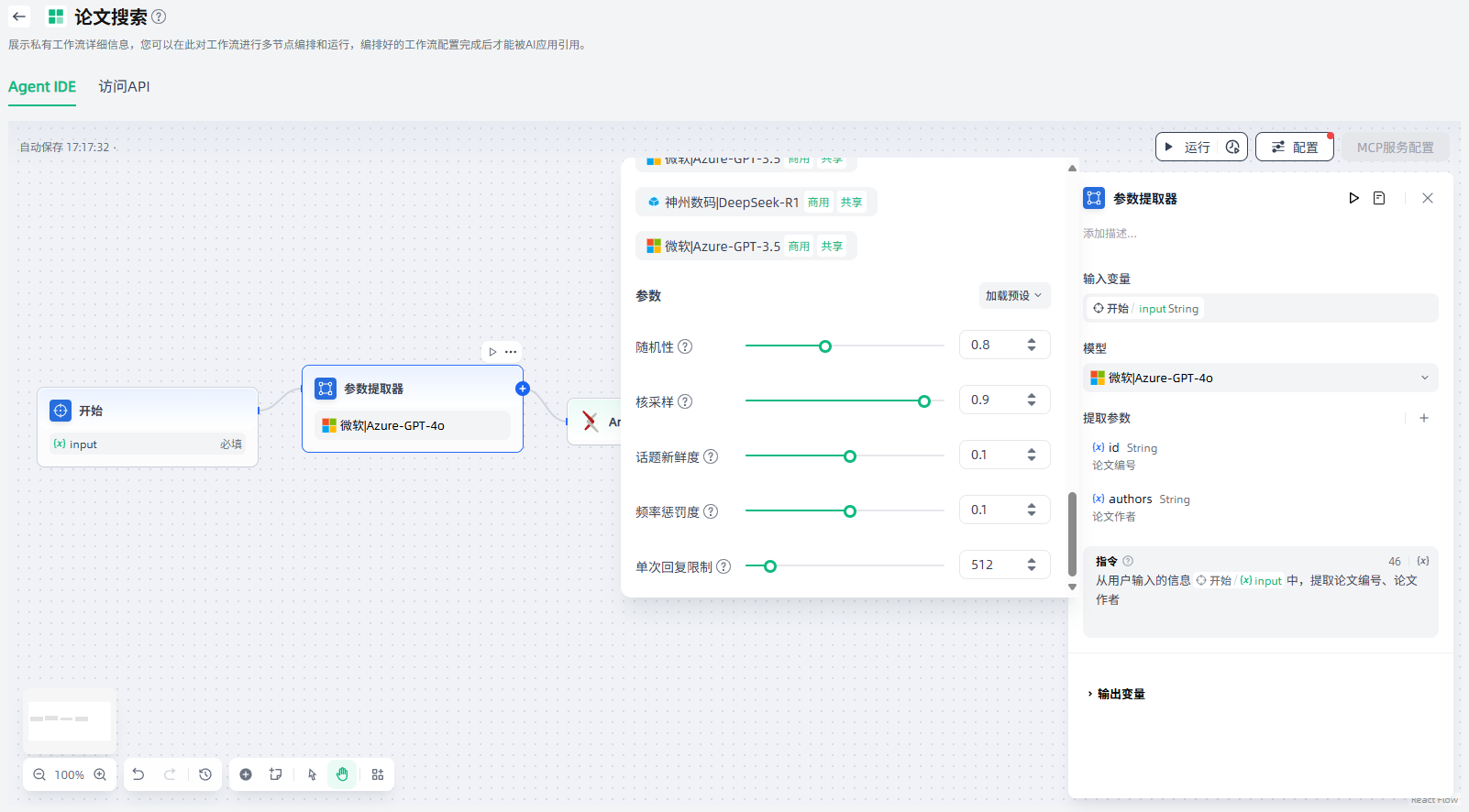
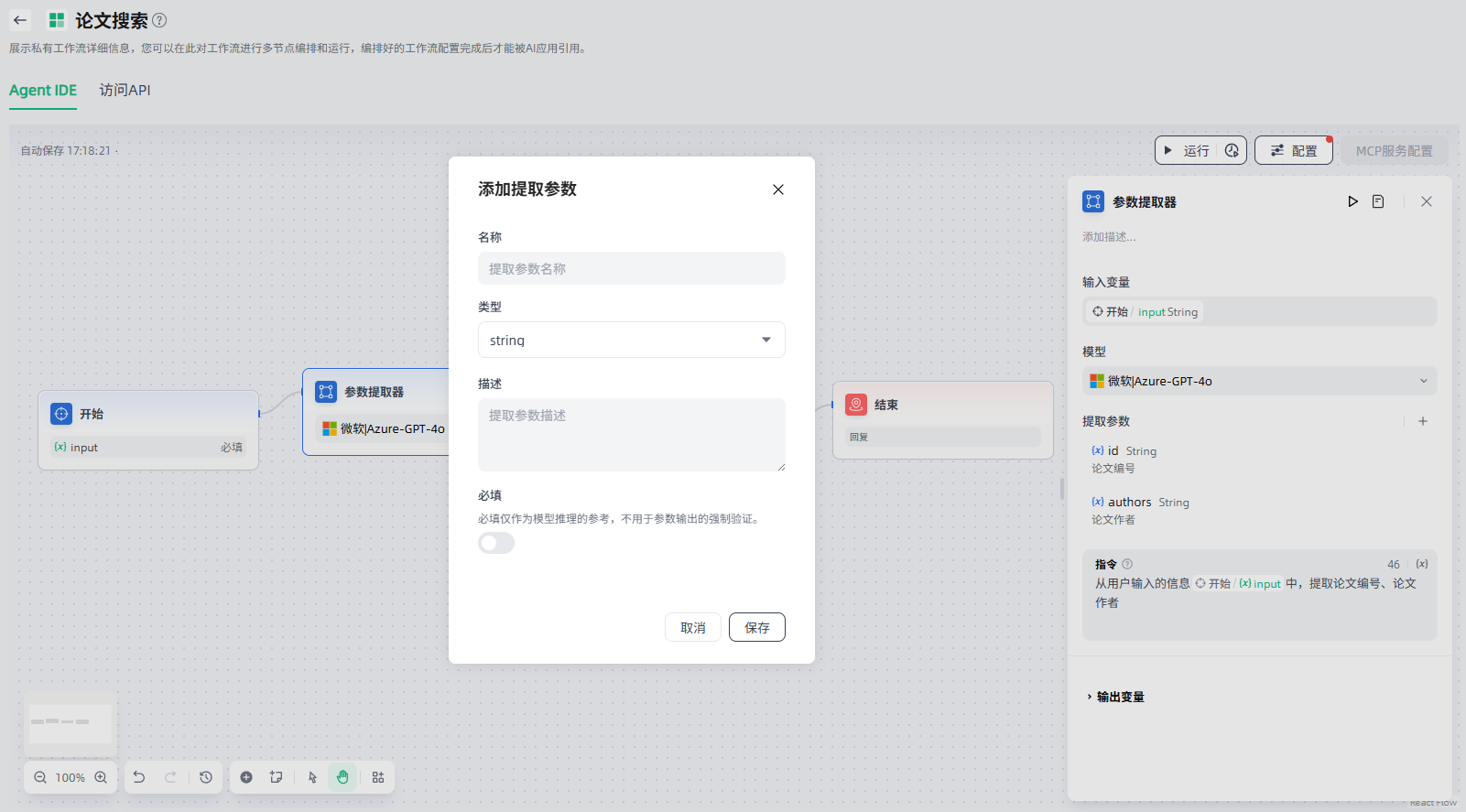
3.设置提取参数:需要定义要提取的参数及其类型,点击“+”进行添加。
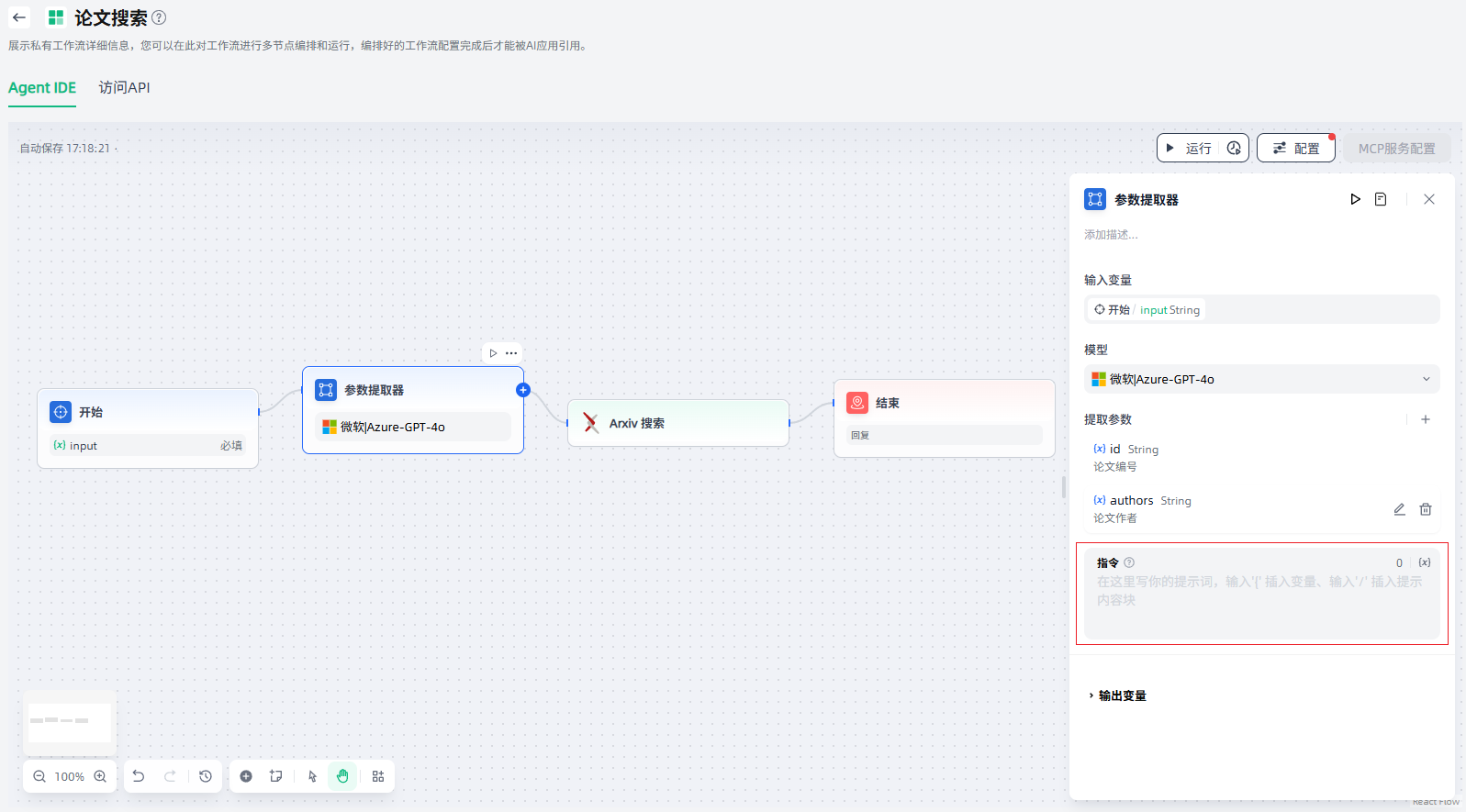
4.编辑指令:编辑提示词,帮助 LLM 提高提取复杂参数的有效性和稳定性。
HTTP请求
HTTP请求节点支持通过HTTP协议,向指定的Web地址发送服务器请求,实现与外部服务的互联互通,适用于获取外部数据、生成图片、下载文件等场景。
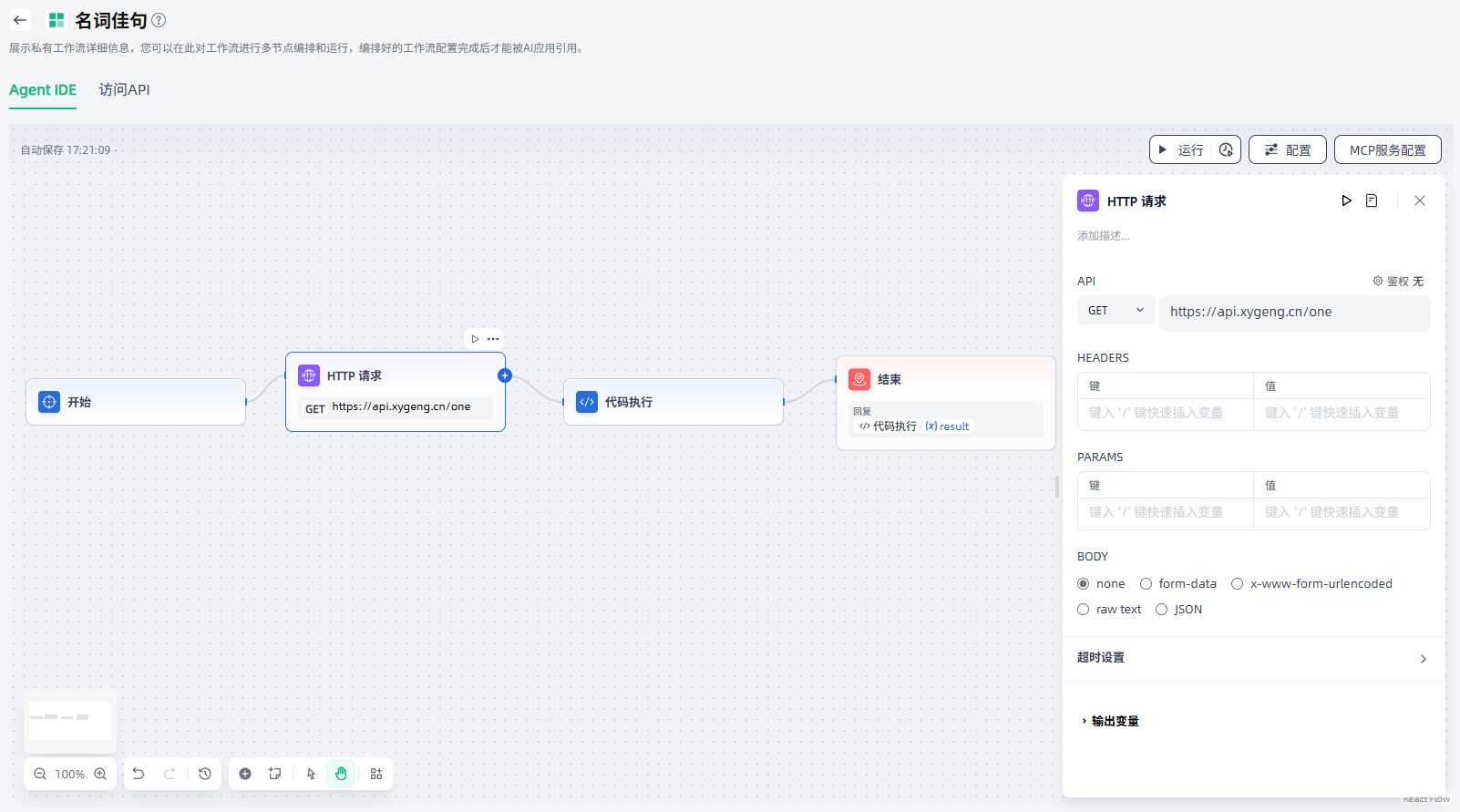
HTTP请求节点的配置步骤如下:
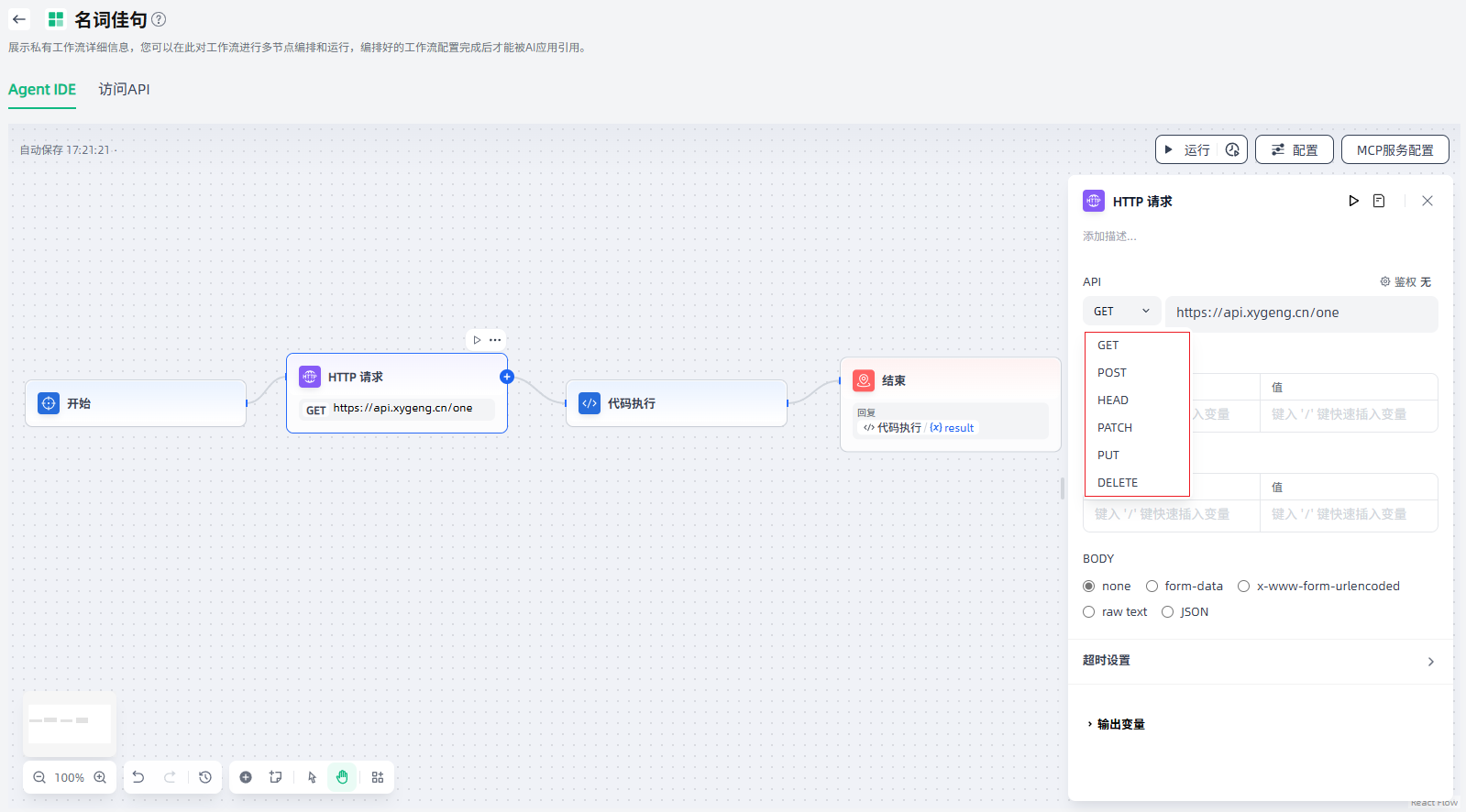
1.请求配置:HTTP请求节点支持GET、POST、HEAD、PATCH、PUT、DELETE 6种请求方式,您可以按需选择合适的请求方式,并配置HTTP请求的URL、请求头、查询参数等。
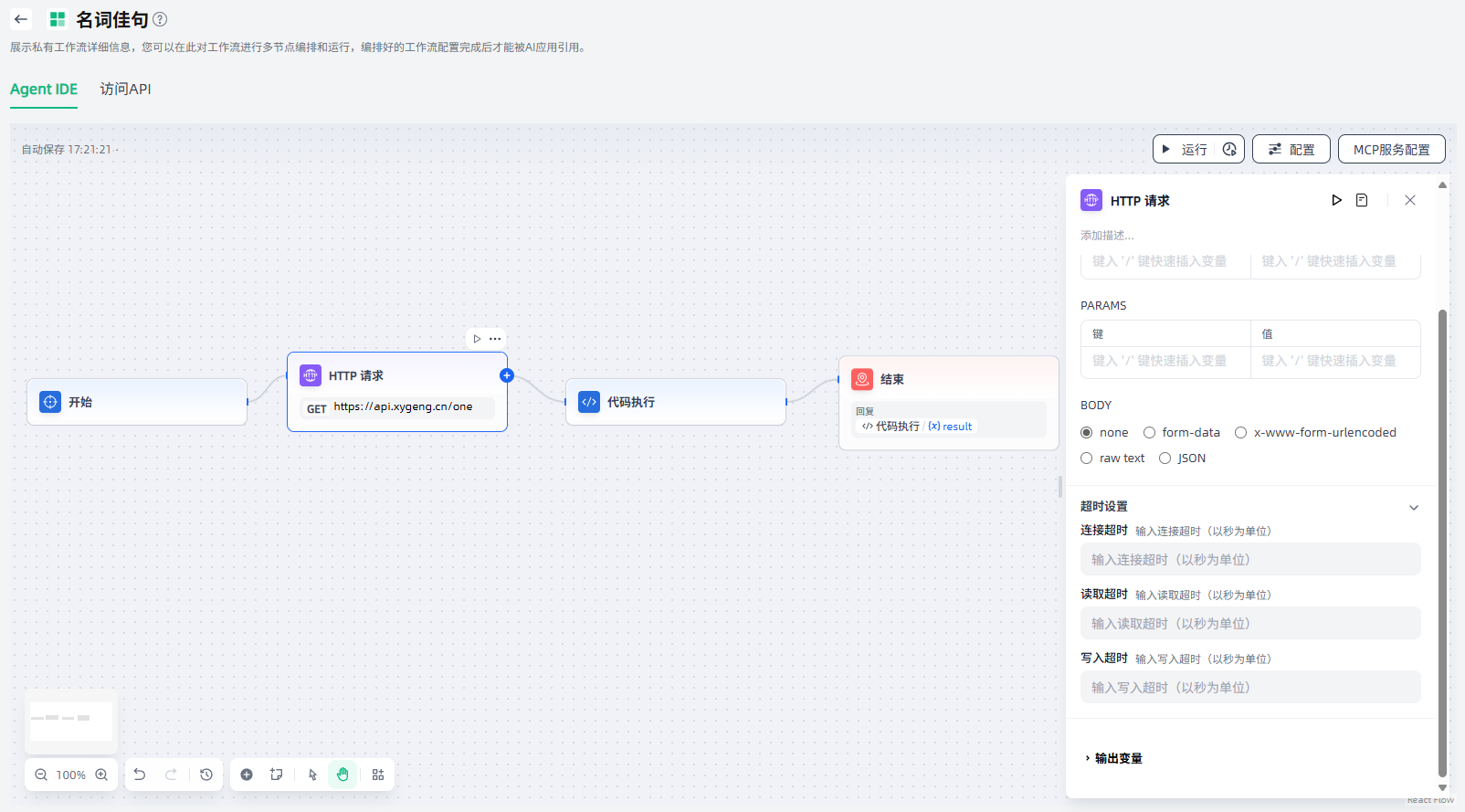
2.超时设置:您可以按需设置超时设置,包括输入连接超时、输入读取超时、输入写入超时。
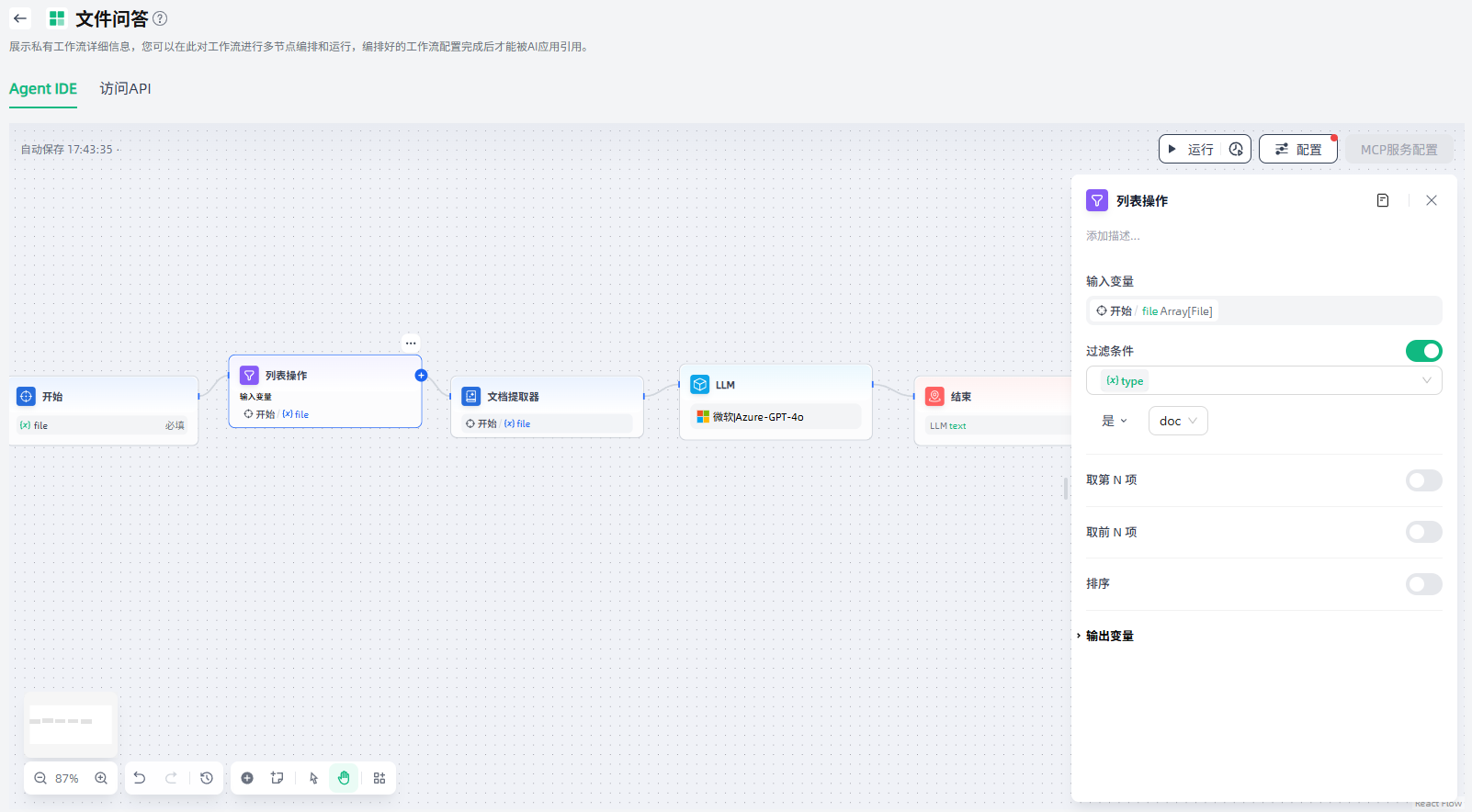
列表操作
由于开始节点的文件列表变量支持同时上传文档文件、图片、音频与视频文件等多种文件,当用户上传文件时,所有文件都存储在同一个 Array[File] 数组类型变量内,不利于后续单独处理文件。
列表操作节点可以对文件的格式类型、文件名、大小等属性进行过滤与提取,将不同格式的文件传递给对应的处理节点,以实现对不同文件处理流的精确控制。例如在一个应用中,允许用户同时上传文档文件和图片文件两种不同类型的文件,需要使用列表操作节点进行分拣,将不同的文件类型交由不同流程处理。
列表操作节点一般用于提取数组变量中的信息,通过设置条件将其转化为能够被下游节点所接受的变量类型。
列表操作节点的配置步骤如下:
1.设置输入变量:设置用于列表操作的变量输入。列表操作节点仅接受Array[string]、Array[number]、Array[file]这些数据结构变量。
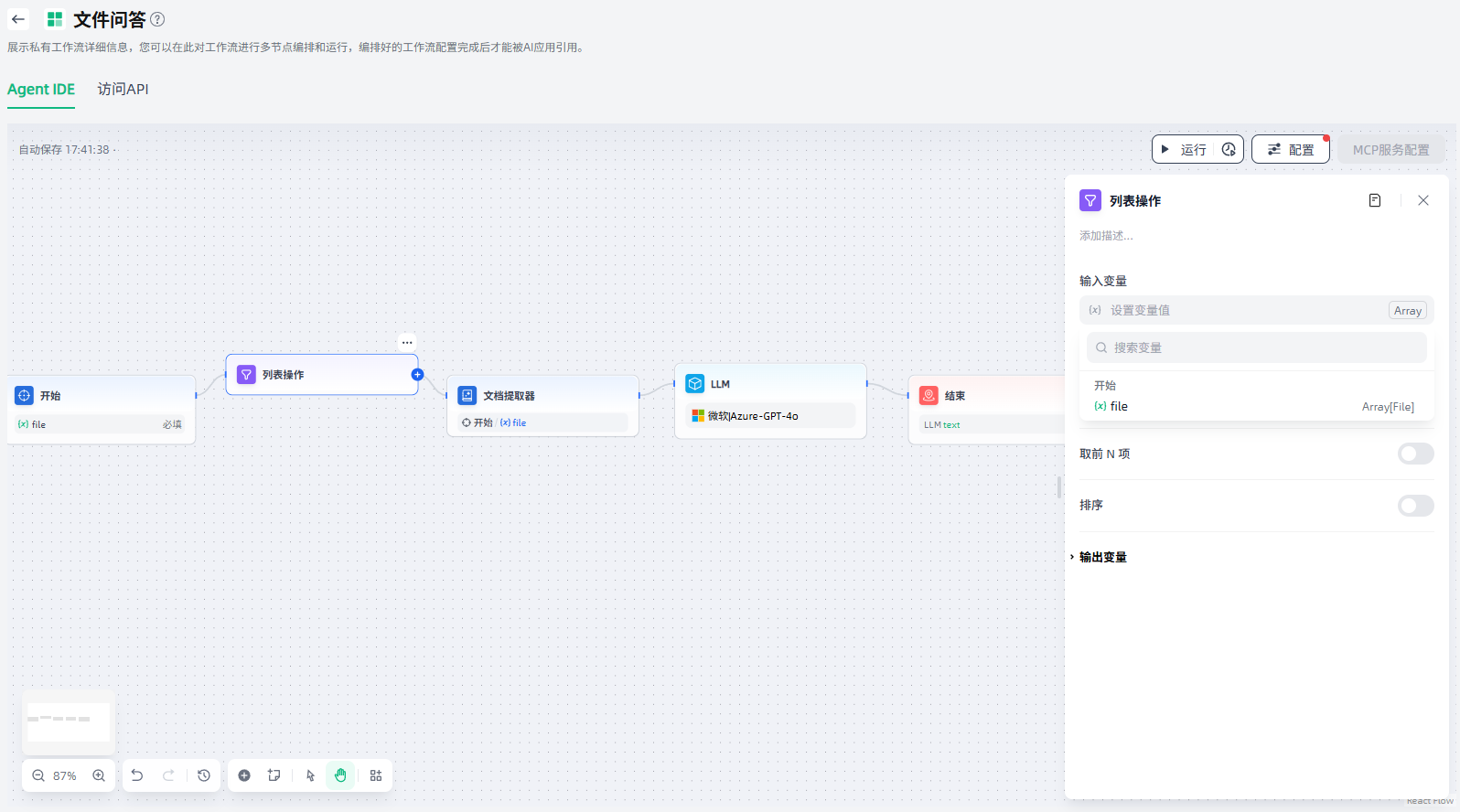
2.设置操作规则:按需设置过滤条件、取第 N 项、取前 N 项、排序。
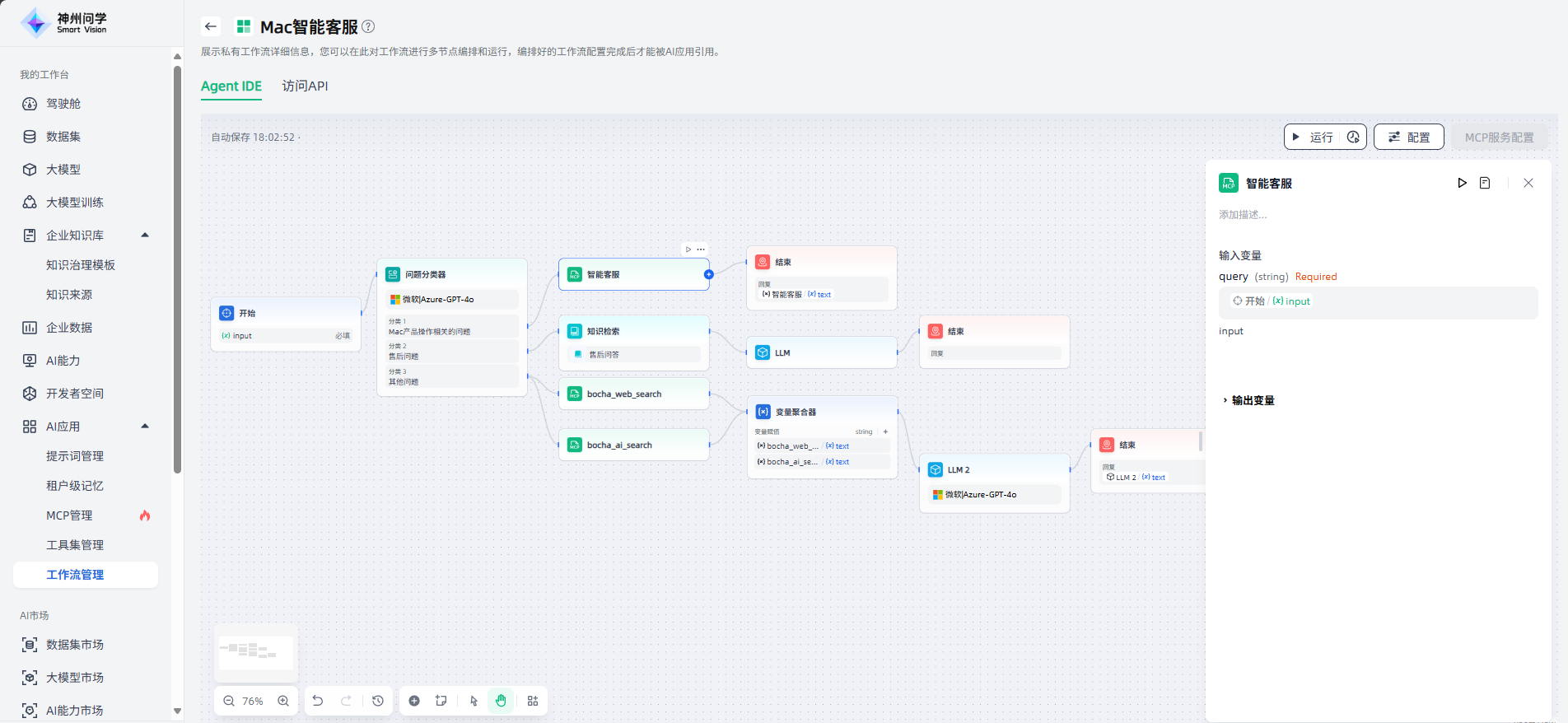
MCP服务
除上述节点外,工作流支持添加“我的工作台-AI应用-MCP管理”中的官方MCP服务和自定义MCP服务,作为工作流程中的节点,满足您更丰富的应用场景。
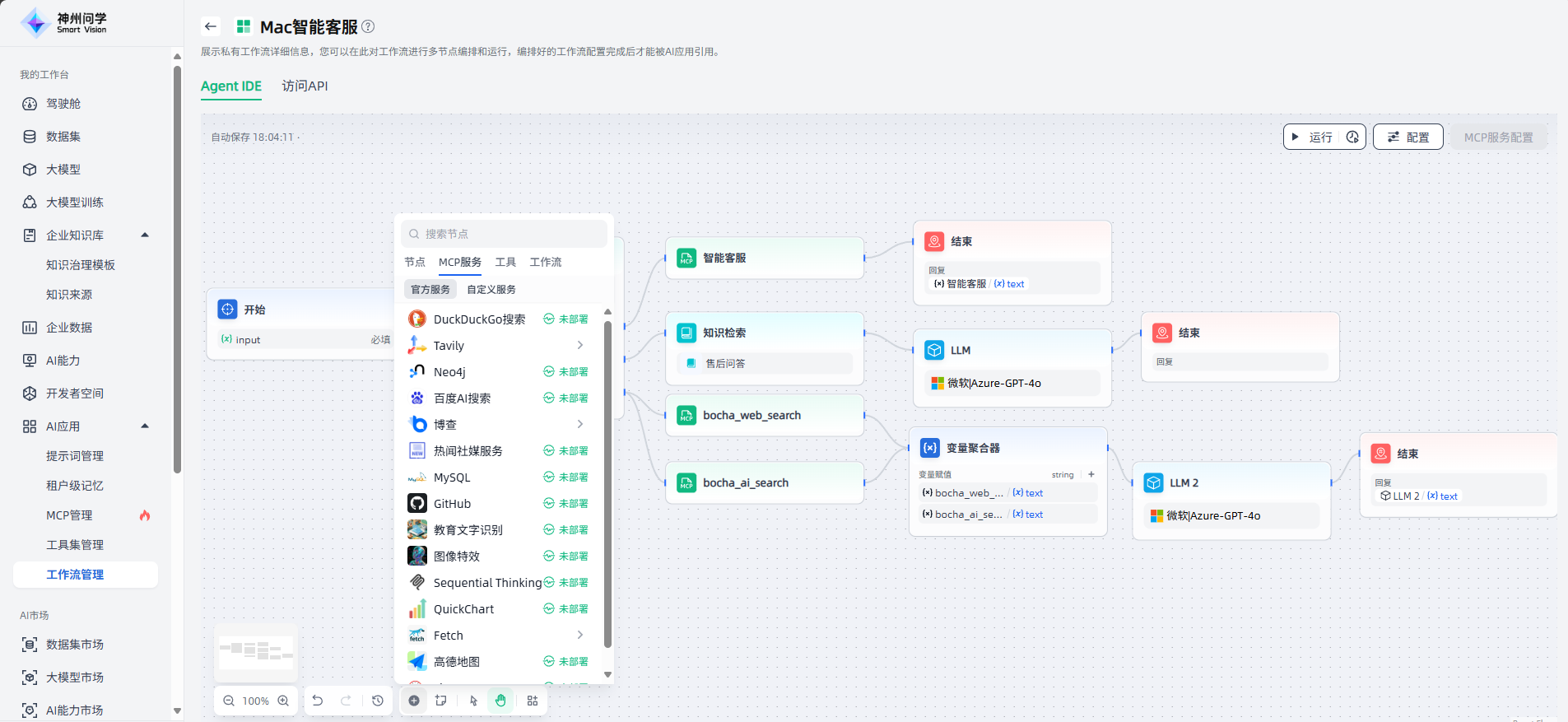
如需使用MCP服务作为节点,需要添加对应的MCP服务的API,按需设置授权、并进行部署后,设置该MCP服务节点的输入变量。如以下场景的工作流中,使用了自定义MCP服务“智能客服”、以及官方MCP服务“bocha”,满足该智能客服场景的需求。
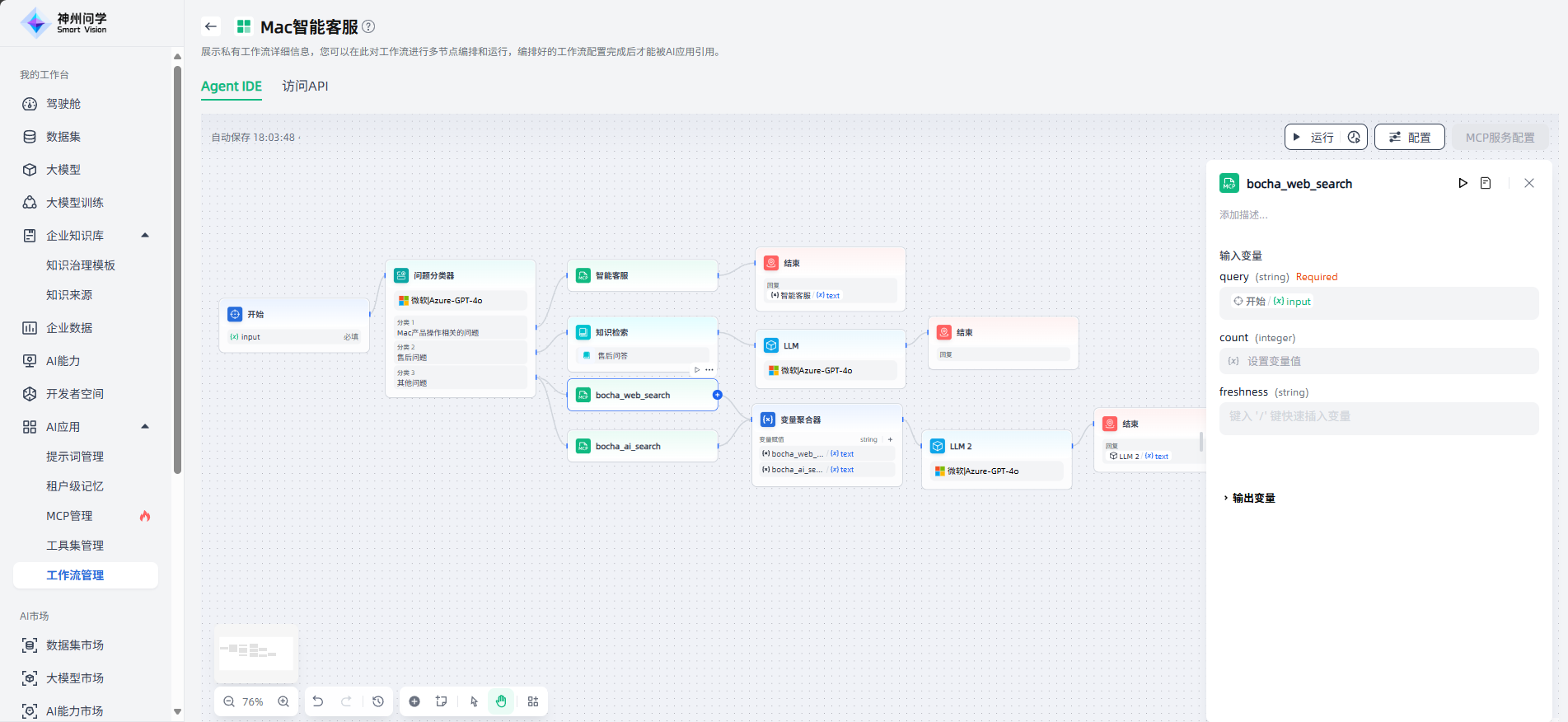
工具
除上述节点外,工作流支持添加“我的工作台-AI应用-工具集管理”中的外部插件或内部工具、作为工作流程中的节点,便于您编排更丰富的工作流。
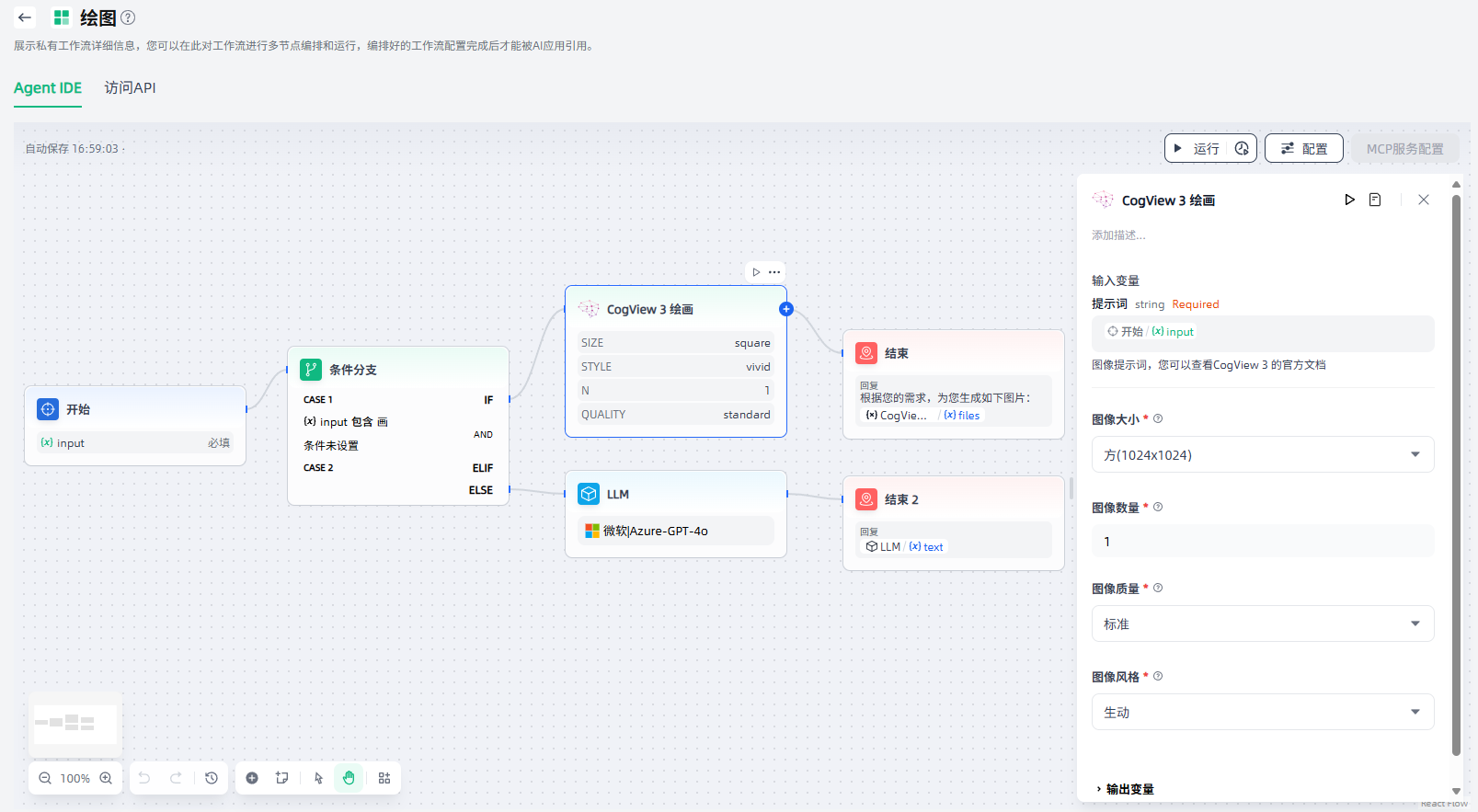
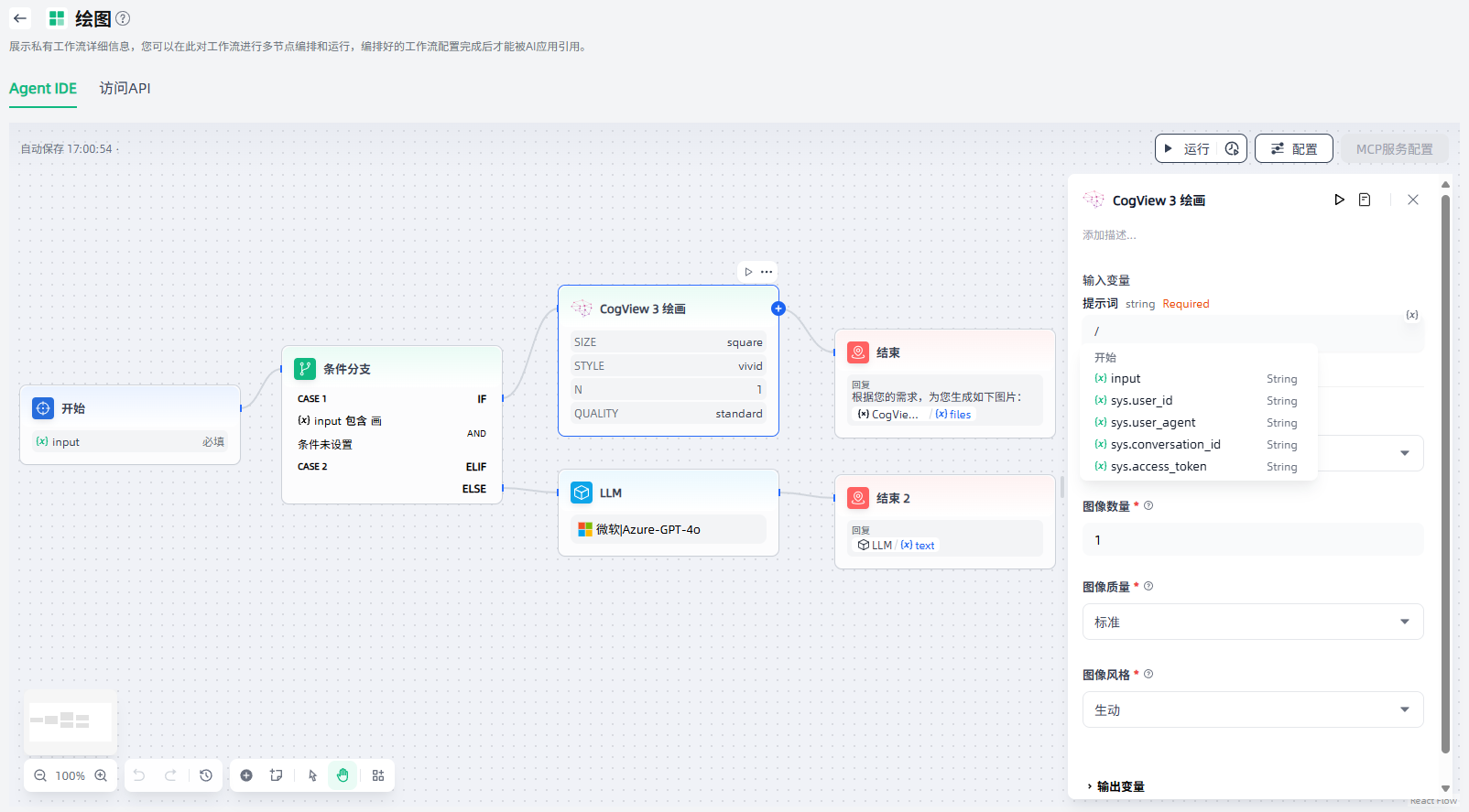
如需使用工具作为节点,需要添加对应的工具,并设置输入变量、工具参数等。以CogView 3为例,配置步骤如下:
1.设置输入变量:CogView 3生成图像的提示词。
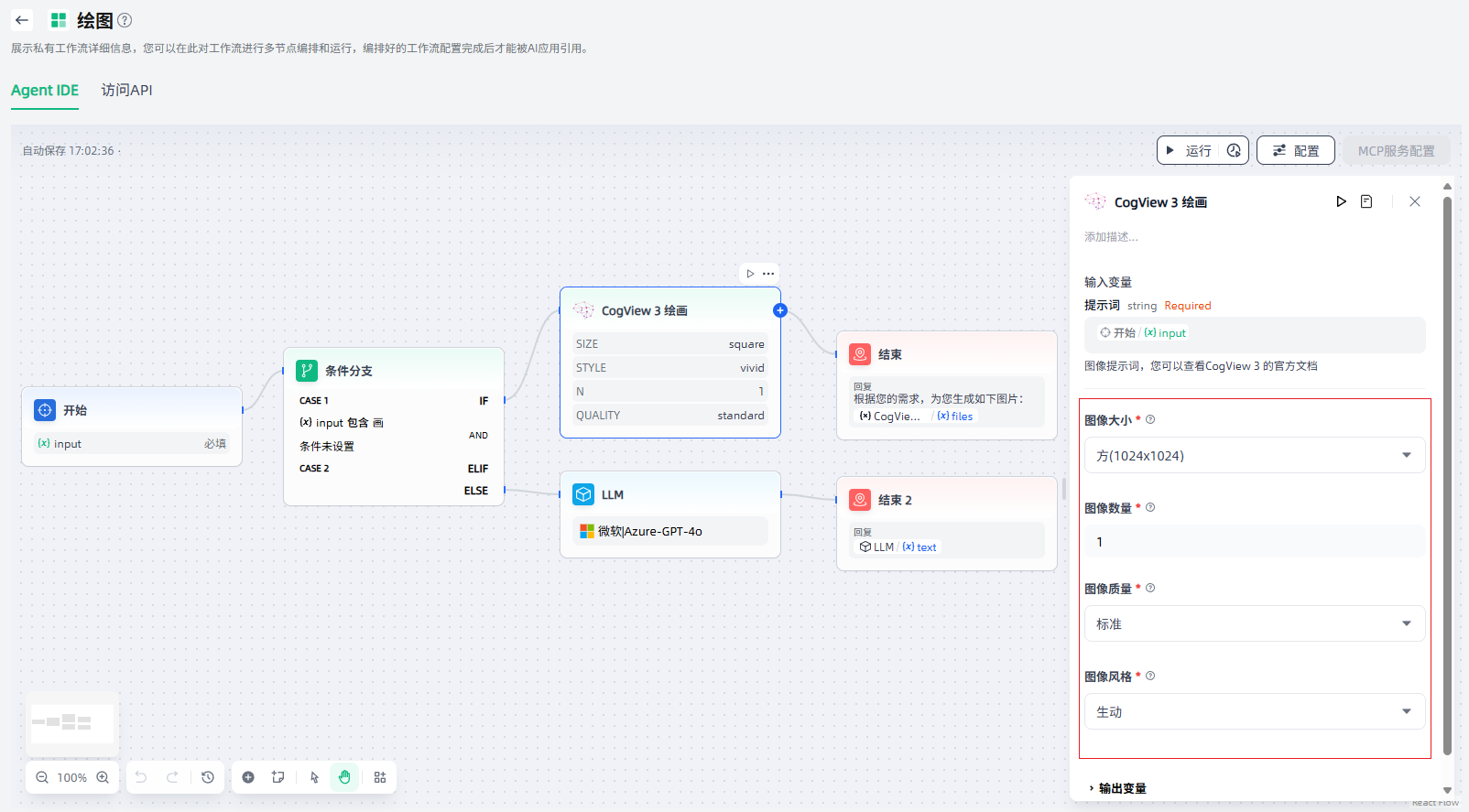
2.设置工具参数:CogView 3生成的图像的大小、风格等。
工作流
除上述节点外,工作流支持添加“我的工作台-AI应用-工作流管理”中“已配置”状态的工作流、作为工作流程中的节点,满足您更丰富的应用场景。
在如下场景的工作流中,嵌入了已配置的“多渠道信息获取”工作流,如果用户输入的是品牌咨询相关问题,会执行多渠道信息获取工作流、获取其输出结果。
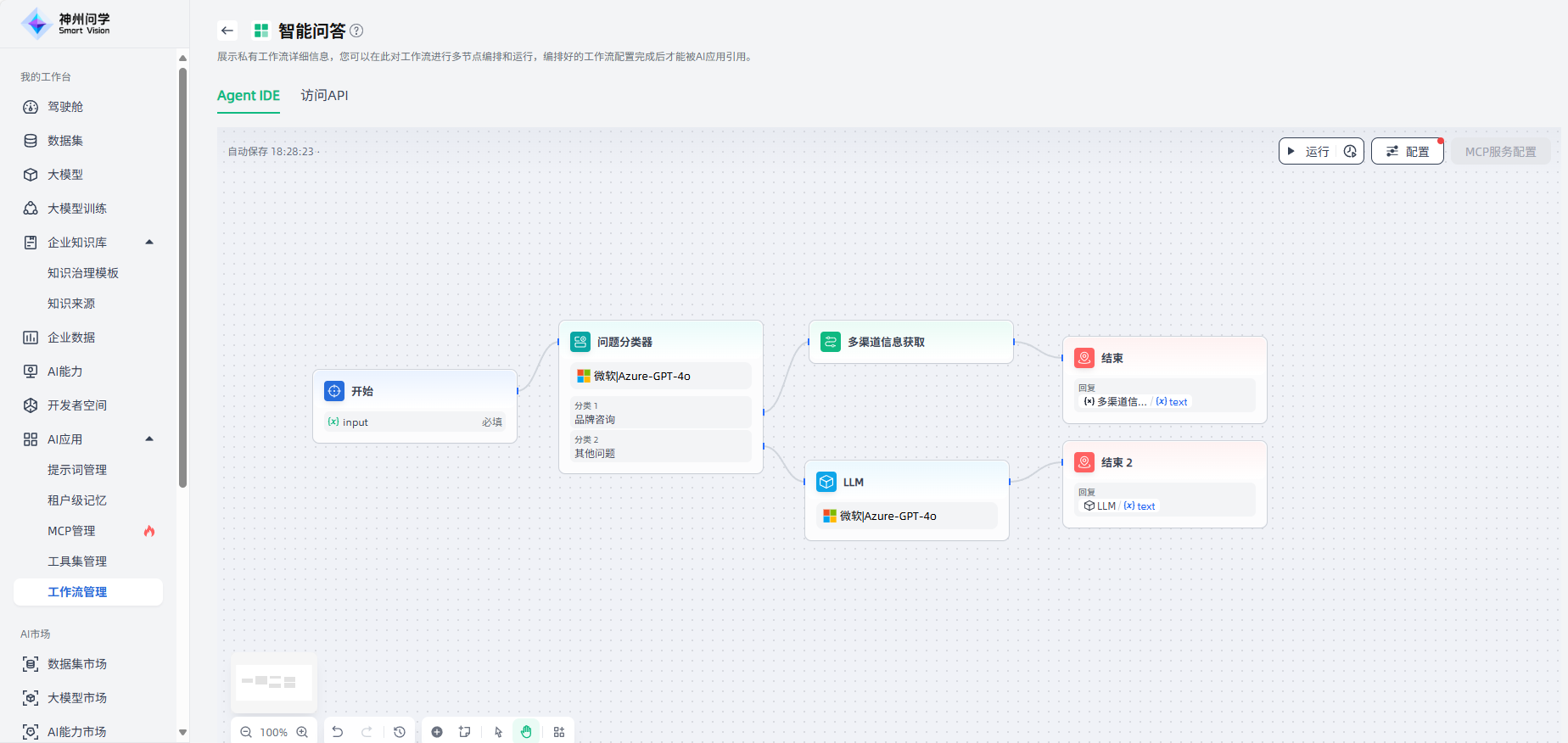
如需使用工作流作为节点,需要添加对应的工作流,并设置其输入变量。
创建工作流
在我的工作台-AI应用-工作流管理,点击右上角的“创建工作流”或“导入工作流”按钮,可以创建您的私有工作流。
点击“创建工作流”按钮时,您可以灵活依据节点类型构建多样化的工作流,以满足不同业务需求。
操作指南

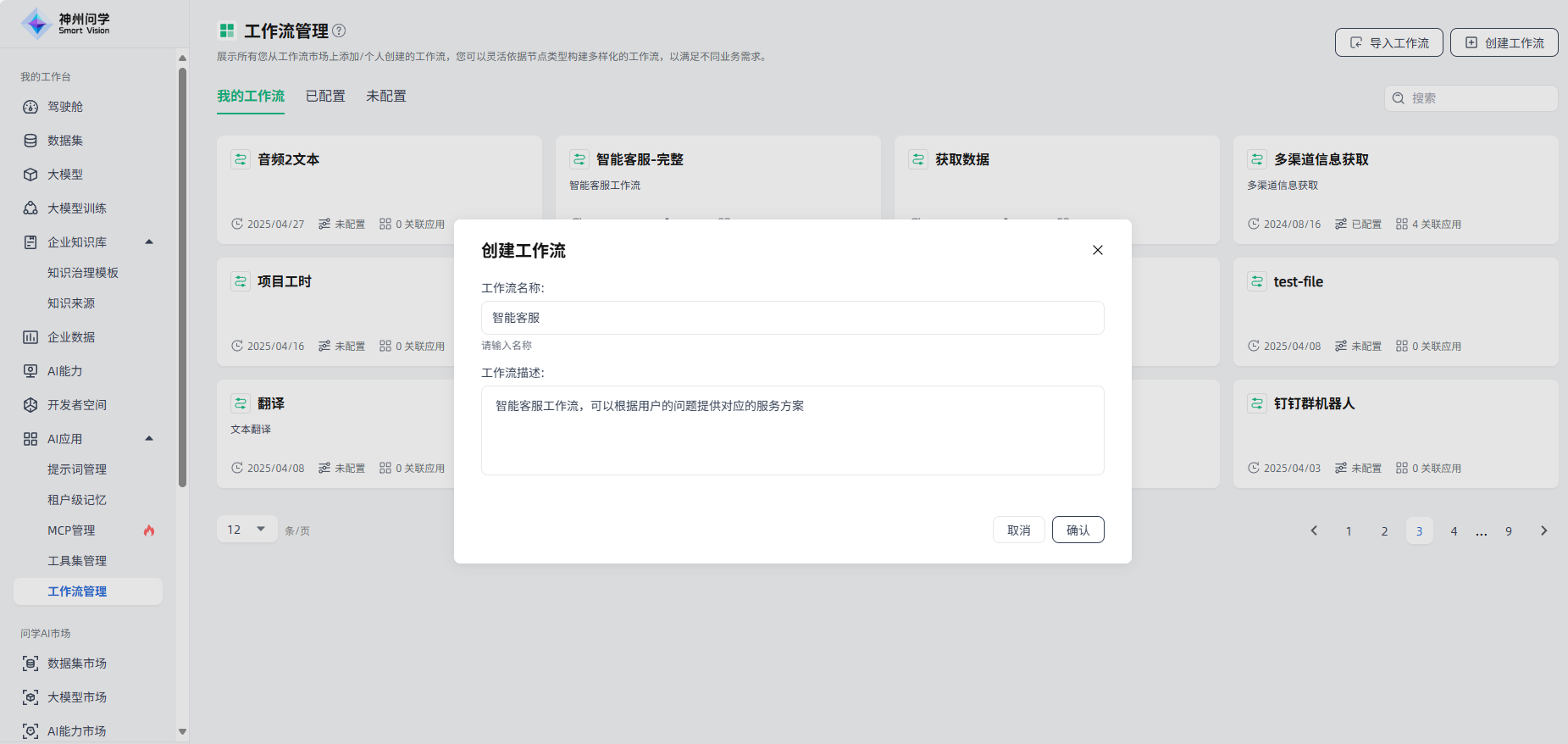
开始:进入“我的工作台-AI应用-工作流管理”,点击右上角“创建工作流”按钮,进入”创建工作流“页面。
填写工作流名称及描述:为您创建的工作流编辑名称、并进行描述,点击”确认“按钮,开始创建工作流。
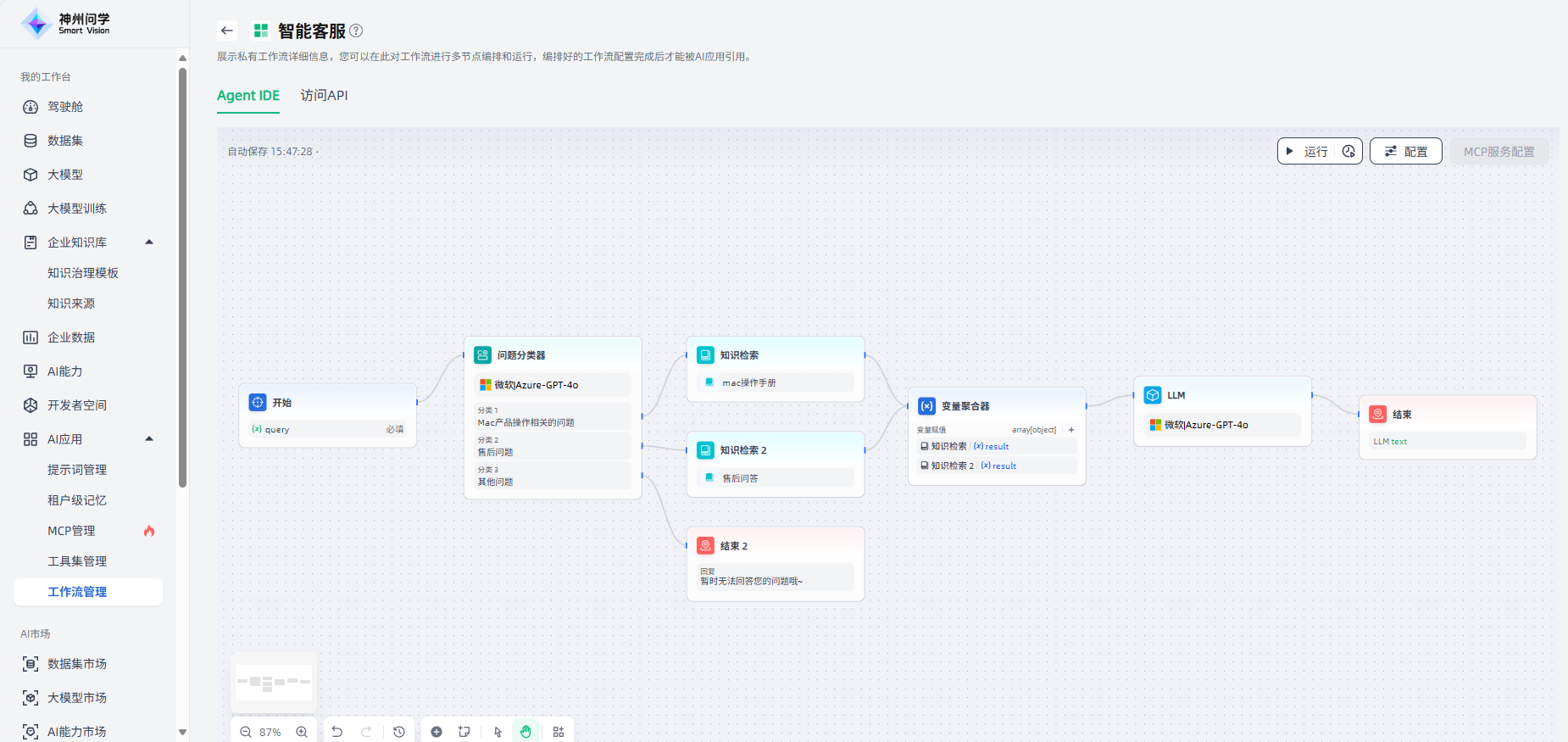
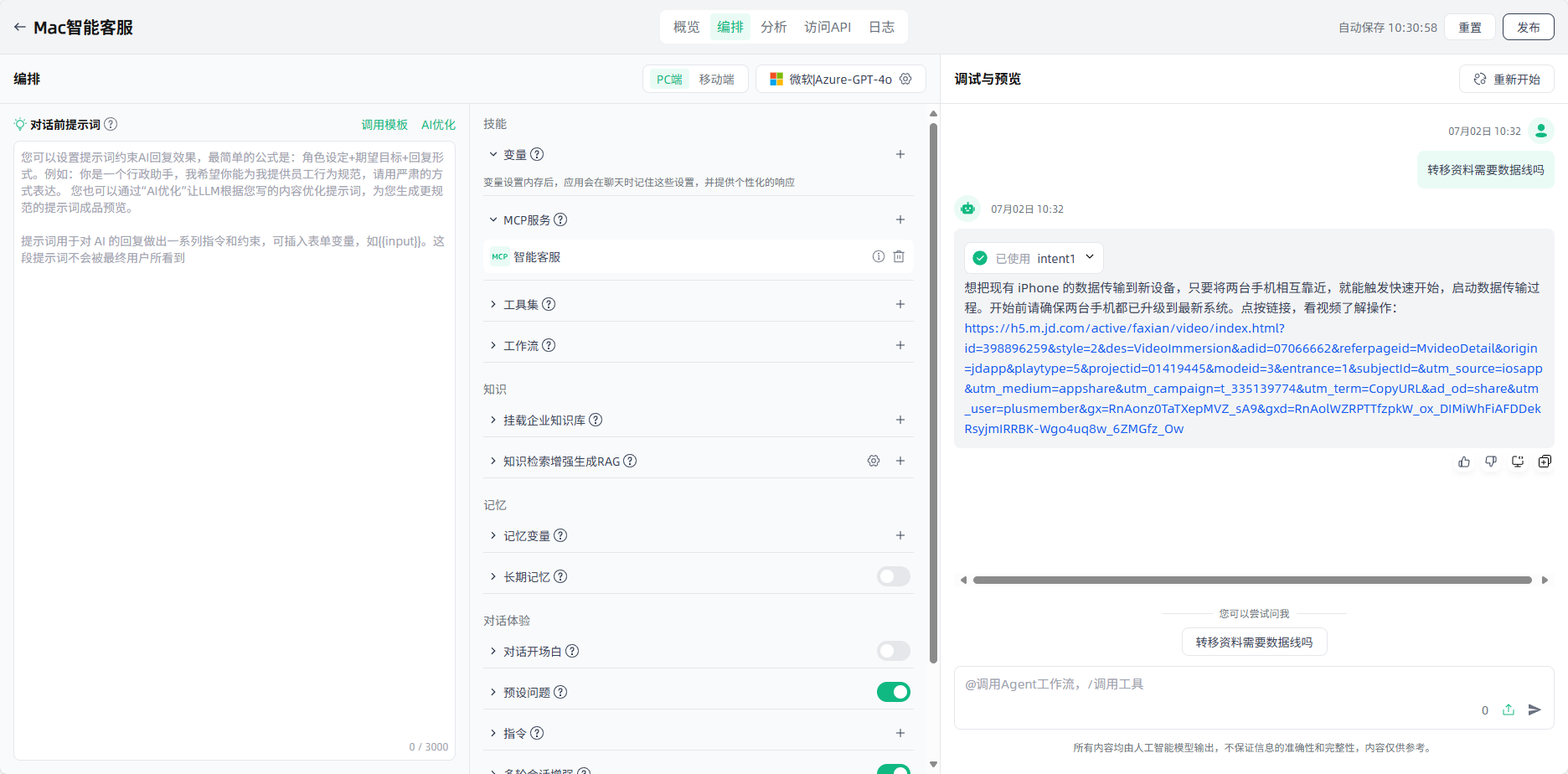
工作流编排:开始创建后自动进入“工作流详情”页面的工作流编排界面,且画布中自动出现“开始”节点,在此您可以按需灵活编排您的工作流。以智能客服场景为例:
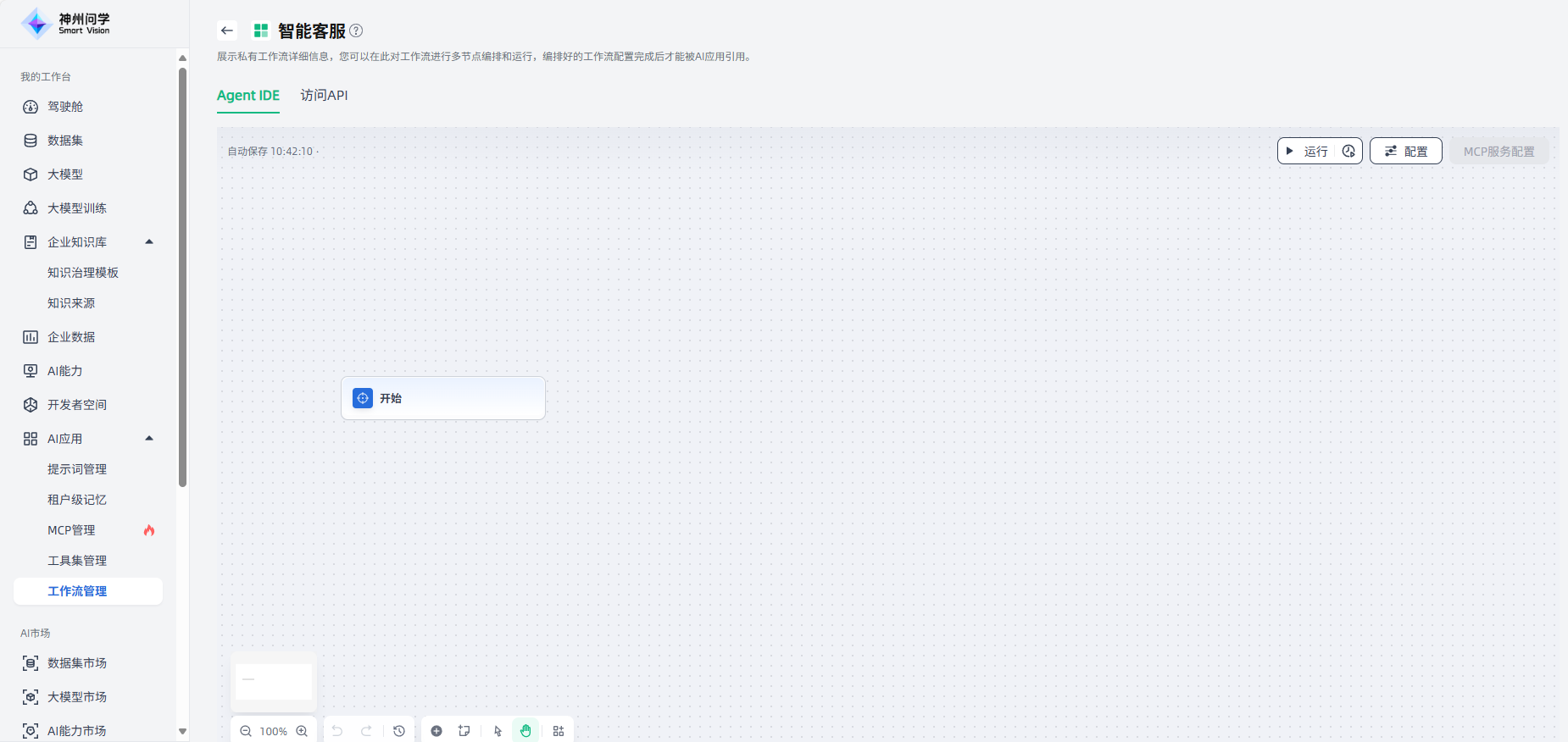
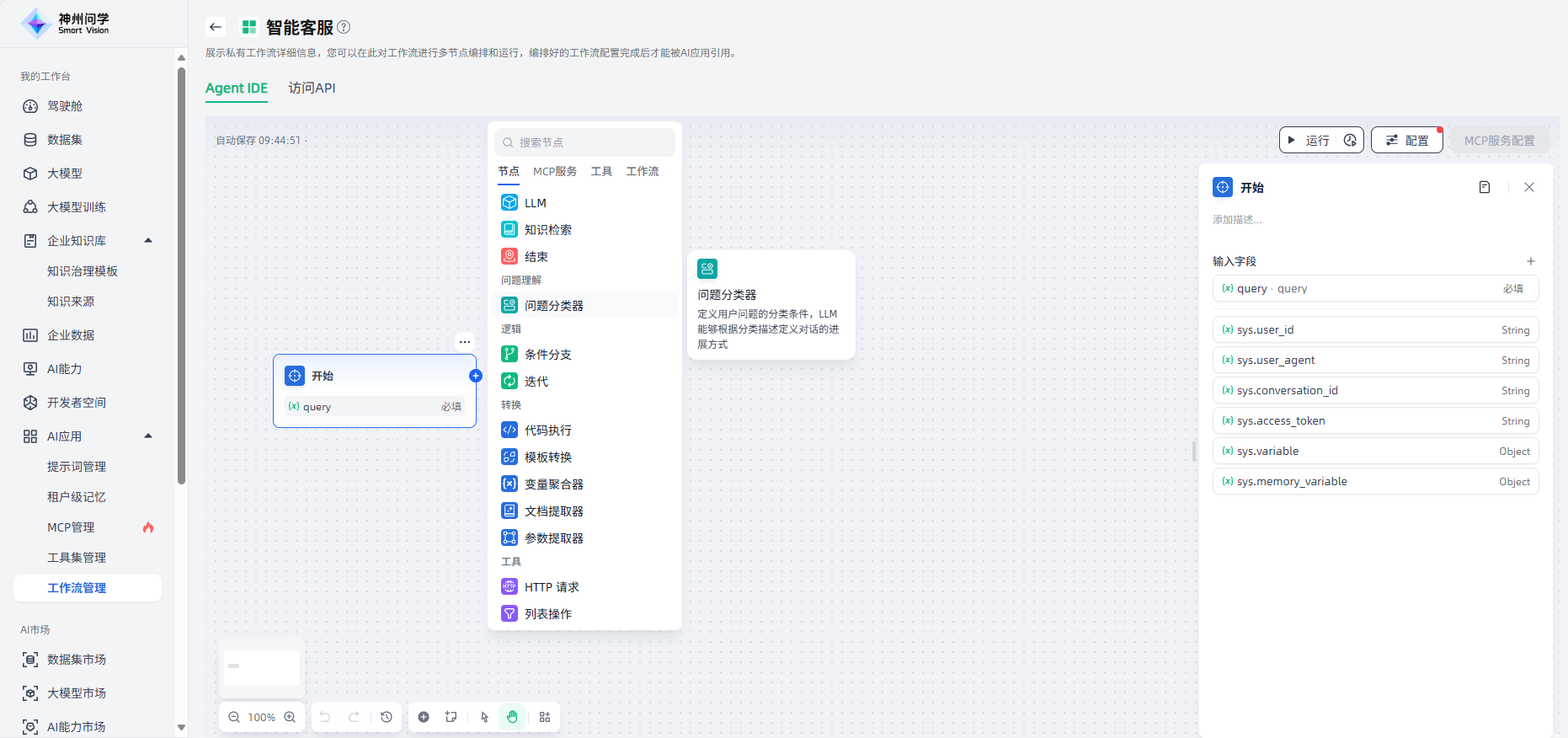
首先,点击“开始”节点,右侧出现配置界面,可以按需为此节点添加描述、变量。点击“+”添加变量,添加完成后点击“保存”,即完成了开始节点的配置。
由于用户输入的问题多种多样,在“开始”节点后添加“问题分类器”节点,便于对用户输入的问题进行分类,在后续流程中准确响应用户的问题。
点击“开始”节点的“+”或者画布下方“+”,选择“问题分类器”,画布上即出现了该节点,需要将该节点与上游的“开始”节点连接起来,点击该节点进行节点描述、输入变量、模型选择、分类等相关配置。
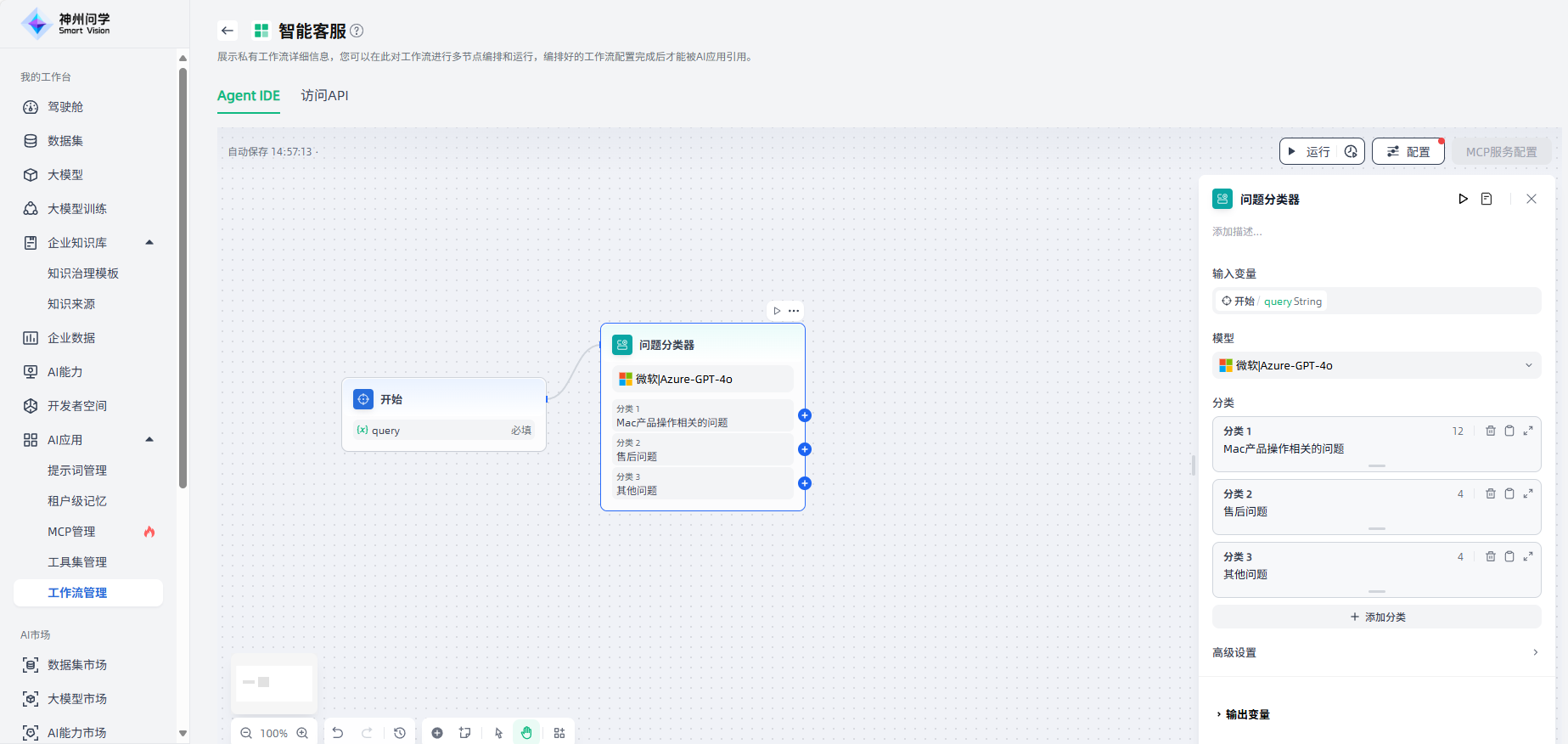
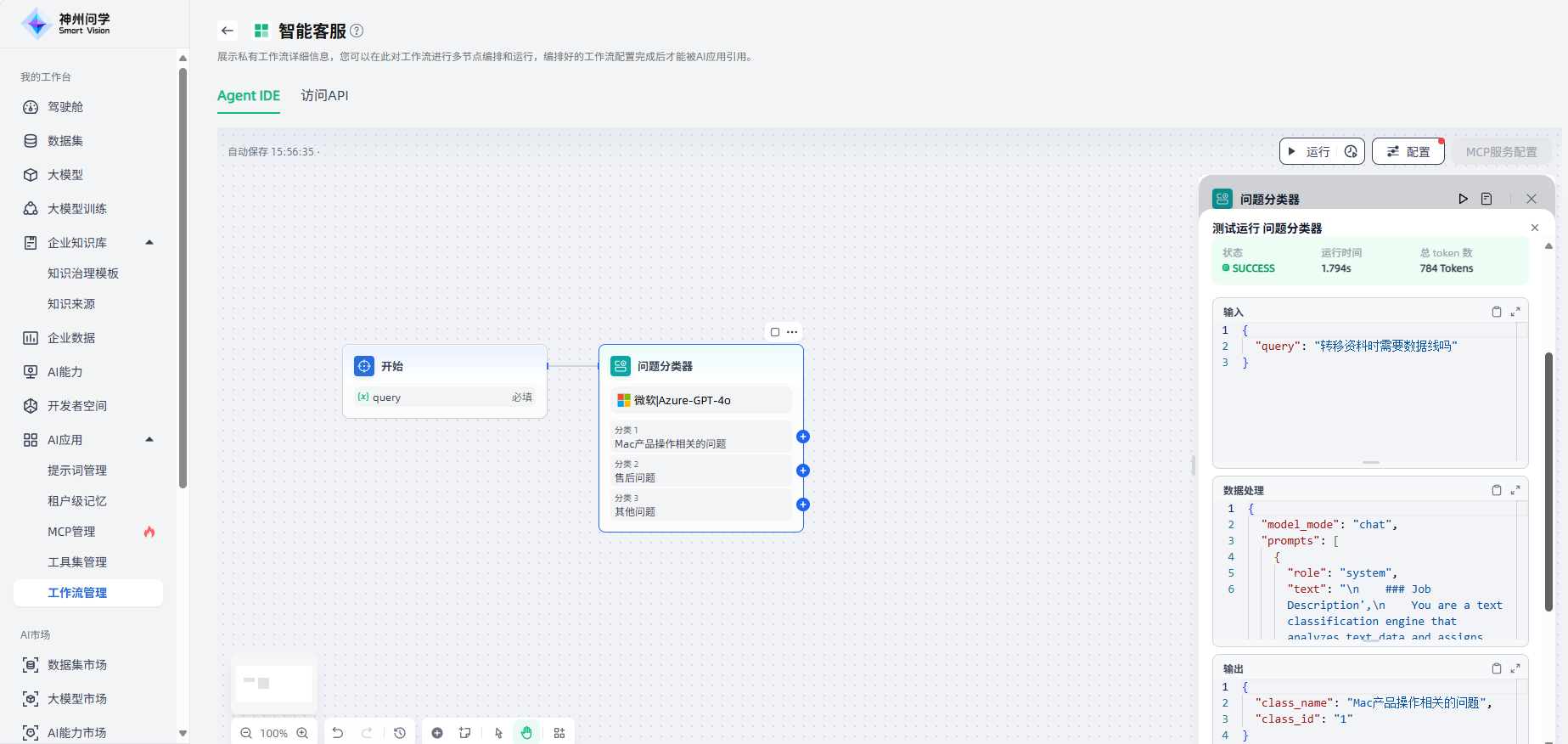
配置完成后,可以点击该节点右上角或该节点配置界面右上角的运行按钮,运行查看此节点的效果。
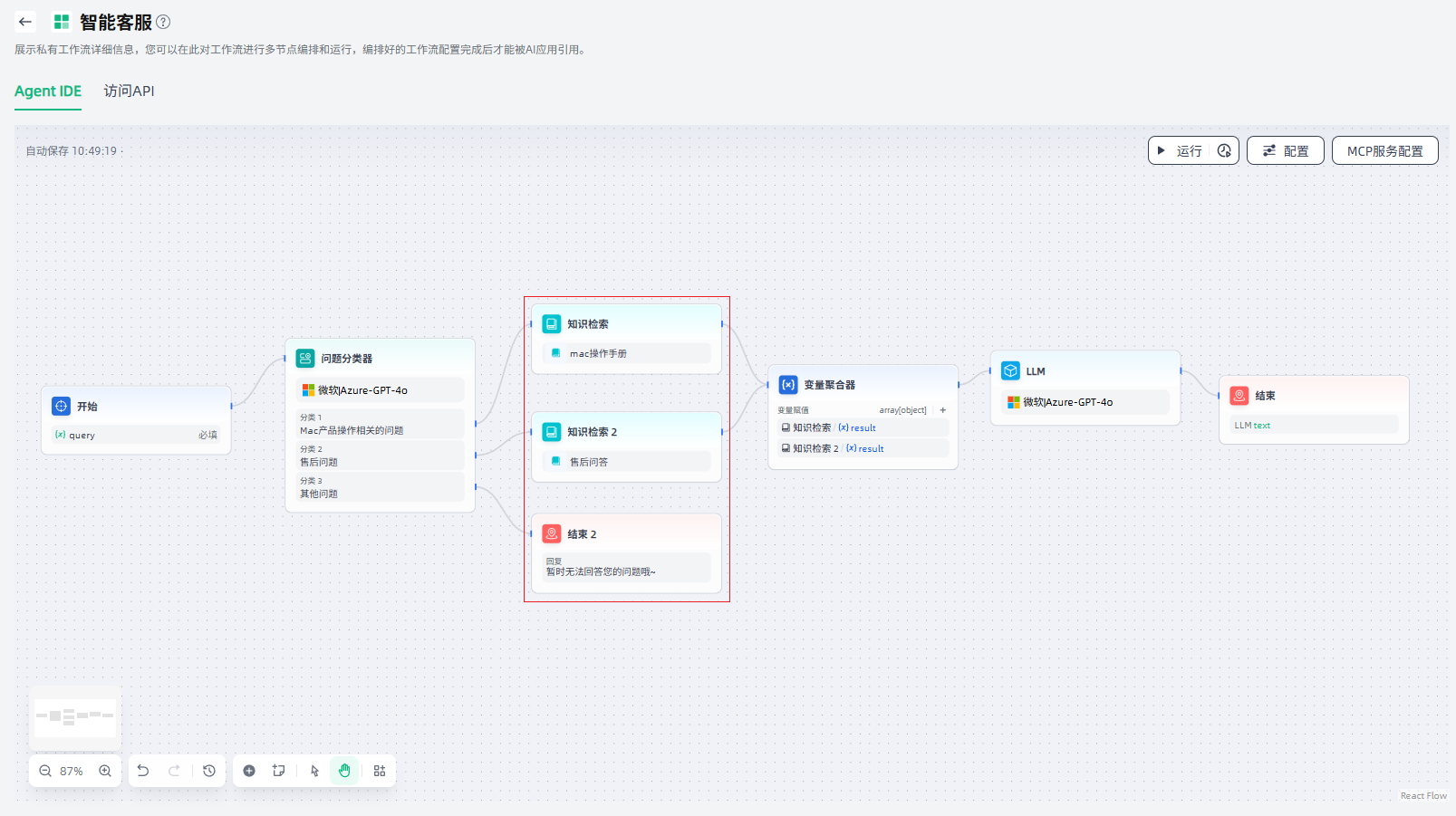
对于分类一产品操作相关问题,添加知识检索节点,便于针对此类问题通过知识库检索进行查询。添加“知识检索”节点后,将其与上游节点连接起来,点击该节点进行节点描述、查询变量、召回设置、RAG选择、知识库添加等相关配置。
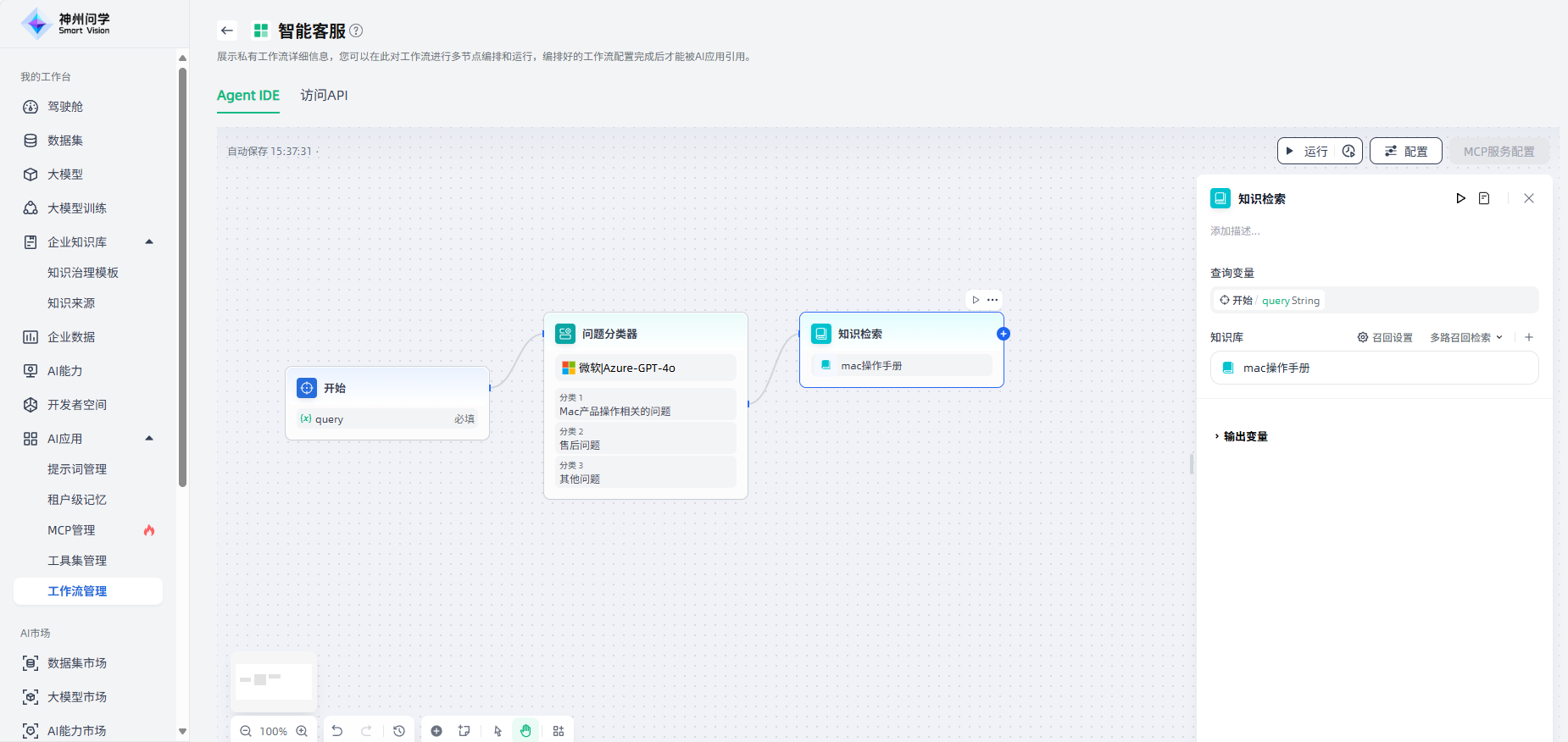
知识检索的下游节点一般是LLM节点,知识检索的输出变量需要在LLM节点内的上下文变量中进行配置。在用于分类问题一的知识检索节点后,添加“LLM”节点,将其与上游节点连接起来,点击该节点进行节点描述、模型选择、上下文等相关配置。
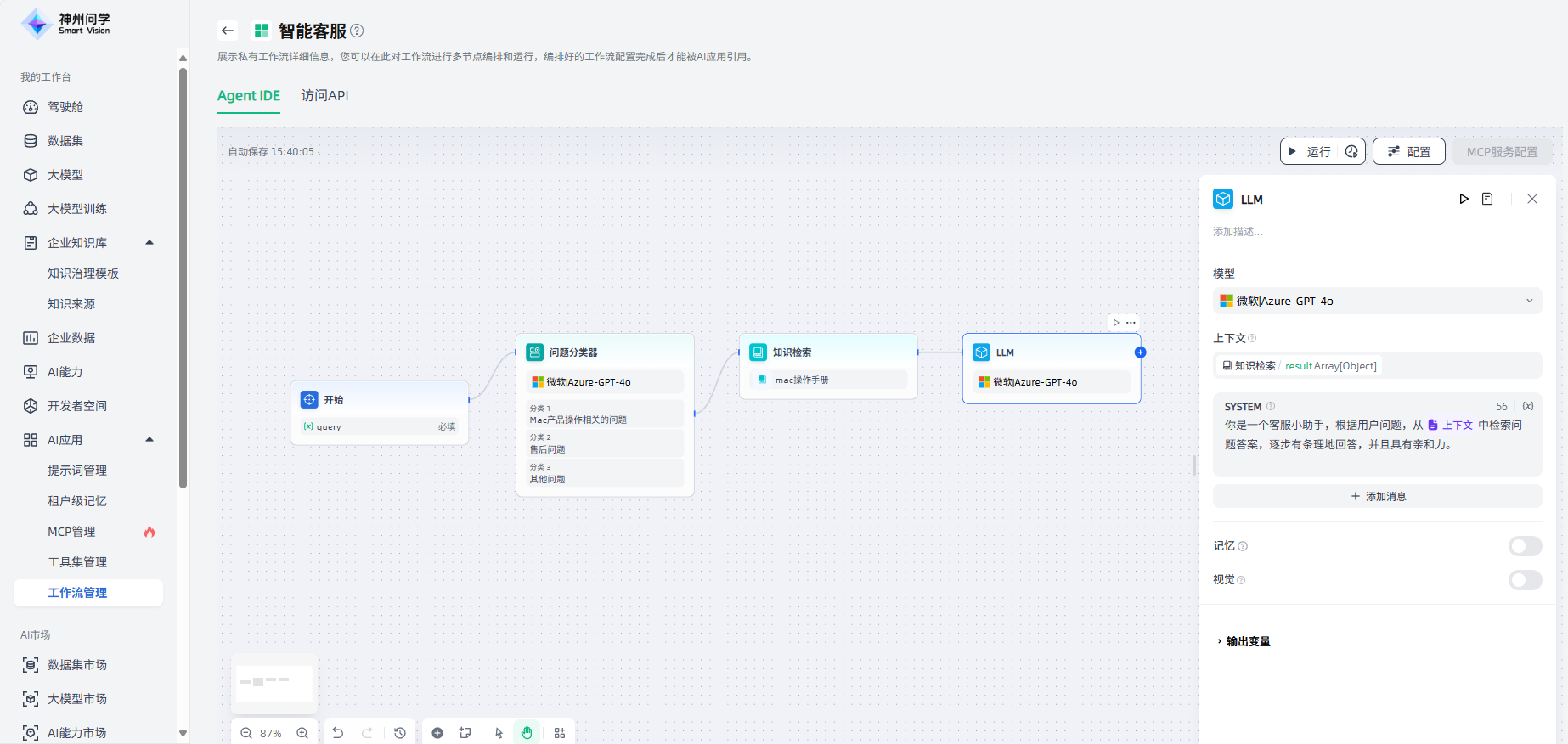
在LLM节点后,添加“结束”节点来输出最终结果,问题分类一的工作流程即设置完成。结束节点支持两种回答模式:①返回变量,由大模型生成回答;②使用设定的内容直接回答。
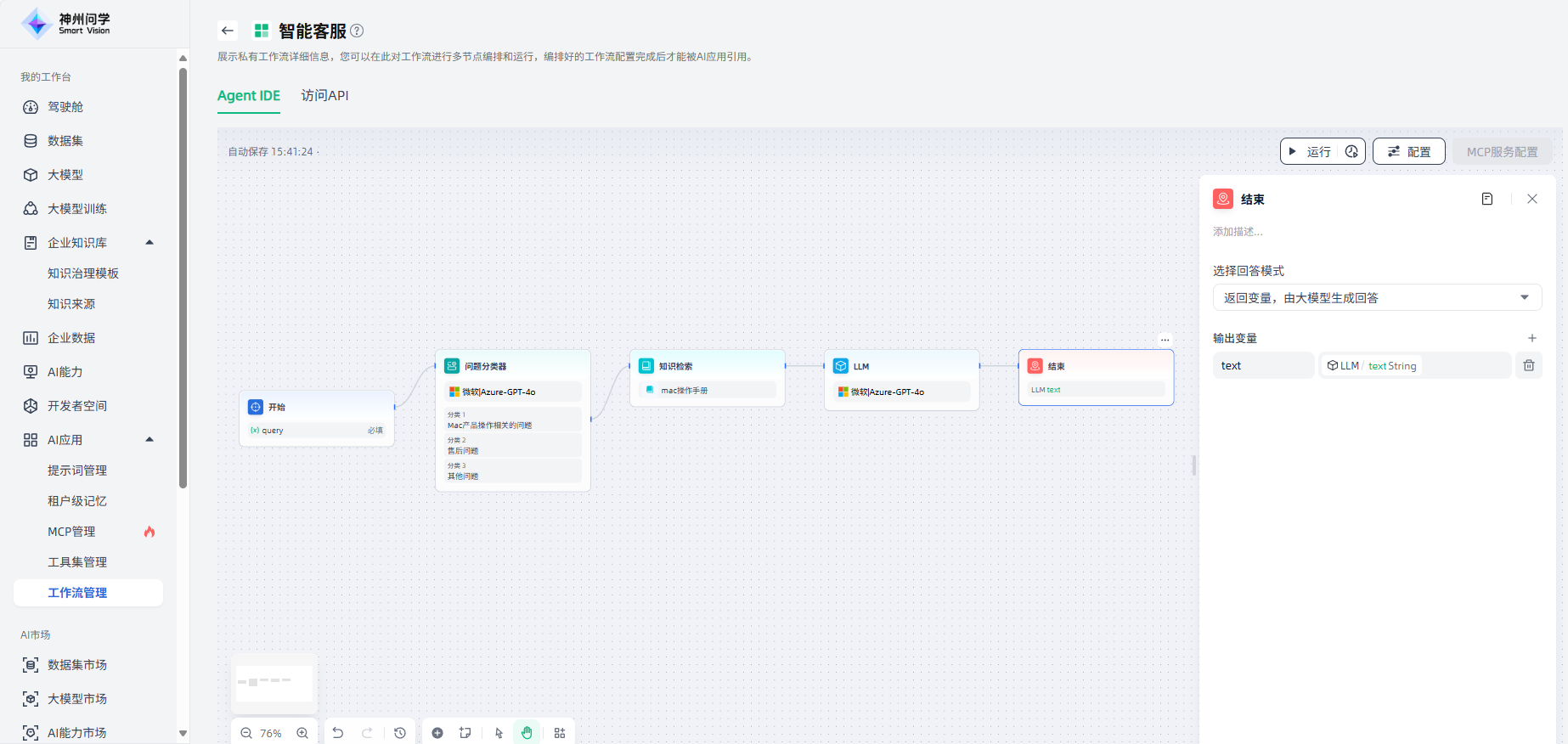
对于分类二售后问题,同样添加知识检索节点,便于针对此类问题通过相应知识库检索进行查询、并最终输出。
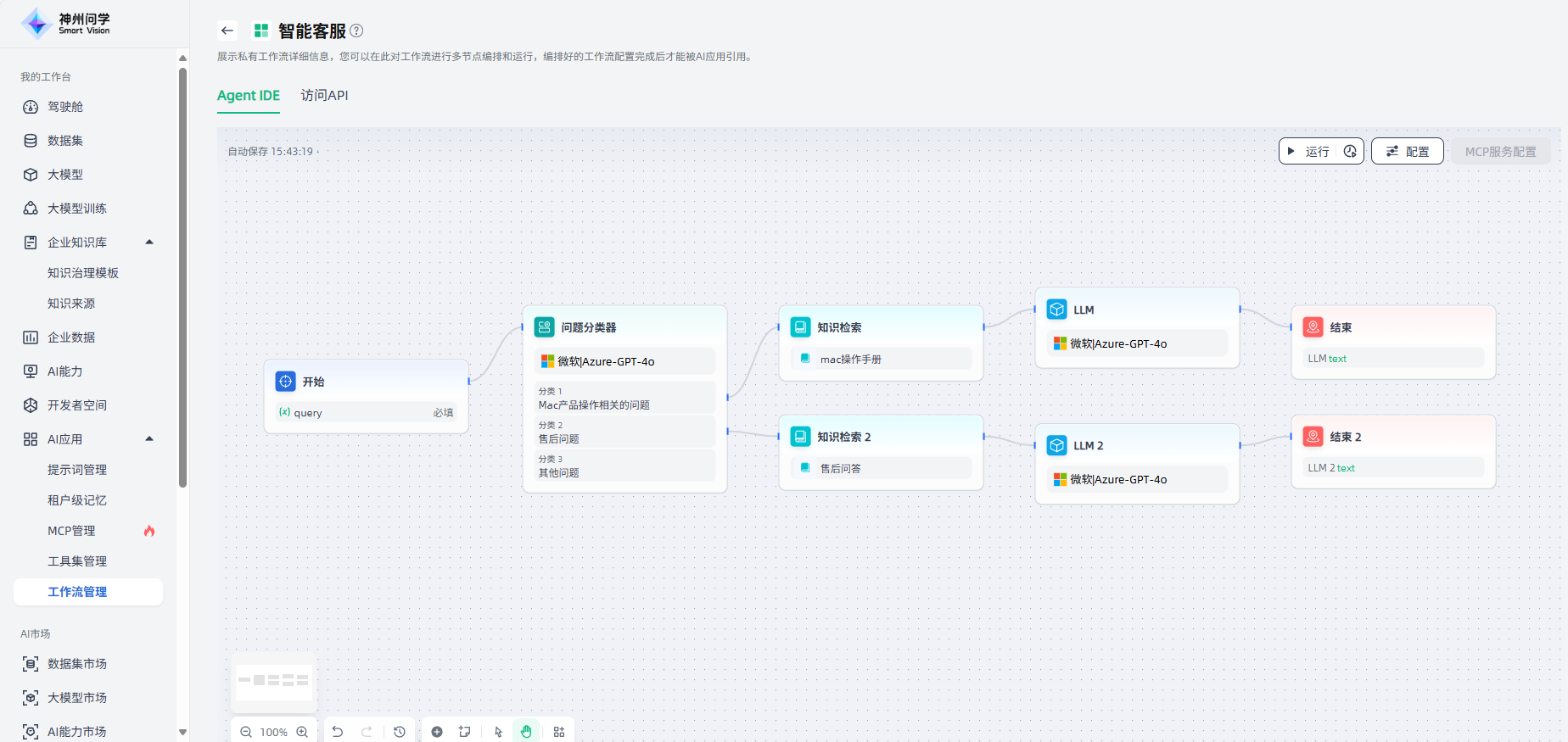
此外,我们也可以通过添加一个“变量聚合器”节点,来整合分类一、分类二两个分支的结果。这样可以帮助我们简化数据流管理,避免两个分支在不同的知识库检索后,需要对下游节点进行重复定义。
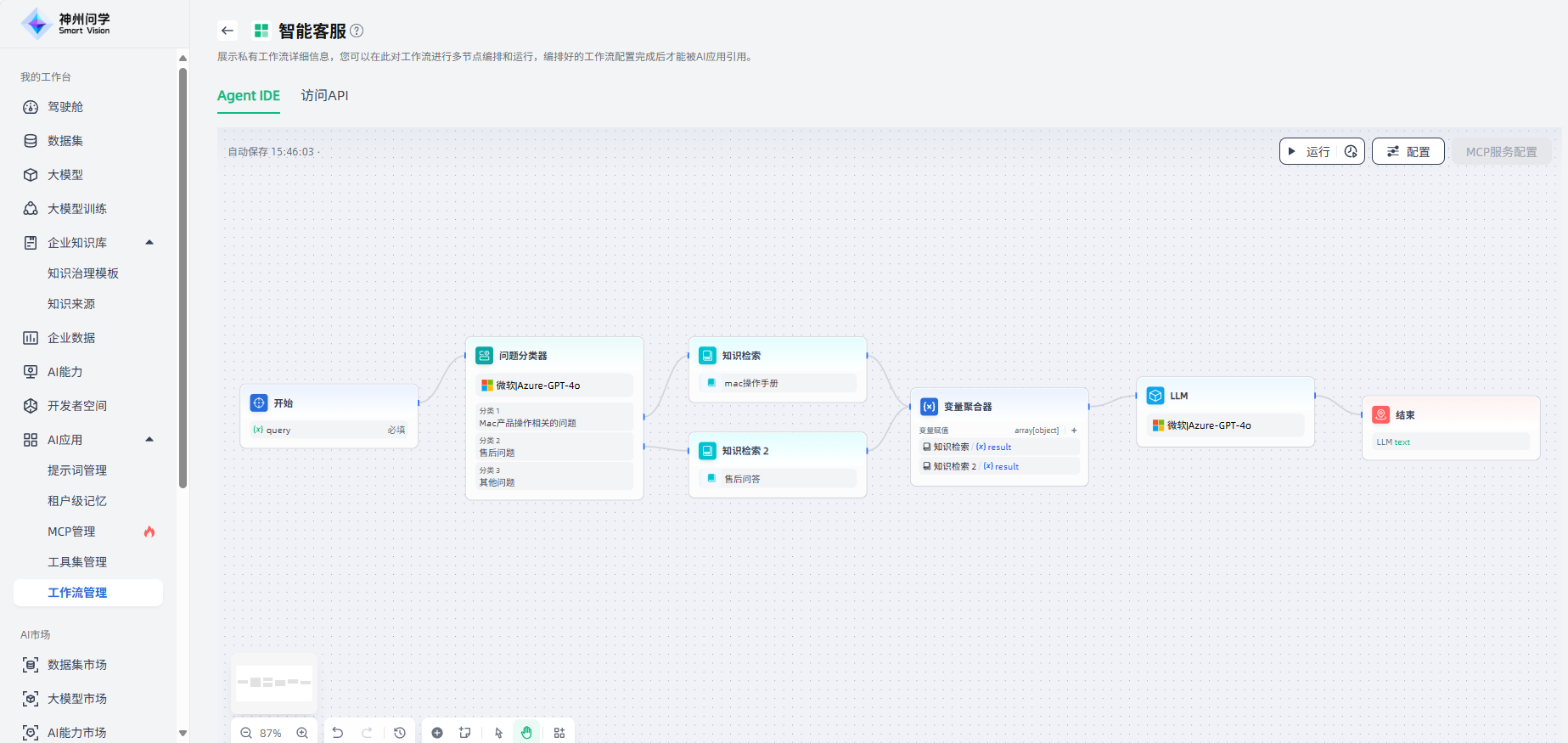
对于分类三"其他问题",如果没有专门的处理方案,可以直接添加“结束”节点,结束此流程。至此,这个智能客服场景的工作流编排完成。
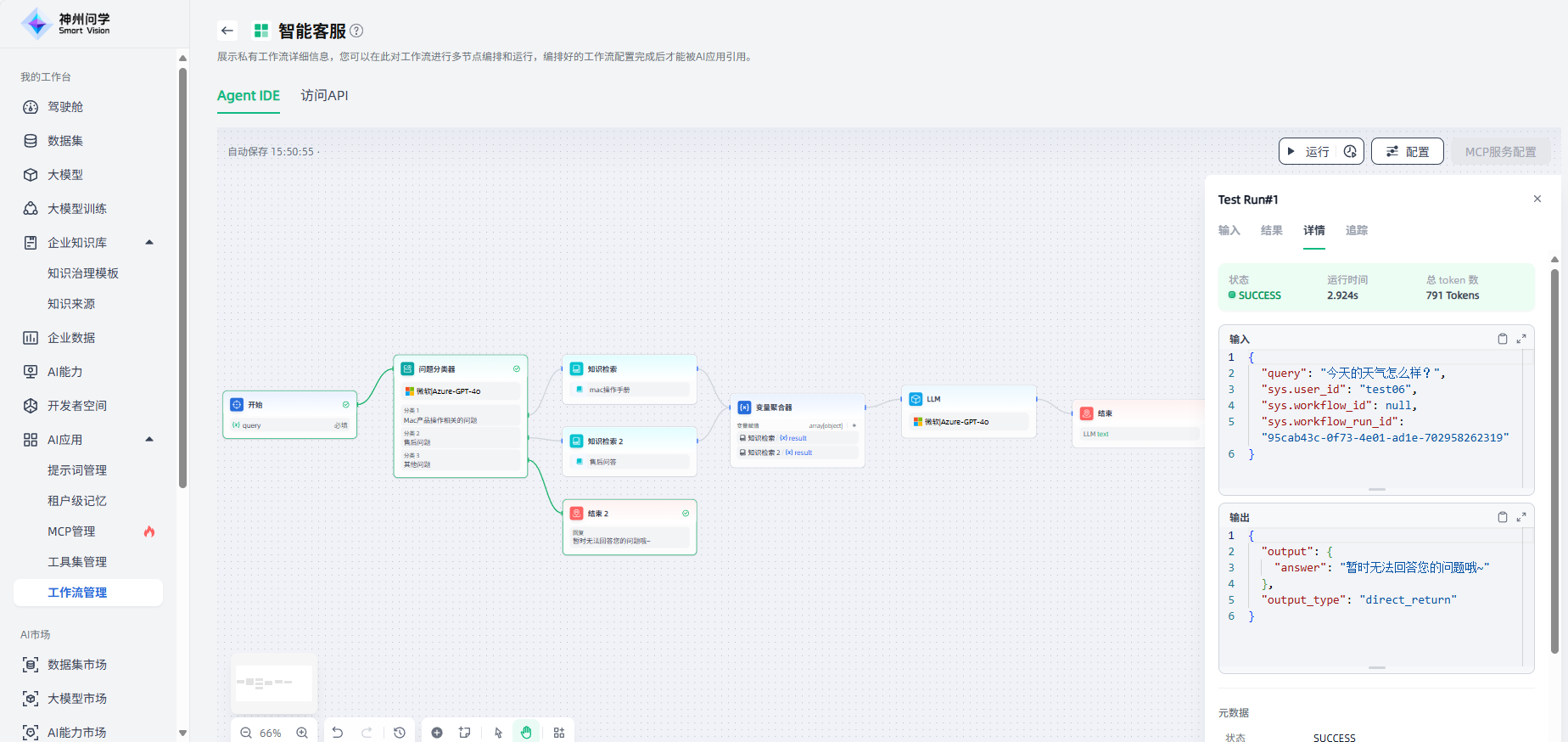
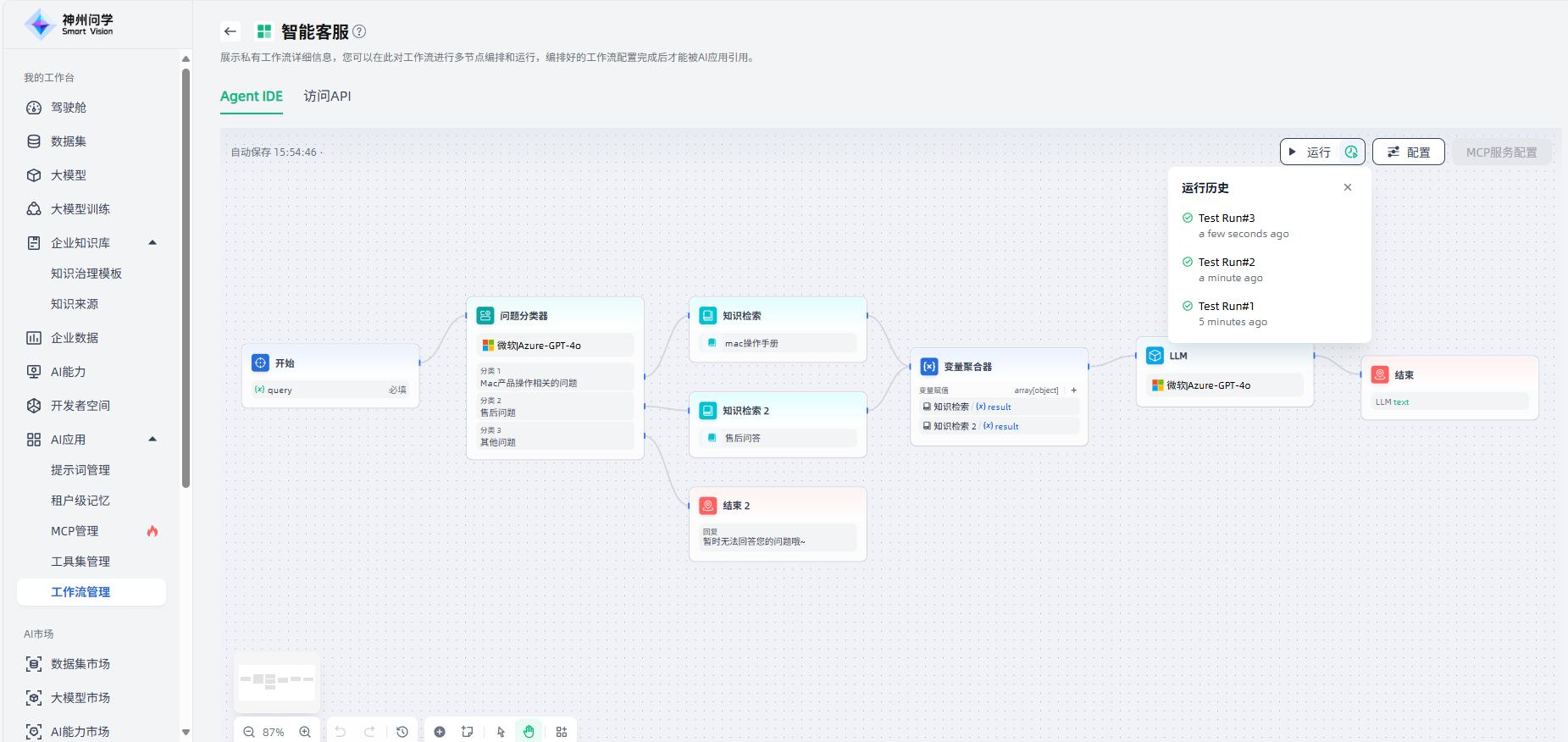
运行调试:工作流编排完成后,点击画布右上角“运行”按钮,可以查看工作流的运行结果,并支持查看详情、过程追踪,便于您对工作流进行调试与预览。对于运行中的工作流,支持实时终止干预,实现任务进程精准阻断。支持查看运行历史及历史详情,便于追溯问题根源与执行过程,助力高效排查与优化决策。
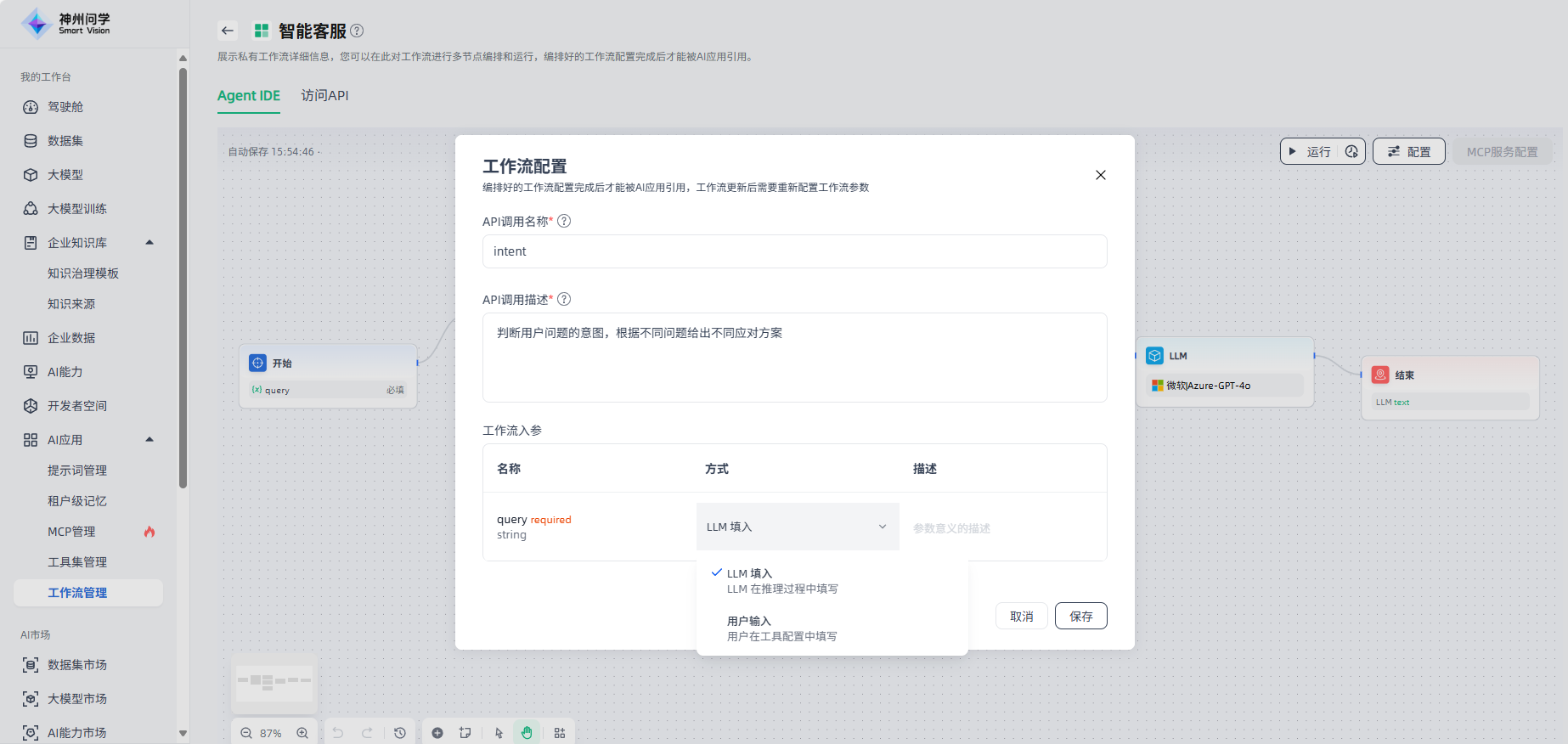
工作流配置:配置完成的工作流方可在AI应用中添加引用,点击画布右上角“配置”按钮,进行工作流配置。注意,此处的API调用名称和描述是用于机器/模型识别和理解的,不同于工作流创建时填写的名称和描述。此外,工作流入参支持两种方式:①LLM填入:默认方式,由LLM智能提取入参传入至工作流;②用户输入:如选择用户输入,需要在AI应用编排时设置传入至工作流的参数内容。
配置完成的工作流,其状态会变为“已配置”,并会在我的工作台-AI应用-工作流管理-已配置中进行展示,可以在AI应用编排时被添加引用。
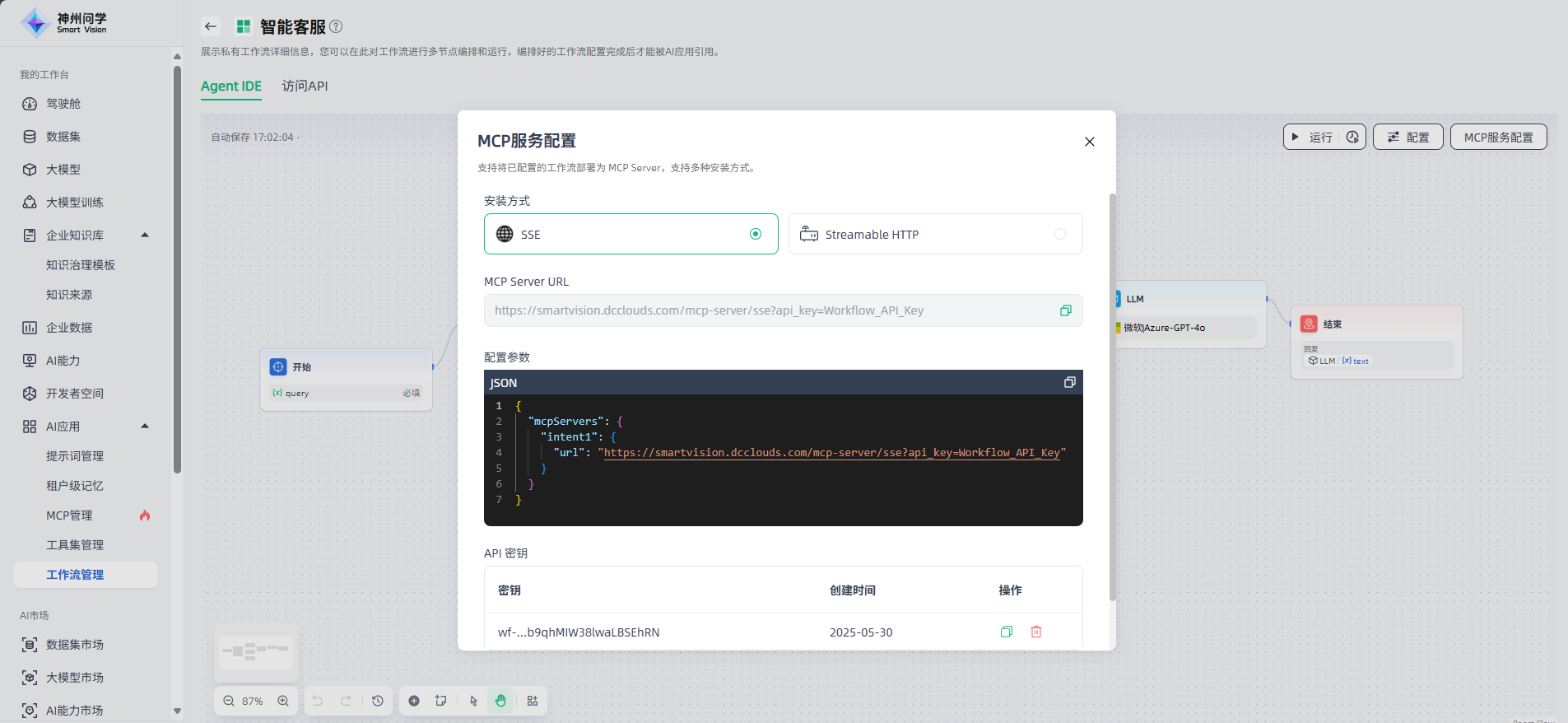
工作流配置完成后,点击“MCP服务配置”,可获取将此工作流配置为MCP服务所需的参数信息。用户通过复制工作流的MCP服务配置参数、创建密钥,可在工作台-AI应用-MCP管理-创建MCP服务中,将此工作流搭建成MCP服务,便于部署使用。
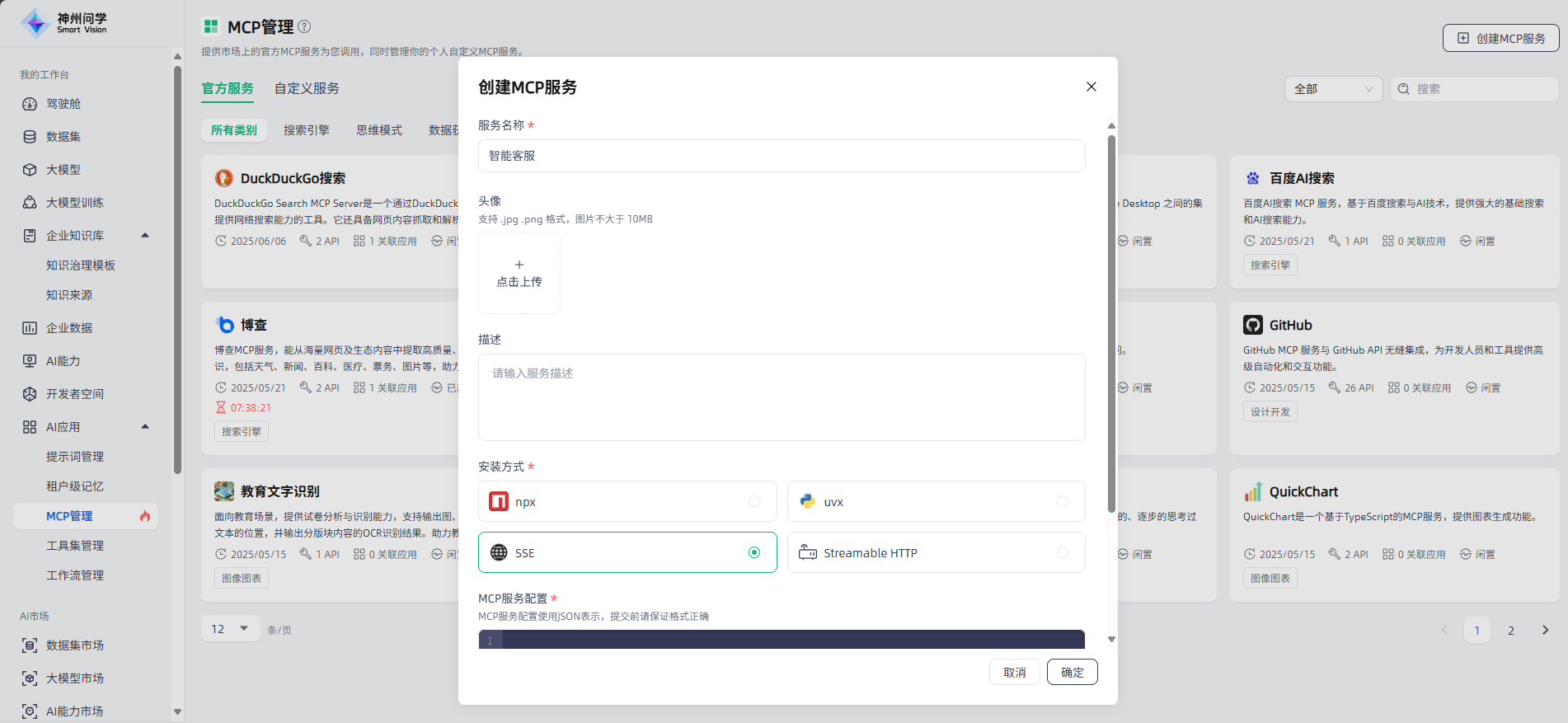
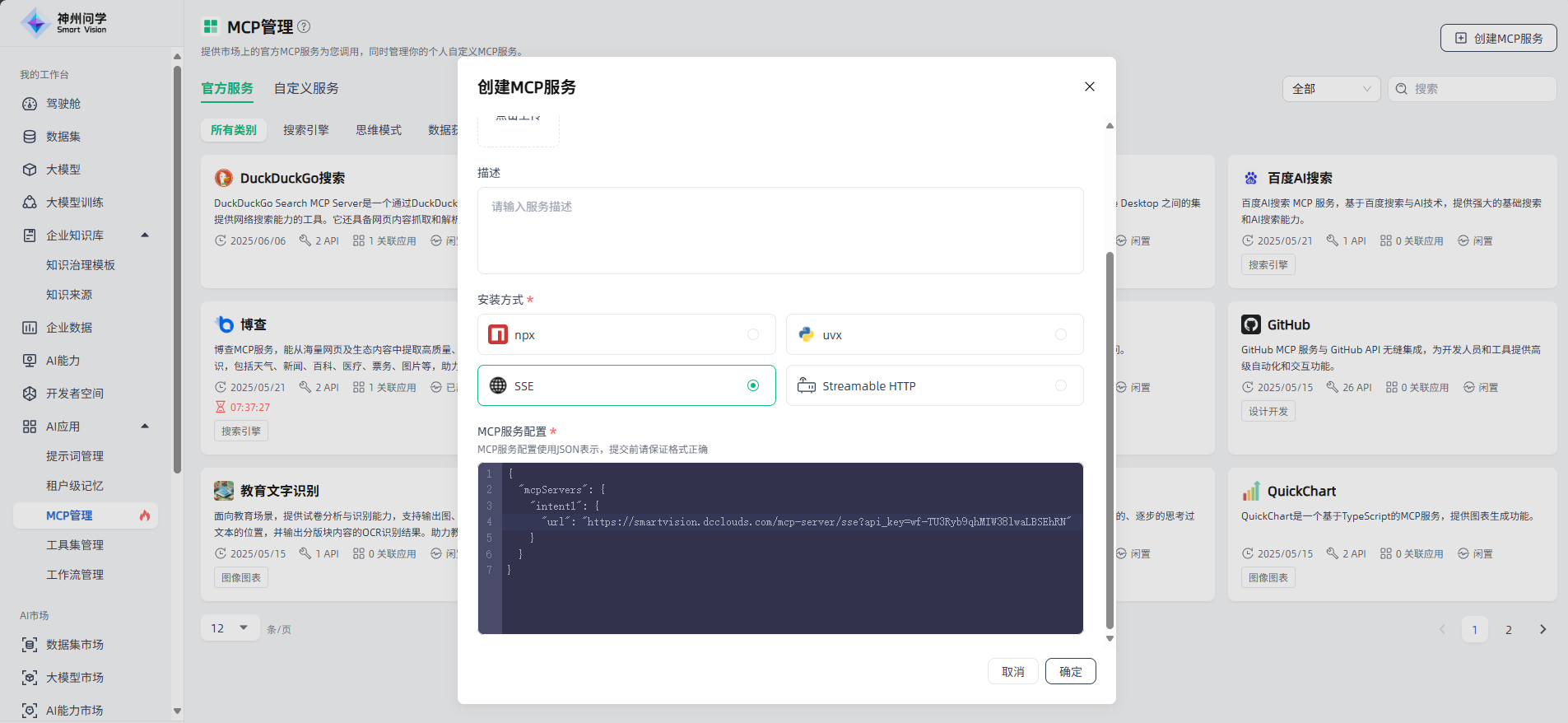
导入工作流
在我的工作台-AI应用-工作流管理,点击右上角的“导入工作流”按钮,可以直接导入已有的工作流文件,导入后的工作流会在“我的工作流”进行展示,便于您直接配置使用或在其基础上进行调整。
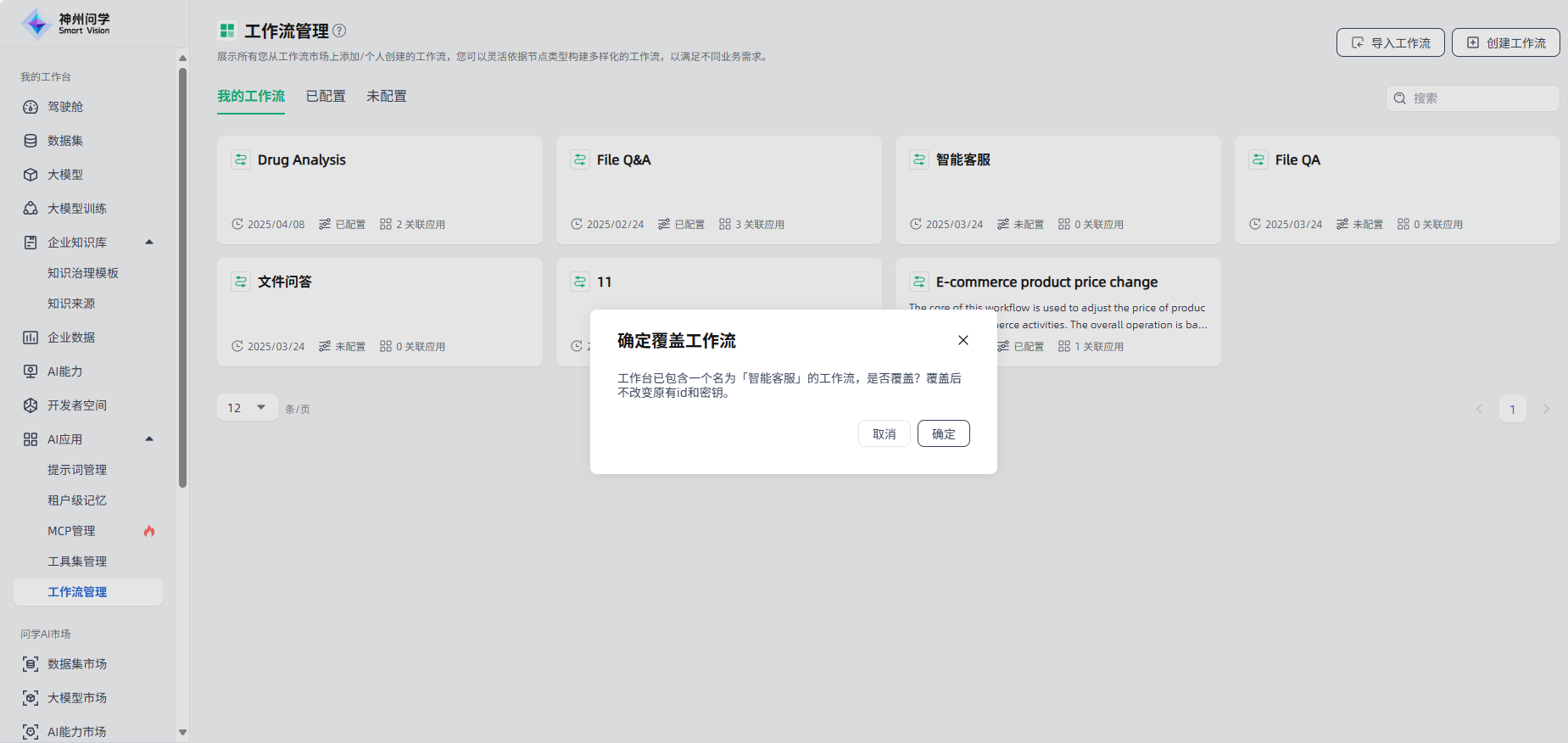
导入新的工作流时,如名称与工作台中已有工作流的名称重复,支持覆盖原有同名工作流,并保留原有工作流的API Key。
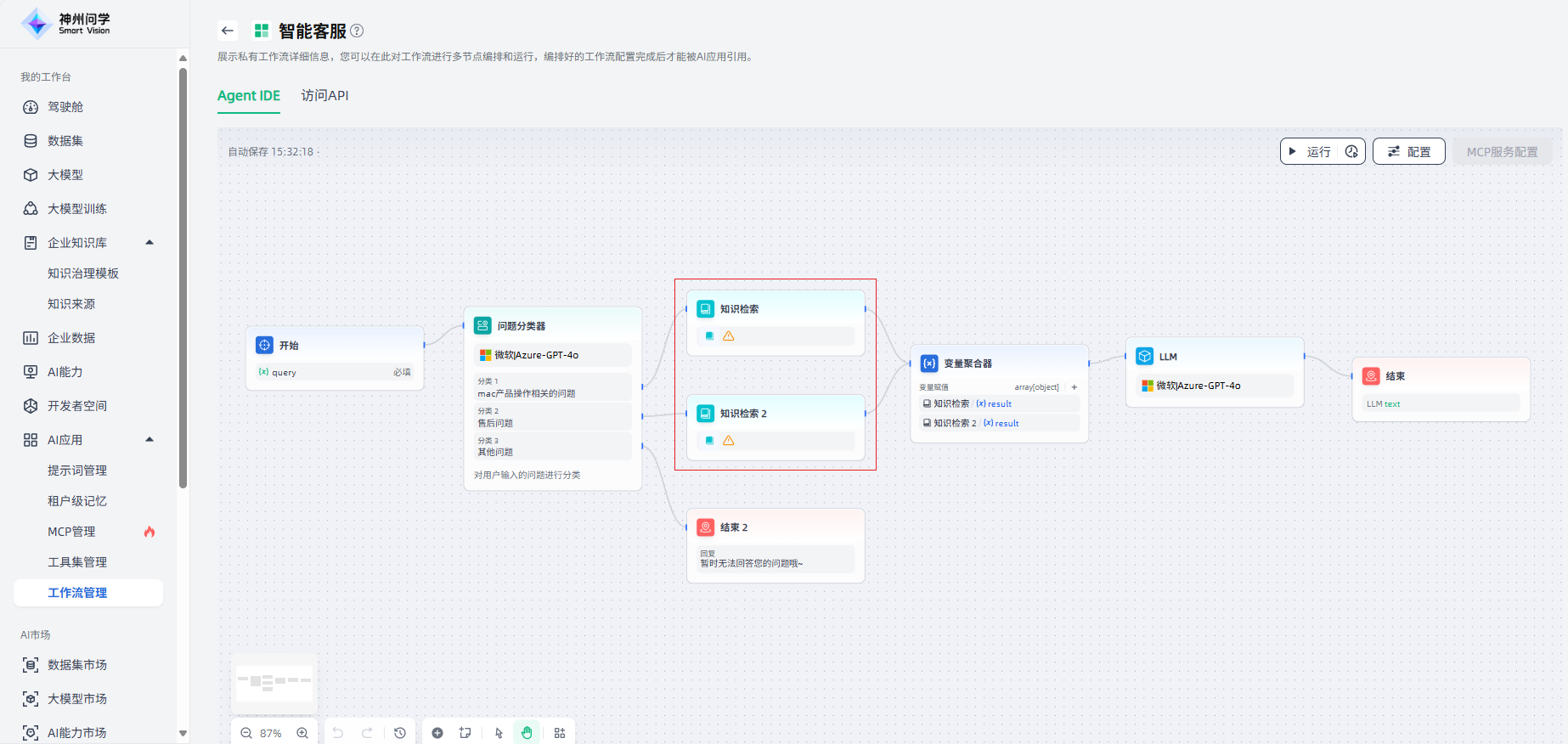
导入新的工作流后,会检测工作台是否包含新工作流运行所依赖的大模型/知识库/工具等,并在工作流详情页进行错误提示,保障您的使用体验。
访问API
点击“访问API”Tab页,可查看工作流的API访问方式。工作流访问API支持授权密钥管理,需要使用API密钥才能调用API(点击“API密钥”按钮,创建API密钥)。